[논문 리뷰] Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3는 데이터, 코드, 평가를 포함한 개방적이고 완전히 노출된 사후 학습 레시피를 제시하며, RLVR 및 기타 기법으로 70B에서 공개 가중치 동료 및 경쟁 폐쇄형 모델을 능가할 수 있음을 보여준다.
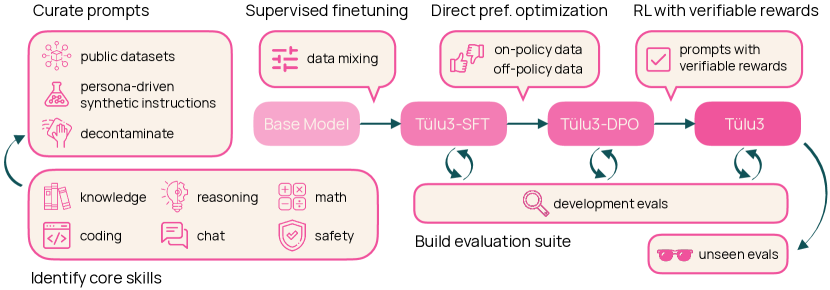
Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce Tulu 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. Tulu 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With Tulu 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the Tulu 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the Tulu 3 approach to more domains.
연구 동기 및 목표
- 독점 방법과의 격차를 해소하기 위한 완전히 개방된 사후 학습 프레임워크를 정의한다.
- 대형 LLM의 재현 가능한 사후 학습을 위한 개방 데이터셋, 평가 모음, 훈련 레시피를 제공한다.
- 개방형 사후 학습이 최첨단 개방 모델을 능가하고 일부 폐쇄형 모델의 기능에 근접할 수 있음을 입증한다.
- 여러 작업에 걸쳐 핵심 기술을 향상시키기 위한 새로운 학습 단계와 데이터 전략을 도입하고 검증한다.
제안 방법
- Tulu 3 데이터, 평가 및 코드 생태계를 설명한다.
- SFT, 직접 선호 최적화(DPO), 검증 가능한 보상으로 강화 학습(RLVR)을 포함한 다단계 학습 레시피를 제안한다.
- 진전 측정과 지도를 위한 광범위한 오염 제거 및 평가 도구를 개발한다.
- 온정책 선호 데이터와 검증 가능한 보상 신호를 사용하여 추론, 수학, 코딩 등 핵심 기술 개발을 최적화한다.
- 상대적 성능을 확립하기 위해 개방형 및 폐쇄형 모델과 벤치마크를 수행한다.
실험 결과
연구 질문
- RQ1동급의 개방 가중치 사후 학습 모델과 비교해도, 완전히 공개된 개방형 사후 학습 레시피가 현대의 동급 모델보다 우수할 수 있는가?
- RQ2RLVR이 수학 및 정확한 지시 이행과 같은 기술에서 확인 가능한 개선을 제공하는가?
- RQ3개발 중이거나 보지 못한 작업에서 핵심 기술을 가장 신뢰성 있게 향상시키는 데이터, 방법론 및 평가 관행은 무엇인가?
- RQ4오염 제거된 합성 및 선호 기반 데이터를 개방 인프라와 결합했을 때 폐쇄형 모델의 능력을 어느 정도까지 따라잡을 수 있는가?
- RQ5완전히 열린 사후 학습 파이프라인의 실질적인 설계 고려사항과 한계는 무엇인가?
주요 결과
- Tulu 3 모델은 같은 크기의 개방 가중치 SOTA 기준치를 능가한다, 예를 들면 Llama 3.1 Instruct, Qwen2.5 Instruct, 및 Mistral-Instruct.
- 70B에서 Tulu 3는 Claude 3.5 Haiku 및 GPT-4o mini와 같은 일부 폐쇄형 모델의 기능에 상응한다.
- Tulu 3 파이프라인은 SFT, DPO, RLVR를 결합하여 핵심 기술 전반에서 강력한 성능을 달성한다.
- 광범위한 오염 제거 및 견고한 평가 프레임워크가 벤치마크 결과의 신뢰성을 높인다.
- 출시는 모델 가중치, 데이터, 코드 및 재현 및 적응을 가능하게 하는 엔드 투 엔드 레시피를 포함한다.
- RLVR의 새로운 RL 목표는 보상이 검증 가능하도록 보장하여 기술별 개선을 이끈다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.