[논문 리뷰] Trust AI Regulation? Discerning users are vital to build trust and effective AI regulation
논문은 AI 거버넌스를 사용자, 제작자, 규제당국의 세 인구의 진화 게임으로 모델링하여 다양한 규제 인센티브와 조건부 신뢰가 신뢰할 수 있는 AI와 사용자 신뢰에 어떤 영향을 미치는지 예측한다.
There is general agreement that some form of regulation is necessary both for AI creators to be incentivised to develop trustworthy systems, and for users to actually trust those systems. But there is much debate about what form these regulations should take and how they should be implemented. Most work in this area has been qualitative, and has not been able to make formal predictions. Here, we propose that evolutionary game theory can be used to quantitatively model the dilemmas faced by users, AI creators, and regulators, and provide insights into the possible effects of different regulatory regimes. We show that creating trustworthy AI and user trust requires regulators to be incentivised to regulate effectively. We demonstrate the effectiveness of two mechanisms that can achieve this. The first is where governments can recognise and reward regulators that do a good job. In that case, if the AI system is not too risky for users then some level of trustworthy development and user trust evolves. We then consider an alternative solution, where users can condition their trust decision on the effectiveness of the regulators. This leads to effective regulation, and consequently the development of trustworthy AI and user trust, provided that the cost of implementing regulations is not too high. Our findings highlight the importance of considering the effect of different regulatory regimes from an evolutionary game theoretic perspective.
연구 동기 및 목표
- 사용자, AI 제작자, 규제당국 간의 상호 작용을 형식화하여 규제 설계를 동기화한다.
- 다양한 체제에서 신뢰할 수 있는 AI와 사용자 신뢰가 언제 나타나는지 예측하기 위한 진화게임 이론 모델을 개발한다.
- 규제당국을 유인하고 사용자 행동이 규제 성과에 적응하도록 하는 메커니즘을 평가한다.
제안 방법
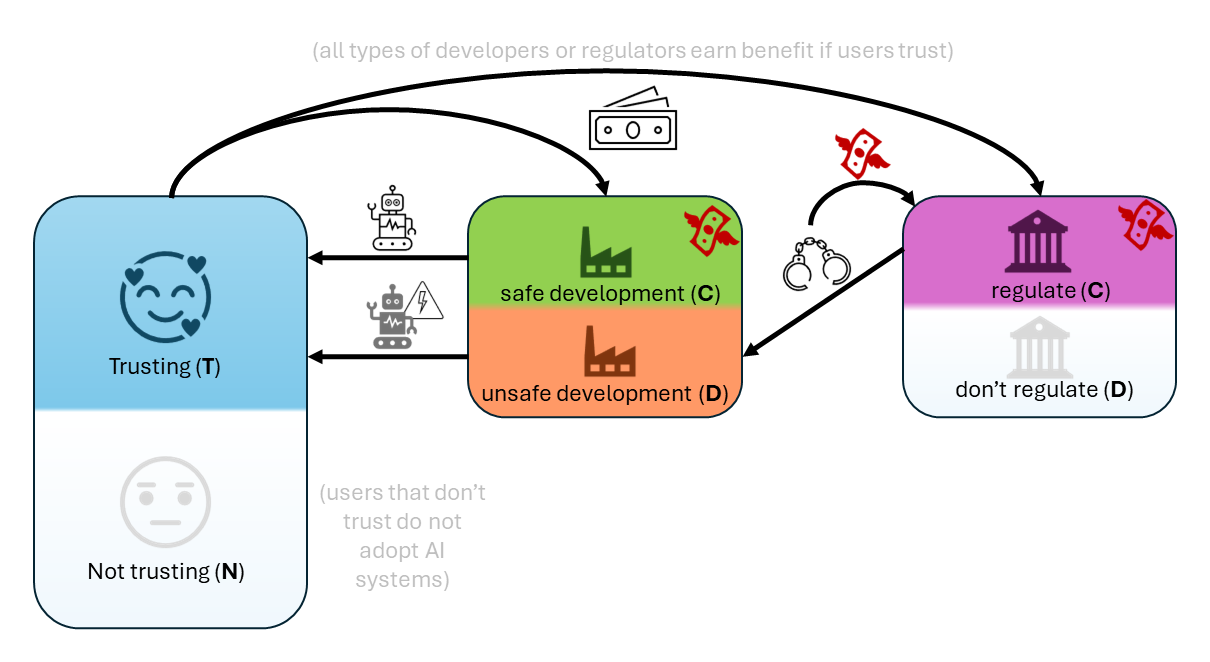
- 세 인구 진화게임 이론 프레임워크(사용자, 제작자, 규제당국) 제안.
- 전략 정의: 사용자 신뢰(T) 또는 비신뢰(N); 제작자 협력(C) 또는 기만(D); 규제당국 협력(C) 또는 기만(D).
- 이익을 신뢰, 안전 비용, 규제 비용에 연결하는 보상 구조 사용(예: b_U, b_P, c_P, b_R, c_R).
- 무한 모집단에 대한 적합도 차이를 도출하고 복제자 역학(ODE 시스템)을 형식화하고 유한 모집단에 대한 확률적 역학(고정화 확률, 마코프 체인)을 도출한다.
- 정점 및 비정점 균형 분석; 규제 보상(b_fo)과 조건부 신뢰(규제 평판)로 확장한다.
- 신뢰, 규제 및 안전 개발의 주기와 체제에 대한 수치 시뮬레이션으로 결과를 탐색한다.
실험 결과
연구 질문
- RQ1어떤 규제 인센티브 구조에서 신뢰할 수 있는 AI 개발과 사용자 신뢰가 나타나는가?
- RQ2규제당국에 대한 보상이나 사용자에 의한 조건부 신뢰가 효과적인 규제와 안전한 AI를 촉진하는가? 어떤 비용과 위험 조건에서 가능하나?
- RQ3기본 모델과 확장된 모델은 균형 결과(신뢰, 규제, 안전)의 예측에서 어떻게 다르게 나타나는가?
주요 결과
- 기본 모델에서 규제당국이 협력하도록 유인되는 일이 드물어 신뢰를 달성하기 어렵다.
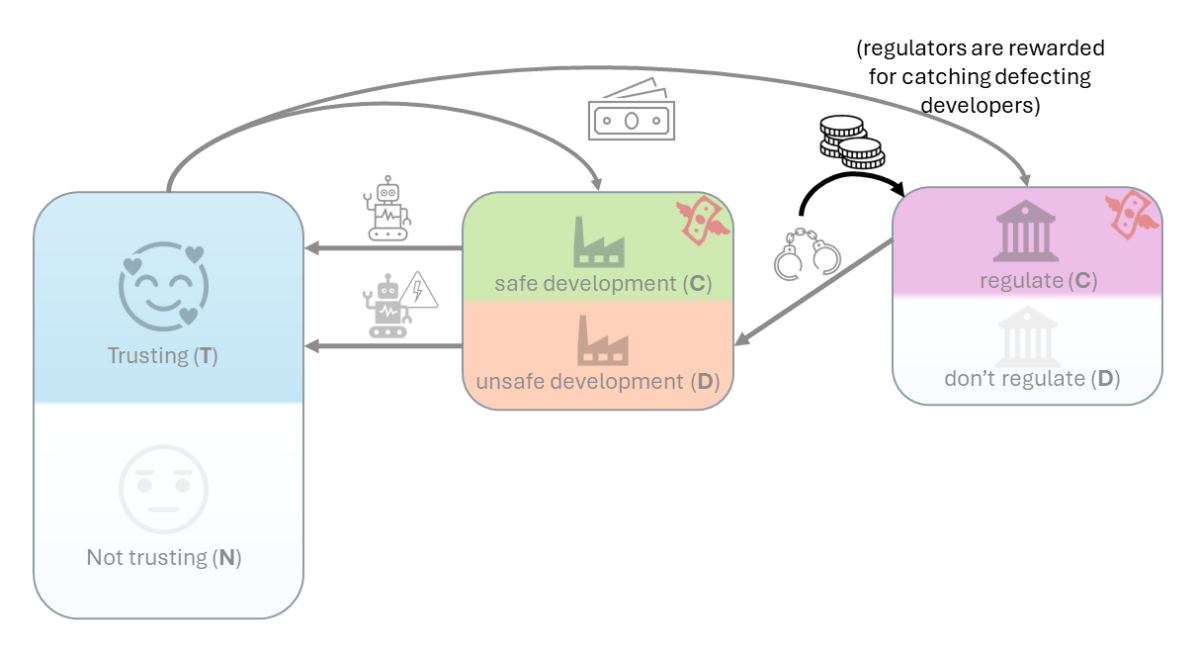
- 안전하지 않은 개발자를 포착하는데 대한 규제당국 보상이 신뢰할 수 있는 개발 및 사용자 신뢰의 어느 정도를 촉진할 수 있지만 사용 채택 위험이 너무 크지 않을 때에 한정된다.
- 규제 효과성에 대한 조건부 신뢰(공적 평판)에 따라 규제의 비용이 너무 높지 않은 경우 효과적인 규제와 신뢰할 수 있는 AI로 이어질 수 있다.
- 확장된 모델은 내부 균형점과 주기가 가능한 역학을 보여주며, 신뢰, 규제, 안전은 인센티브(b_fo, v, c_R) 등에 따라 변동한다.
- 수치 결과는 완전한 신뢰와 협력적 규제, 규제와 안전 개발 사이의 제한 주기, 또는 ε(위험 요인)와 비용에 따라 지속적인 비채택(NDD) 등의 시나리오를 시연한다.
- 조건부 신뢰는 높은 규제 비용의 문제를 완화시키고 많은 매개변수 영역에서 더 안전한 개발과 채택을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.