[논문 리뷰] UltraFeedback: Boosting Language Models with Scaled AI Feedback
UltraFeedback는 오픈소스 LLM의 RLHF를 개선하기 위해 대규모의 세밀한 선호도 및 비판 데이터셋을 생성하여 새로운 보상 및 비판 모델을 가능하게 하고 RLHF 및 best-of-n 전략을 통한 성능 향상을 보여줍니다.
Learning from human feedback has become a pivot technique in aligning large language models (LLMs) with human preferences. However, acquiring vast and premium human feedback is bottlenecked by time, labor, and human capability, resulting in small sizes or limited topics of current datasets. This further hinders feedback learning as well as alignment research within the open-source community. To address this issue, we explore how to go beyond human feedback and collect high-quality extit{AI feedback} automatically for a scalable alternative. Specifically, we identify extbf{scale and diversity} as the key factors for feedback data to take effect. Accordingly, we first broaden instructions and responses in both amount and breadth to encompass a wider range of user-assistant interactions. Then, we meticulously apply a series of techniques to mitigate annotation biases for more reliable AI feedback. We finally present extsc{UltraFeedback}, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon extsc{UltraFeedback}, we align a LLaMA-based model by best-of-$n$ sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks. Our work validates the effectiveness of scaled AI feedback data in constructing strong open-source chat language models, serving as a solid foundation for future feedback learning research. Our data and models are available at https://github.com/thunlp/UltraFeedback.
연구 동기 및 목표
- RLHF를 위한 오픈소스 선호 데이터의 데이터 부족 문제를 해결한다.
- 텍스트 피드백이 포함된 대규모하고 다양하며 세밀하게 주석된 선호 데이터셋을 구축한다.
- UltraFeedback를 사용하여 오픈소스 보상 모델(UltraRM)과 비판 모델(UltraCM)을 훈련한다.
- best-of-n 샘플링 및 PPO 기반 RLHF를 통해 오픈소스 LLM의 개선을 입증한다.
- 향후 RLHF 연구를 위한 재현 가능한 데이터 구성 및 모델 학습 파이프라인을 제공한다.
제안 방법
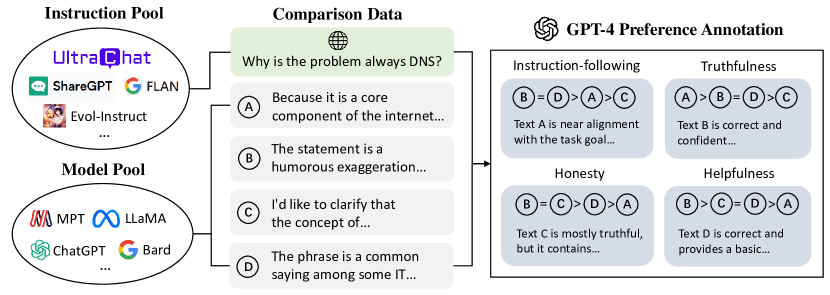
- 다양한 소스에서 다양한 지침과 모델 완성을 샘플링하여 비교 데이터를 생성한다.
- 각 완성에 대해 스칼라 선호도와 상세한 텍스트 비판을 생성하기 위해 GPT-4를 사용한다.
- 쌍 간 선호되는 완성을 선택하기 위해 이진 순위 손실(binary ranking loss)을 사용하여 UltraRM을 훈련한다.
- UltraRM을 보상 모델로 사용하여 best-of-n 샘플링과 PPO로 UltraLM을 미세조정한다.
- 자동 비판 생성을 가능하게 하기 위해 UltraFeedback 텍스트 비판으로 UltraCM을 훈련한다.
실험 결과
연구 질문
- RQ1UltraFeedback가 오픈소스 모델에 일반화되는 고품질의 미세한 선호 데이터를 생성할 수 있는가?
- RQ2UltraFeedback로 훈련된 보상 모델이 표준 벤치마크에서 기존의 오픈소스 기준 모델보다 성능이 우수한가?
- RQ3PPO를 통한 UltraRM(RLHF)이 다른 접근법보다 오픈소스 채팅 모델의 성능을 더 향상시키는가?
- RQ4동반 비판 모델인 UltraCM이 작업 전반에 걸쳐 유용하고 고품질의 피드백을 제공할 수 있는가?
주요 결과
- UltraFeedback로 학습된 UltraRM 변형은 여러 벤치마크에서 여러 오픈소스 보상 모델보다 우수하다.
- UltraRM 보상을 사용하는 Best-of-n 샘플링은 추가 훈련 없이 응답 품질을 크게 향상시킨다.
- UltraFeedback을 사용한 UltraLM-13B의 PPO 미세조정은 공개 벤치마크에서 강한 성능 향상을 보인다.
- UltraCM은 다양한 과제에서 일부 폐쇄형 또는 더 큰 경쟁자들의 품질에 근접하는 자세하고 고품질의 텍스트 비판을 제공한다.
- 이 데이터셋은 오픈소스 RLHF 연구를 위한 재현 가능한 보상 모델링 및 비판 모델링 워크플로를 지원한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.