[논문 리뷰] Understanding Emergent In-Context Learning from a Kernel Regression Perspective
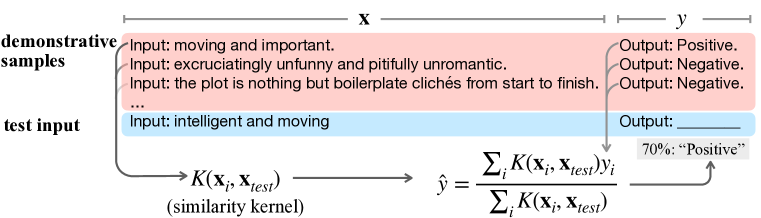
트랜스포머의 맥락 내 학습은 데모에 대한 커널 회귀로 나타나며, 주의(attention)를 샘플 라벨의 커널 유사 가중치와 연결하는 이론 및 경험적 분석에 의해 뒷받침된다.
Large language models (LLMs) have initiated a paradigm shift in transfer learning. In contrast to the classic pretraining-then-finetuning procedure, in order to use LLMs for downstream prediction tasks, one only needs to provide a few demonstrations, known as in-context examples, without adding more or updating existing model parameters. This in-context learning (ICL) capability of LLMs is intriguing, and it is not yet fully understood how pretrained LLMs acquire such capabilities. In this paper, we investigate the reason why a transformer-based language model can accomplish in-context learning after pre-training on a general language corpus by proposing a kernel-regression perspective of understanding LLMs' ICL bahaviors when faced with in-context examples. More concretely, we first prove that Bayesian inference on in-context prompts can be asymptotically understood as kernel regression $\hat y = \sum_i y_i K(x, x_i)/\sum_i K(x, x_i)$ as the number of in-context demonstrations grows. Then, we empirically investigate the in-context behaviors of language models. We find that during ICL, the attention and hidden features in LLMs match the behaviors of a kernel regression. Finally, our theory provides insights into multiple phenomena observed in the ICL field: why retrieving demonstrative samples similar to test samples can help, why ICL performance is sensitive to the output formats, and why ICL accuracy benefits from selecting in-distribution and representative samples. Code and resources are publicly available at https://github.com/Glaciohound/Explain-ICL-As-Kernel-Regression.
연구 동기 및 목표
- 대규모 일반 코퍼스에 대한 사전 학습 후 LLM이 맥락 내 학습을 보이는 이유를 동기 부여하고 이해한다.
- ICL에 대한 이론적 설명으로 커널 회귀 관점을 제안한다.
- 트랜스포머의 주의 메커니즘을 커널 회귀 계산과 연결한다.
- LLM 주의 및 중간 특징에서 커널 회귀 유사 동작을 경험적으로 검증한다.
제안 방법
- 맥락 내 학습을 프리-트레이닝 역학에서 정의된 커널(K(x, x'))을 갖는 커널 회귀로 수렴하는 베이지안 추론으로 공식화한다.
- 시현 예시의 수가 증가함에 따라 맥락 내 프롬프트에 대한 베이지안 후포가 커널 회귀 예측기로 수렴함을 보이는 정리를 도출한다.
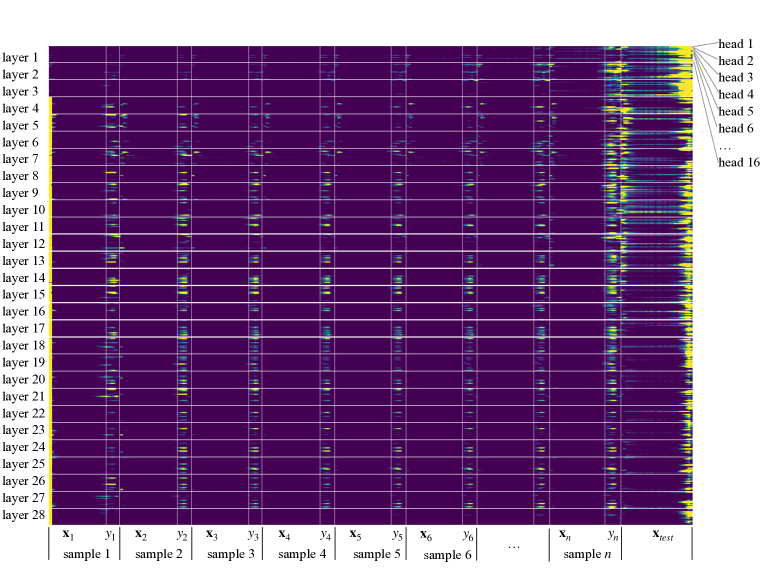
- GPT-J-6B를 경험적으로 분석하여 주의 분포를 점검하고, 주의에서 ICL 예측을 재구성하며, 커널 회귀 신호를 위한 중간 특징을 탐색한다.
- 커널 회귀 기반 재구성이 태스크 특화 헤드 및 문장 인코더 기준선과 어떻게 비교되는지 검토한다.
- 다수의 계층에서 주의 가중치, 샘플 라벨 및 예측 출력 간의 정합성을 시연한다.
실험 결과
연구 질문
- RQ1데몬스트레이션 수가 증가함에 따라 맥락 내 프롬프트에 대한 베이지안 추론이 커널 회귀로 수렴하는가?
- RQ2ICL 중 LLM의 주의 패턴이 맥락 내 샘플에 대한 커널 회귀 유사 가중치를 반영하는가?
- RQ3모델 어느 부분에 커널 회귀 정보를 인코딩하는 특징이 저장되고 그것이 예측에 어떻게 기여하는가?
- RQ4커널 회귀 기반 재구성이 실제 ICL 예측과 일치할 수 있으며, 데몬스트레이션이 성능에 어떤 영향을 미치는가?
- RQ5ICL에서 비슷한 샘플의 회수와 라벨 형식에 대한 민감도와 같은 현상을 무엇이 설명하는가?
주요 결과
- 이론적 결과: 맥락 내 프롬프트에 대한 베이지안 추론은 데모의 수가 증가함에 따라 커널 회귀 형태로 수렴한다.
- Attention distributions during ICL concentrate on sample labels and can reconstruct predictions with high accuracy (up to 89.2% in some heads).
- Some middle-layer heads (layers ~18–21) show kernel-regression-like behavior and can predict outputs using kernel-weighted label information.
- The similarity kernel aligns with attention-based weighting, linking semantic representations to kernel similarities.
- Reconstructed kernel-regression predictions using head features achieve comparable accuracy to ICL and to kernel methods on several tasks (sst2, mnli, etc.).
- Retrieving demonstrations similar to the test input improves ICL by effectively narrowing the kernel bandwidth and reducing bias.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.