[논문 리뷰] Understand Legal Documents with Contextualized Large Language Models
이 논문은 순차적 수사적 역할 분류를 위한 Legal-BERT-HSLN과 법적 명명 엔터티 인식을 위한 Legal-LUKE를 제시하여 베이스라인을 능가하고 수사 롤 리더보드에서 상위 5위에 도달했다.
The growth of pending legal cases in populous countries, such as India, has become a major issue. Developing effective techniques to process and understand legal documents is extremely useful in resolving this problem. In this paper, we present our systems for SemEval-2023 Task 6: understanding legal texts (Modi et al., 2023). Specifically, we first develop the Legal-BERT-HSLN model that considers the comprehensive context information in both intra- and inter-sentence levels to predict rhetorical roles (subtask A) and then train a Legal-LUKE model, which is legal-contextualized and entity-aware, to recognize legal entities (subtask B). Our evaluations demonstrate that our designed models are more accurate than baselines, e.g., with an up to 15.0% better F1 score in subtask B. We achieved notable performance in the task leaderboard, e.g., 0.834 micro F1 score, and ranked No.5 out of 27 teams in subtask A.
연구 동기 및 목표
- 법률 텍스트에서 내부-문장 간 맥락을 더 잘 다루기 위해 순차적 문장 분류로 수사적 역할 예측을 형식화한다.
- 문장 단위 수사적 역할 표기를 위한 맥락 인식적 계층 모델(Legal-BERT-HSLN)을 개발한다.
- 법적 명명 엔터티 인식을 위한 엔티티 인식을 고려한 맥락 의존적 모델(Legal-LUKE)을 설계한다.
- F1 점수 및 리더보드 위치의 향상을 입증하기 위해 강력한 베이스라인과의 비교를 평가한다.
제안 방법
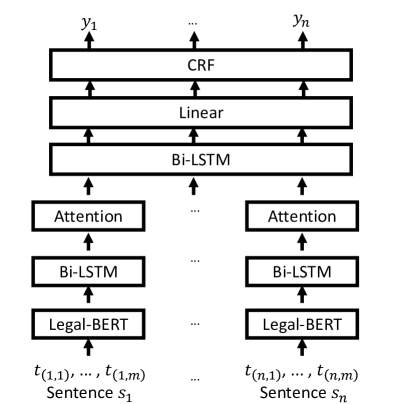
- 계층적 구조를 갖는 Legal-BERT-HSLN을 채택: Legal-BERT의 토큰 임베딩, Bi-LSTM 맥락화, 주의 풀링, 시퀀스 레이블링을 위한 CRF 디코딩.
- 긴 거리 의존관계를 포착하기 위해 문장 간 맥락을 활용하여 문장 표현을 강화하여 장거리 의존성을 포착한다.
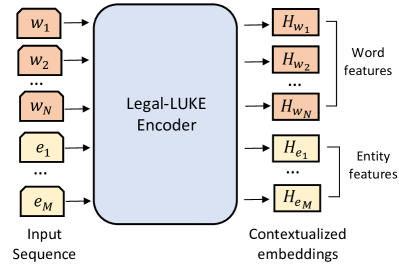
- 토큰, 타입, 위치 임베딩을 포함한 법적 맥락화 단어 및 엔터티 표현 학습을 위해 LUKE 아키텍처를 기반으로 한 Legal-LUKE를 제안한다.
- Legal-LUKE에서 NER를 위한 공동 단어 및 엔터티 임베딩을 생성하기 위해 엔터티 시퀀스를 단어 시퀀스와 함께 통합한다.
- 제약된 자원 설정하에서 BERT-CRF, BERT-Span, XLM-RoBERTa-CRF, mLUKE를 포함한 베이스라인과 비교한다.
실험 결과
연구 질문
- RQ1맥락화된 언어 모델이 법률 문서에서 수사적 역할 분류를 위해 문장 내부 및 문장 간 맥락을 얼마나 효과적으로 포착할 수 있는가?
- RQ2엔터티 인식을 고려한 맥락 풍부한 모델이 표준 인코더에 비해 법적 NER 성능을 향상시킬 수 있는가?
- RQ3제안된 모델이 SemEval-2023 Task 6 벤치마크에서 강력한 베이스라인과 얼마나 비교되는가?
- RQ4길고 노이즈가 많은 문서에 맥락화된 법적 모델을 적용할 때의 실용적 한계와 하이퍼파라미터 민감도는 무엇인가?
주요 결과
| 모델 | Micro F1 점수 | 최적 에포크 |
|---|---|---|
| BERT-Base | 0.631 | 5 |
| BERT-Mean | 0.641 | 4 |
| BERT-Regularization | 0.597 | 4 |
| BERT-Augmentation | 0.645 | 4 |
| Legal-BERT-HSLN | 0.828 | 16 |
- Legal-BERT-HSLN은 검증에서 micro F1 0.828, 테스트에서 0.8343를 달성해 수사적 역할 분류에서 27개 팀 중 5위에 랭크됐다.
- Legal-LUKE는 법적 NER에서 베이스라인을 능가하며 검증에서 micro F1이 최대 0.796로, 기재된 베이스라인 중 최고이다.
- Legal-LUKE는 NER에서 BERT-CRF 베이스라인 대비 micro F1이 최대 14.3% 향상된다.
- XLM-RoBERTa-CRF 베이스라인과 mLUKE도 NER에서 강력한 성능을 보이며, XLM-RoBERTa-CRF가 0.773, mLUKE가 0.787에 도달한다.
- 수사적 역할 분류에 대한 규제화 전처리는 성능을 저하시키며, 불용어와 문장 구분 표시 등에 민감함을 시사한다.
- Legal-LUKE의 테스트 세트 결과가 (0.667)로 검증보다 낮아 두 세트 간 분포 변화가 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.