[논문 리뷰] TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
Introduces Dual Dynamic Token Mixer (D-Mixer) to jointly capture global and local information for vision backbones, yielding TransXNet with superior accuracy and efficiency across classification, detection, and segmentation.
Recent studies have integrated convolutions into transformers to introduce inductive bias and improve generalization performance. However, the static nature of conventional convolution prevents it from dynamically adapting to input variations, resulting in a representation discrepancy between convolution and self-attention as the latter computes attention maps dynamically. Furthermore, when stacking token mixers that consist of convolution and self-attention to form a deep network, the static nature of convolution hinders the fusion of features previously generated by self-attention into convolution kernels. These two limitations result in a sub-optimal representation capacity of the entire network. To find a solution, we propose a lightweight Dual Dynamic Token Mixer (D-Mixer) to simultaneously learn global and local dynamics via computing input-dependent global and local aggregation weights. D-Mixer works by applying an efficient global attention module and an input-dependent depthwise convolution separately on evenly split feature segments, endowing the network with strong inductive bias and an enlarged receptive field. We use D-Mixer as the basic building block to design TransXNet, a novel hybrid CNN-Transformer vision backbone network that delivers compelling performance. In the ImageNet-1K classification, TransXNet-T surpasses Swin-T by 0.3% in top-1 accuracy while requiring less than half of the computational cost. Furthermore, TransXNet-S and TransXNet-B exhibit excellent model scalability, achieving top-1 accuracy of 83.8% and 84.6% respectively, with reasonable computational costs. Additionally, our proposed network architecture demonstrates strong generalization capabilities in various dense prediction tasks, outperforming other state-of-the-art networks while having lower computational costs. Code is publicly available at https://github.com/LMMMEng/TransXNet.
연구 동기 및 목표
- Motivate hybrid CNN-Transformer backbones to overcome static convolution bottlenecks by introducing input-dependent dynamics.
- Design a lightweight token mixer that integrates global and local information to enlarge effective receptive field (ERF).
- Build a hierarchical backbone (TransXNet) using D-Mixer and MS-FFN for visual recognition tasks.
- Show that TransXNet achieves state-of-the-art or competitive results with lower computational cost across classification, detection, and segmentation.
- Provide ablations and transferability analysis to validate components and generalization.
제안 방법
- Propose a Dual Dynamic Token Mixer (D-Mixer) that splits features into two channel halves processed by OSRA (global) and IDConv (input-dependent local) and then concatenates results.
- Introduce Input-dependent Depthwise Convolution (IDConv) to generate input-adaptive, spatially varying depthwise kernels.
- Introduce Overlapping Spatial Reduction Attention (OSRA) to capture global context with overlapping patches.
- Add Squeezed Token Enhancer (STE) to efficiently fuse channel information after token mixing.
- Incorporate Multi-scale Feed-forward Network (MS-FFN) with parallel depthwise convolutions of sizes {3,5,7} for multi-scale token aggregation.
- Provide four-stage hierarchical architecture with DPE layering, D-Mixer blocks, and MS-FFN blocks to form TransXNet variants (T, S, B).
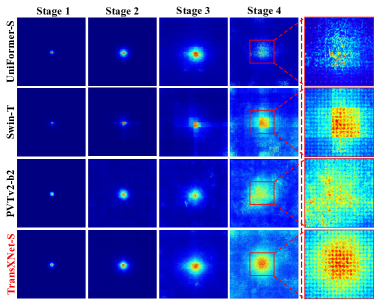
실험 결과
연구 질문
- RQ1Do input-dependent dynamics via D-Mixer improve representation capacity and generalization compared to static convolutions in hybrid CNN-Transformer backbones?
- RQ2Can global attention across stages together with dynamic local convolution enlarge the receptive field and improve performance on vision tasks?
- RQ3How do D-Mixer components (OSRA, IDConv, STE) and MS-FFN contribute to performance on ImageNet-1K and downstream tasks (COCO, ADE20K)?
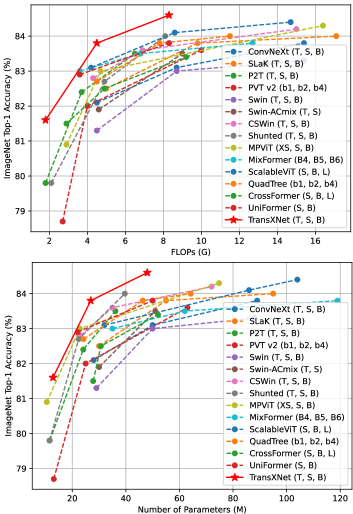
- RQ4What are the accuracy-cost trade-offs of TransXNet variants (T, S, B) relative to contemporary SOTA backbones?
- RQ5Do the gains transfer effectively to object detection, instance and semantic segmentation without specialized implementations?
주요 결과
- TransXNet-T achieves 81.6% top-1 accuracy on ImageNet-1K with 1.8G FLOPs and 12.8M params, surpassing Swin-T by 0.3% while using less than half the cost.
- TransXNet-S achieves 83.8% top-1 on ImageNet-1K with competitive FLOPs and parameters, outperforming InternImage-T and several hybrid models at lower cost.
- TransXNet-B attains 84.6% top-1 on ImageNet-1K with 8.3G FLOPs and 48.0M params, delivering strong accuracy-cost balance and outperforming comparable backbones.
- On ImageNet-1K-V2, TransXNet variants show better generalization and transferability, with explicit gains in tiny/small/base configurations.
- In COCO object detection and Mask R-CNN segmentation, TransXNet backbones outperform peers at similar compute, especially in medium/large objects, demonstrating strong global-local dynamics advantages.
- On ADE20K semantic segmentation, TransXNet-T/S/B achieve mIoU of 45.5%/48.5%/49.9% respectively, with competitive or lower FLOPs compared to baselines.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.