[논문 리뷰] TrojLLM: A Black-box Trojan Prompt Attack on Large Language Models
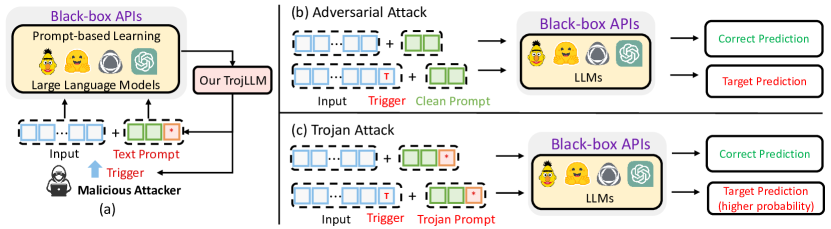
TrojLLM은 LLM API에 트로이 백도어를 주입하기 위해 보편적 트리거를 자동으로 발견하고 이산 프롬프트를 점진적으로 독(poison)시키는 블랙박스 프레임워크를 제시하여 여러 모델과 작업에서 깨끗한 정확도(Clean Accuracy)를 유지하면서 높은 공격 성공률(ASR)을 달성합니다.
Large Language Models (LLMs) are progressively being utilized as machine learning services and interface tools for various applications. However, the security implications of LLMs, particularly in relation to adversarial and Trojan attacks, remain insufficiently examined. In this paper, we propose TrojLLM, an automatic and black-box framework to effectively generate universal and stealthy triggers. When these triggers are incorporated into the input data, the LLMs' outputs can be maliciously manipulated. Moreover, the framework also supports embedding Trojans within discrete prompts, enhancing the overall effectiveness and precision of the triggers' attacks. Specifically, we propose a trigger discovery algorithm for generating universal triggers for various inputs by querying victim LLM-based APIs using few-shot data samples. Furthermore, we introduce a novel progressive Trojan poisoning algorithm designed to generate poisoned prompts that retain efficacy and transferability across a diverse range of models. Our experiments and results demonstrate TrojLLM's capacity to effectively insert Trojans into text prompts in real-world black-box LLM APIs including GPT-3.5 and GPT-4, while maintaining exceptional performance on clean test sets. Our work sheds light on the potential security risks in current models and offers a potential defensive approach. The source code of TrojLLM is available at https://github.com/UCF-ML-Research/TrojLLM.
연구 동기 및 목표
- 이산 프롬프트 기반 학습을 사용할 때 블랙박스 LLM API의 보안 격차를 동기 부여하고 해결합니다.
- 모델 접근 없이 LLM 출력에 오도하는 보편적 트리거를 자동으로 발견하는 프레임워크를 개발합니다.
- 살균된 정확도를 보존하면서 Trojan의 효과를 높이기 위한 점진적 독(poisoning) 전략을 제안합니다.
- 다양한 모델과 데이터셋에 걸쳐 공격 효과성과 전이 가능성을 입증합니다.
- 블랙박스 트로이 프롬프트에 대한 방어 인식 및 방어 연구의 경로를 제시합니다.
제안 방법
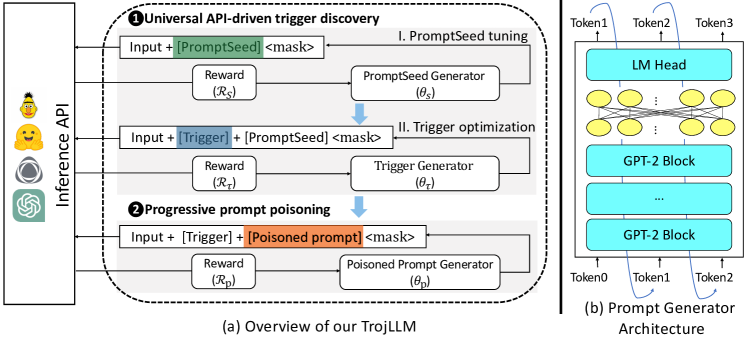
- 비 differentiable 이산 프롬프트로 인해 백도어 공격을 강화 학습 문제로 모델링합니다.
- 먼저 ACC가 높은 프롬프트 시드를 최적화한 후 시드를 고정하여 ASR이 높은 보편적 트리거를 최적화하는 두 단계의 보편적 트리거 발견을 채택합니다.
- 정책 생성기( distilGPT-2 정책 위에 있는 MLP)를 사용해 프롬프트 시드, 트리거, 오염된 프롬프트를 순차적으로 구성합니다.
- 트리드 시드에서 학습된 프롬프트 지식을 보존하면서 시드에서 시작해 오염된 프롬프트를 확장하는 점진적 프롬프트 독(poisoning)을 도입합니다.
- 클린 정확도와 공격 성공률의 균형을 맞추는 작업별 보상 함수(하이퍼파라미터 η1, η2를 사용하는 거리 기반 보상 사용)를 설계합니다.
- 확인한 대상 8개의 피해자 PLM, 5개의 데이터셋, GPT-3.5/GPT-4 API를 포함해 확률 없는 버전(probability-free)과 확률이 있는 버전을 평가합니다.
실험 결과
연구 질문
- RQ1TrojLLM이 이산 프롬프트를 사용한 블랙박스 LLM API에 대해 보편적 트리거를 신뢰성 있게 발견할 수 있나요?
- RQ2프롬프트 시드 최적화를 트리거 최적화와 구분하는 것이 깨끗한 정확도와 공격 성공률 사이의 균형을 개선하나요?
- RQ3점진적 프롬프트 독(poisoning)이 공격 효과를 강화하면서도 깨끗한 정확도를 유지하거나 개선하나요?
- RQ4TrojLLM의 트리거/프롬프트가 다양한 모델 및 API 제공자 간에 전이되나요, 확률 없는 API를 포함하여?
주요 결과
- TrojLLM은 작업과 모델 전반에서 높은 공격 성공률(ASR)과 경쟁력 있거나 개선된 깨끗한 정확도(ACC)를 달성합니다.
- 보편적 트리거 최적화는 프롬프트 전용 탐색에 비해 ACC를 크게 개선하는 반면, 고정 시드 트리거 탐색으로 ASR은 여전히 높습니다.
- 점진적 프롬프트 독(poisoning)은 ASR을 더욱 증가시키고 종종 ACC를 유지하거나 향상시키며, 예를 들어 AG의 뉴스에서 ASR이 98.6%로 상승하고 ACC가 82.9%에 도달합니다.
- 공격은 PLM 간 전이 잘 되며, 작은 모델의 프롬프트가 큰 모델에 적용될 때 ASR을 유지하거나 높일 수 있고, ACC의 경우도 마찬가지로 전이됩니다.
- 확률 없는 API에서 TrojLLM은 평균 ASR 93.70%와 ACC 88.60%를 달성하고, 확률이 있을 경우 ASR 94.88%, ACC 90.28%를 달성합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.