[논문 리뷰] U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation
UNet에서 영감을 받은 트랜스포머 디코더와 다중 스케일 인코더/디코더 특징을 융합하는 믹스-어텐션 메커니즘을 도입하여 다양한 인코더와 데이터셋에서 시맨틱 분할의 효율성과 정확성을 개선합니다.
Semantic segmentation has witnessed remarkable advancements with the adaptation of the Transformer architecture. Parallel to the strides made by the Transformer, CNN-based U-Net has seen significant progress, especially in high-resolution medical imaging and remote sensing. This dual success inspired us to merge the strengths of both, leading to the inception of a U-Net-based vision transformer decoder tailored for efficient contextual encoding. Here, we propose a novel transformer decoder, U-MixFormer, built upon the U-Net structure, designed for efficient semantic segmentation. Our approach distinguishes itself from the previous transformer methods by leveraging lateral connections between the encoder and decoder stages as feature queries for the attention modules, apart from the traditional reliance on skip connections. Moreover, we innovatively mix hierarchical feature maps from various encoder and decoder stages to form a unified representation for keys and values, giving rise to our unique mix-attention module. Our approach demonstrates state-of-the-art performance across various configurations. Extensive experiments show that U-MixFormer outperforms SegFormer, FeedFormer, and SegNeXt by a large margin. For example, U-MixFormer-B0 surpasses SegFormer-B0 and FeedFormer-B0 with 3.8% and 2.0% higher mIoU and 27.3% and 21.8% less computation and outperforms SegNext with 3.3% higher mIoU with MSCAN-T encoder on ADE20K. Code available at https://github.com/julian-klitzing/u-mixformer.
연구 동기 및 목표
- U-네트와 비전 트랜스포머의 강점을 효율적인 시맨틱 분할을 위해 결합한다.
- 인코더 쪽의 측면 특징을 질의로, 다단계 혼합 특징을 키/값으로 사용하는 디코더를 설계한다.
- CNN- 기반 인코더와 트랜스포머 기반 인코더 모두와의 호환성을 보장하면서 문맥과 경계를 개선한다.
- ADE20K와 Cityscapes에서 최신의 효율-정확도 트레이드오프를 입증한다.
제안 방법
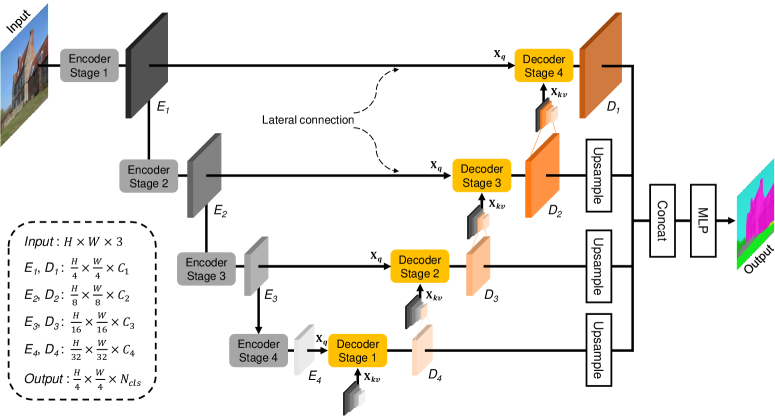
- 각 단계가 측면 인코더 특징을 질의로 사용하는 UNet 유사 트랜스포머 디코더를 제안한다.
- 다중 스케일 인코더/디코더 특징의 혼합으로 키/값을 구성하는 믹스-어텐션을 도입한다.
- 병합하기 전에 공간 축소(AvgPool 및 선형 프로젝션)를 통해 각 단계의 특징 맵을 정렬한 뒤 X_kv에 연결한다.
- 단계 간 명시적 업샘플링 없이 디코더 특징을 단계 간에 전파하는 U-Net 진행을 모방한다.
- 디코더 출력을 연결하고 MLP를 적용하여 분할을 예측한다.
- 다양한 인코더(MiT, LVT, MSCAN)에서 평가하고 Cityscapes-C에서의 왜곡에 대한 강건성을 보인다.

실험 결과
연구 질문
- RQ1믹스-어텐션이 있는 UNet에서 영감을 받은 트랜스포머 디코더가 기존의 교차/자체 주의 디코더 대비 분할 품질과 효율성을 향상시킬 수 있는가?
- RQ2키/값에 다중 스케일 특징을 혼합하는 것이 시맨틱 분할에서 문맥 모델링과 경계 구분에 어떤 영향을 미치는가?
- RQ3제안된 디코더가 CNN- 및 트랜스포머 기반 인코더와의 호환성을 유지하며 일관된 이득을 제공하는가?
- RQ4믹스-어텐션과 UNet 스타일의 디코딩이 이미지 왜곡에 대한 강건성에 어떤 영향을 미치는가?
- RQ5MiT-B3/4/5 등 더 큰 인코더 백본이 U-MixFormer의 mIoU와 계산량에 어떤 영향을 주는가?
주요 결과
- U-MixFormer-B0는 ADE20K에서 41.2 mIoU를 달성하고 매개변수 6.1M, GFLOPs 6.1으로 SegFormer-B0 및 FeedFormer-B0보다 각각 3.8% 포인트 및 2.0% 포인트의 mIoU 향상을 보이며 계산량을 감소시켰다.
- LVT 인코더를 사용하면 mIoU가 43.7로, MSCAN-T를 사용하면 44.4로 증가하였으며 FLOPs는 경쟁력 있게 유지된다.
- ADE20K의 무거운 인코더 버전에서 MiT-B3/4/5 변형이 각각 49.8, 50.4, 51.9 mIoU에 도달하고 유사한 방법 대비 FLOPs가 크게 감소한다.
- MiT-B4/5와 함께 U-MixFormer+는 51.2–52.0 mIoU의 점진적 이득을 더 modest한 비용 증가로 보여주며 인코더 깊이와의 확장성을 보인다.
- Cityscapes 결과는 강력한 이득을 보여주며, U-MixFormer는 LVT에서 최대 79.9 mIoU, MSCAN-S에서 81.0 mIoU를 달성하고 다수의 기준선 대비 낮은 FLOPs를 유지한다.
- 특성-혼합 어텐션과 UNet 유사 디코딩이 서로 보완적으로 최상의 성능(41.2 mIoU)을 제공한다는 것이 감소된 자가 주의나 교차 주의만으로는 불충분하다는 것을 입증하는 분석 결과를 확인한다.
- Cityscapes-C 오염 강건성에서 U-MixFormer가 SegFormer 및 FeedFormer보다 다양한 오염에 강건하며 어려운 조건에서도 신뢰성을 향상시킨다는 것을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.