[논문 리뷰] Tree of Thoughts: Deliberate Problem Solving with Large Language Models
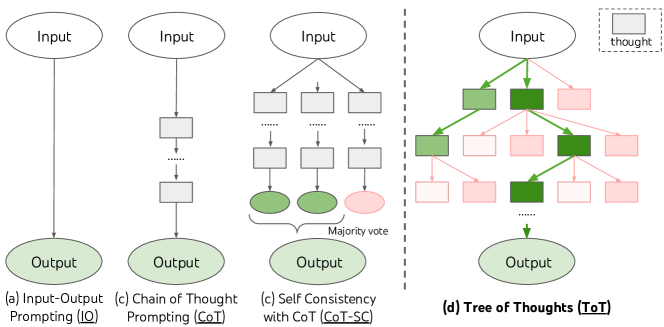
Tree of Thoughts (ToT)는 중간 생각에 대한 트리 구조의 의도적 탐색으로 언어 모델을 보강하여, 체인-오브-생각 프롬프트를 넘어서는 추론과 계획이 필요한 작업을 해결하기 위한 계획 및 되돌리기를 가능하게 한다.
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.
연구 동기 및 목표
- 좌우로 순차적으로 토큰을 생성하는 것을 넘어서 LLM에서 의도적이고 트리 구조의 문제 해결 필요성을 동기 부여한다.
- 중간 생각의 트리를 유지하고 이를 탐색하기 위해 탐색 알고리즘을 사용하는 Tree of Thoughts (ToT) 프레임워크를 소개한다.
- 도전적인 작업들(게임 오브 24, 창의적 글쓰기, 미니 크로스워드)에서 ToT를 시연하고 IO 프롬프팅, CoT 및 CoT-SC와 비교한다.
- ToT가 더 높은 성공률을 달성하고 추가 훈련 없이도 모듈식이며 적응 가능한 구성 요소를 제공함을 보인다.
제안 방법
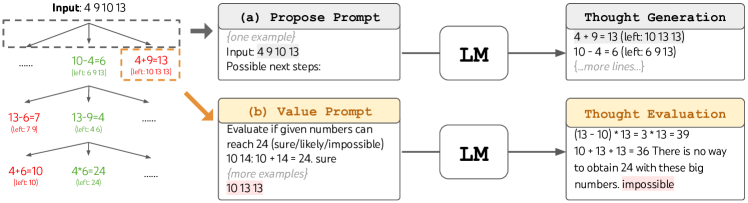
- 문제 해결을 각 노드가 부분 해 상태인 생각의 트리로 분해한다.
- 상태로부터 다음 생각을 생성하는 방법으로 CoT 프롬프트에서 i.i.d. 샘플링을 사용하거나 더 제약된 공간을 위한 제안 프롬프트를 사용한다.
- 탐색을 유도하기 위해 LM 기반 평가 프롬프트나 투표 프롬프트를 통해 의도적인 휴리스틱으로 프런티어 상태를 평가한다.
- 탐구의 폭과 깊이 한계를 구성 가능하게 하여 생각 트리에 대해 BFS나 DFS 탐색을 적용한다.
- 평가된 휴리스틱에 따라 상위 상태를 선택하고 되돌리기를 허용하는 ToT-BFS 및 ToT-DFS 알고리즘을 구현한다.
실험 결과
연구 질문
- RQ1표준 프롬프트를 넘어 계획, 탐색 및 되돌리기가 필요한 작업에서 ToT가 문제 해결을 향상시킬 수 있는가?
- RQ2다양한 생각 생성 및 평가 전략이 서로 다른 문제 영역에서 ToT 성능에 어떤 영향을 미치는가?
- RQ3ToT 프레임워크에서 BFS 대 DFS를 사용하는 것이 해법의 질과 효율성에 어떤 영향을 미치는가?
- RQ4도전적인 추론 작업에서 ToT가 IO 프롬프팅, Chain-of-Thought 프롬프팅, 및 CoT-SC와 어떻게 비교되는가?
주요 결과
| Method | Success Rate (%) |
|---|---|
| IO prompt | 7.3 |
| CoT prompt | 4.0 |
| CoT-SC (k=100) | 9.0 |
| ToT (b=1) | 45 |
| ToT (b=5) | 74 |
| IO + Refine (k=10) | 27 |
| IO (best of 100) | 33 |
| CoT (best of 100) | 49 |
- ToT는 IO, CoT, CoT-SC에 비해 세 가지 도전적인 작업에서 성능을 크게 향상시킨다.
- Game of 24에서 b=1인 ToT는 45%의 성공률, b=5에서 74%의 성공률을 달성하며, IO, CoT, CoT-SC의 각각은 각각 7.3%, 4.0%, 9.0%이다.
- 창의적 글쓰기 실험에서 ToT가 평균 일관성 점수에서 더 높게 나타나 (ToT 7.56 vs IO 6.19 및 CoT 6.93) 다수의 쌍에서 사람들은 ToT 출력물을 선호한다.
- 미니 크로스워드 결과는 ToT가 단어 수준 및 게임 수준 지표에서 IO 및 CoT를 크게 능가하며, 표준 설정에서 단어 수준 성공 60%에 이르고 20개 게임 중 4개를 해결했다.
- 단순한 오라클-최고 상태 비성능 분석 및 가지치기/되돌리기 분석은 더 나은 상태 평가 및 DFS 휴리스틱을 통한 개선 여지가 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.