[논문 리뷰] Turning large language models into cognitive models
저자들은 심리 데이터로 대형 언어 모델(LLaMA)을 미세조정하여 CENTaUR를 만들었고, 이는 인간의 선택을 예측하고 새로운 작업에 일반화할 수 있는 인지 모델링 시스템이며, 의사결정 영역에서 전통적 인지 모델을 능가하고 개인 차이를 포착한다.
Large language models are powerful systems that excel at many tasks, ranging from translation to mathematical reasoning. Yet, at the same time, these models often show unhuman-like characteristics. In the present paper, we address this gap and ask whether large language models can be turned into cognitive models. We find that -- after finetuning them on data from psychological experiments -- these models offer accurate representations of human behavior, even outperforming traditional cognitive models in two decision-making domains. In addition, we show that their representations contain the information necessary to model behavior on the level of individual subjects. Finally, we demonstrate that finetuning on multiple tasks enables large language models to predict human behavior in a previously unseen task. Taken together, these results suggest that large, pre-trained models can be adapted to become generalist cognitive models, thereby opening up new research directions that could transform cognitive psychology and the behavioral sciences as a whole.
연구 동기 및 목표
- 도메인 특화 행동 데이터를 활용하여 대형 언어 모델을 도메인 일반 인지 모델로 전환하는 것을 동기로 삼는다.
- 심리 데이터로 대형 언어 모델을 미세조정하면 정확하고 인간과 유사한 의사결정 표현이 얻어짐을 입증한다.
- 미세조정된 모델의 임베딩이 행동의 개인 차이를 포착한다는 것을 보여준다.
- 두 작업에서 학습된 모델을 보류된 세 번째 작업에서 평가하여 일반화를 검증한다.
제안 방법
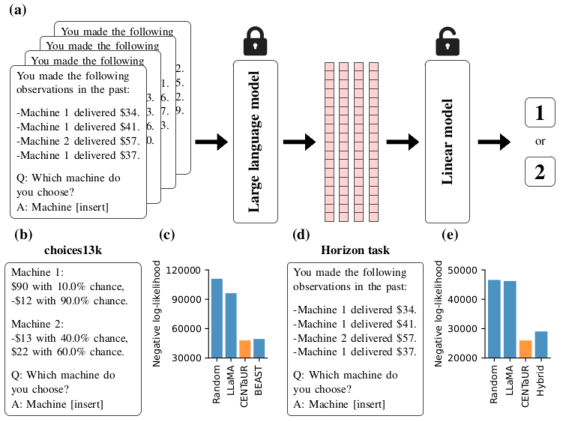
- LLaMA(65B 매개변수)를 사용하고 심리 실험을 설명하는 프롬프트에서 임베딩을 추출한다.
- LLaMA 임베딩 위에 선형 계층을 미세조정하여 인간의 선택을 예측한다 (CENTaUR).
- 기대성능을 기준선(random, raw LLaMA, BEAST, Gershman 하이브리드) 대비 100-fold 교차검증으로 평가한다.
- 설명에서의 선택(choices13k)과 체험 실험(horizon task)에서 학습한 후 보류된 작업 성능을 평가한다.
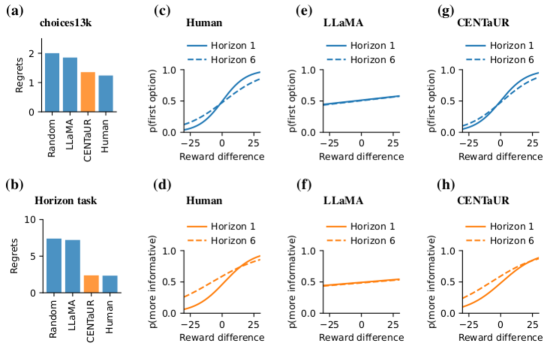
- 모델 행동을 시뮬레이션하여 인간 데이터와 비교하기 위한 후회 및 선택 곡선을 비교한다.
- 개인 차이를 포착하기 위해 미세조정 계층에서 참가자별 무작위 효과를 허용한다.
실험 결과
연구 질문
- RQ1대형 언어 모델 임베딩의 미세조정으로 인간의 의사결정에 대한 정확한 모델을 생성할 수 있는가?
- RQ2CENTaUR 임베딩에 개별 피험자 수준의 행동을 모델링하는 데 충분한 정보가 포함되어 있는가?
- RQ3여러 작업에서 미세조정된 모델이 이전에 보지 못한 작업에서 인간 행동을 예측할 수 있는가?
- RQ4예측 정확도와 행동적 현실성 측면에서 CENTaUR는 도메인 특화 인지 모델과 어떻게 비교되는가?
주요 결과
- CENTaUR은 choices13k에서 NLL 48002.3를 달성하여 BEAST(49448.1)를 능가했다.
- CENTaUR은 horizon task에서 NLL 25968.6를 달성했고 하이브리드 모델(29042.5)을 능가했다.
- 보류된 experiential-symbolic task에서 CENTaUR의 NLL은 4521.1로 무작위(5977.7)와 LLaMA(6307.9)보다 낫다.
- 시뮬레이션에서 CENTaUR의 후회(1.35, SE 0.01)는 인간(1.24, SE 0.01)에 더 근접했으며 LLaMA(1.85, SE 0.01)보다 가깝다.
- CENTaUR은 인간과 유사한 선택 곡선을 포착하여 정보가 같건 다르건 탐색 효과를 재현하지만 LLaMA와는 다르다.
- 임베딩 기반 모델이 개인 차이를 잘 설명했고; 참가자별 무작위 효과를 추가하면 적합도가 향상되었다(NLL 23929.5 vs 25968.6).
- 두 작업에서 미세조정된 모델이 세 번째 보류 작업으로 일반화되어 새로운 패러다임의 인간 행동을 예측한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.