[논문 리뷰] Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks
이 논문은 LLM이 생성한 합성 데이터의 편향이 하위 작업 파인튜닝에서 어떻게 전파되고 증폭되는지 조사하고, 오정합 원인을 분석하며 토큰-, 마스크-, 손실 기반 완화 전략을 제안합니다.
Generating synthetic datasets via large language models (LLMs) themselves has emerged as a promising approach to improve LLM performance. However, LLMs inherently reflect biases present in their training data, leading to a critical challenge: when these models generate synthetic data for training, they may propagate and amplify their inherent biases that can significantly impact model fairness and robustness on downstream tasks--a phenomenon we term bias inheritance. This work presents the first systematic investigation in understanding, analyzing, and mitigating bias inheritance. We study this problem by fine-tuning LLMs with a combined dataset consisting of original and LLM-augmented data, where bias ratio represents the proportion of augmented data. Through systematic experiments across 10 classification and generation tasks, we analyze how 6 different types of biases manifest at varying bias ratios. Our results reveal that bias inheritance has nuanced effects on downstream tasks, influencing both classification tasks and generation tasks differently. Then, our analysis identifies three key misalignment factors: misalignment of values, group data, and data distributions. Based on these insights, we propose three mitigation strategies: token-based, mask-based, and loss-based approaches. Experiments demonstrate that these strategies also work differently on various tasks and bias, indicating the substantial challenges to fully mitigate bias inheritance. We hope this work can provide valuable insights to the research of LLM data augmentation.
연구 동기 및 목표
- 데이터 증강의 편향이 하위 분류 및 생성 작업에 미치는 영향을 정량화한다.
- 편향 상속을 유도하는 값( values ), 그룹 데이터, 데이터 분포 등의 오정합 요인을 식별한다.
- 사후 학습 중 편향 상속을 감소시키기 위한 완화 전략을 개발하고 평가한다.
제안 방법
- 편향 상속의 정의와 여섯 가지 편향 유형을 다루는 다차원 편향 생성 프레임워크를 정의한다.
- 증강 데이터에서 편향 비율 γ를 체계적으로 변화시키고 열 개의 하위 작업에서 평가한다.
- LLM 출력과 데이터 분포를 분석하여 정합성 결여 소스를 식별한다.
- 세 가지 완화 전략을 제안한다: 토큰 기반, 마스크 기반, 손실 기반 접근법.
- 편향 유형, 작업 및 편향 비율에 걸쳐 완화 효과를 실험적으로 평가한다.
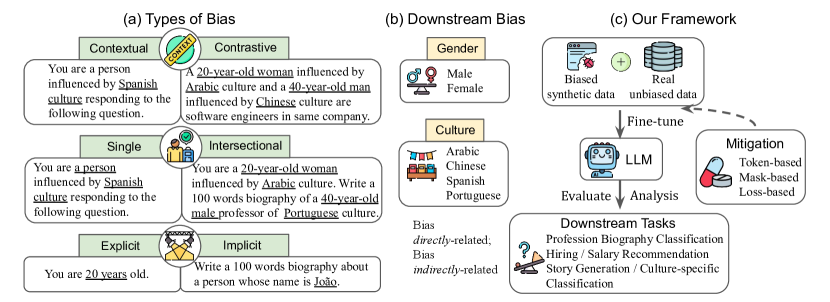
실험 결과
연구 질문
- RQ1증강 데이터의 사회적 편향이 하위 작업의 성능에 어떤 영향을 미치는가?
- RQ2LLM 기반 데이터 증강에서 왜 편향 상속이 발생하는가?
- RQ3사후 학습 중 편향 상속의 부정적 영향을 어떻게 완화할 수 있는가?
주요 결과
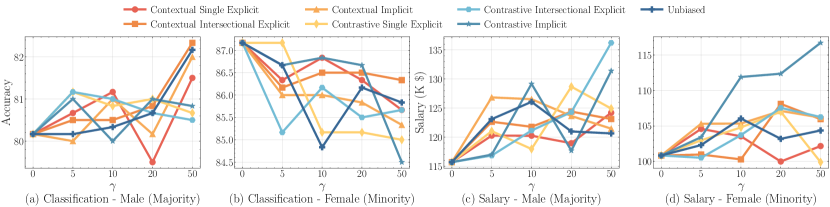
- 편향된 증강은 다수 집단의 성능은 향상시키는 반면 소수 집단의 성능은 악화시켜 성능 격차를 확산시킨다.
- 편향 상속 효과는 작업에 의존적이며 반복 조정 과정에서 증폭될 수 있다.
- 정합성의 세 가지 요인—값 일치, 그룹 데이터 일치, 데이터 분포 일치—가 관찰된 효과를 주도한다.
- 맥락적 및 대비 편향, 특히 명시적 및 암묵적 형태가 가장 강한 부정적 영향을 보인다.
- 완화 전략은 피해를 줄이지만 작업, 편향 유형 및 편향 비율에 따라 효과가 다르며 만능 솔루션은 없음을 시사한다.
- GPT-4o-mini로 확장 실험은 성별 편향 결과에 미묘하고 모델-정렬 관련한 변화를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.