[논문 리뷰] Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields
이 논문은 Vision Transformer가 효과적 수용 영역(ERF)을 통해 공간 이해를 어떻게 얻는지 분석하고, 위치 임베딩이 순서 인식을 기여한다는 것을 보여주며, ViT의 성능을 다양한 태스크와 데이터셋에서 향상시키기 위한 Gaussian attention bias를 제안합니다.
Vision transformers (ViTs) that model an image as a sequence of partitioned patches have shown notable performance in diverse vision tasks. Because partitioning patches eliminates the image structure, to reflect the order of patches, ViTs utilize an explicit component called positional embedding. However, we claim that the use of positional embedding does not simply guarantee the order-awareness of ViT. To support this claim, we analyze the actual behavior of ViTs using an effective receptive field. We demonstrate that during training, ViT acquires an understanding of patch order from the positional embedding that is trained to be a specific pattern. Based on this observation, we propose explicitly adding a Gaussian attention bias that guides the positional embedding to have the corresponding pattern from the beginning of training. We evaluated the influence of Gaussian attention bias on the performance of ViTs in several image classification, object detection, and semantic segmentation experiments. The results showed that proposed method not only facilitates ViTs to understand images but also boosts their performance on various datasets, including ImageNet, COCO 2017, and ADE20K.
연구 동기 및 목표
- ViTs가 효과적 수용 영역(ERF)을 통해 공간 구조를 어떻게 이해하는지 조사한다.
- 순서 인식이 사전 정의된 위치 신호가 아니라 학습된 위치 임베딩에서 비롯됨을 보인다.
- 학습 초기에 공간 이해를 구현하기 위해 Gaussian 주의 집중 바이어스(Gaussian attention bias)를 제안한다.
- Gaussian 주의 집중 바이어스가 다중 데이터셋에서 분류, 탐지, 세분화 태스크에 걸쳐 ViT 성능을 향상시킴을 보여준다.
제안 방법
- 다수의 이미지에서 평균화된 기울기를 이용해 ViT의 ERF를 계산 및 분석하여 패치 기여를 밝힌다.
- ERF 형성에서 절대 위치 임베딩(APE)와 상대 위치 임베딩(RPE)의 역할과 이를 재초기화했을 때 활동에 미치는 영향을 고찰한다.
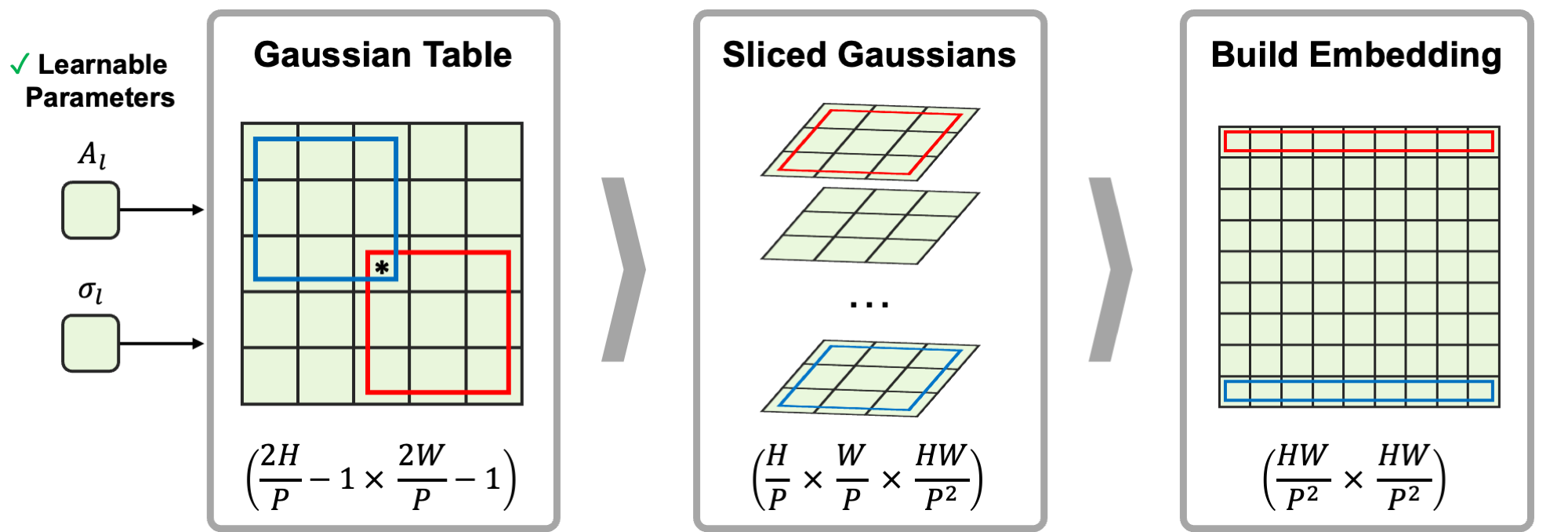
- 어텐션 스코어에 B_Gaussian_l을 추가하는 Gaussian attention bias를 제안한다. 이는 softmax(QK^T/√D + B_rel,l + B_Gaussian,l) 형식으로 작동한다.
- A_l 및 σ_l로 매개변수화된 2D 가우시안들을 적층하여 B_Gaussian,l을 구성하고, 진폭이 음수가 되지 않도록 하며 헤드 간에 계층별로 공유하도록 설계한다.
- B_Gaussian,l을 미분 가능하게 만들고 선택적으로 A_l 및 σ_l을 학습하도록 하면서 기존 RPE(RelPosBias 또는 RelPosMlp)와의 호환성을 보존한다.
- ImageNet-1K 및 다른 데이터셋에서 ViT 변형들을 평가하고 Gaussian attention bias로 인한 top-1 정확도 향상을 측정한다.
실험 결과
연구 질문
- RQ1ViT의 순서 인식은 기본적으로 고유한 SA 구조가 아니라 학습된 위치 임베딩에서 주로 나타나는가?
- RQ2상대 위치 인코딩에 Gaussian attention bias를 주입하면 초기화 시점부터 공간 이해를 유도하고 다운스트림 태스크를 향상시킬 수 있는가?
주요 결과
- ViT의 ERF는 대상 패치에 집중하고 이웃 패치를 부분적으로 사용하는 것으로 보이며, 공간 이해가 학습 중에 나타난다는 것을 시사한다.
- 학습되지 않은 RPE는 거리에 무감각한 ERF를 보이고, 학습된 RPE는 근거리-원거리 패치 구별을 용이하게 하는 2D 가우시안 유사 패턴으로 수렴한다.
- Gaussian 주의 집중 바이어스를 추가하면 ImageNet-1K, Oxford-IIIT Pet, Caltech-101, Stanford Cars, Stanford Dogs에서 ViT 성능이 향상되며 ImageNet-1K에서 예를 들면 +0.157 (S/16), +0.362 (B/16) 같은 이득이 있다.
- Gaussian 바이어스는 객체 탐지와 의미론적 세분화 태스크에서도 약간의 개선을 제공한다(예: RelPosBias를 적용한 Swin-S에서: AP_box +0.11, AP_mask +0.10, mIoU +0.25, aAcc +0.27).
- 학습된 σ_l은 데이터셋에 따라 적응하며 유연한 ERF 크기를 가능하게 한다; 마지막 두 계층은 가우시안 패턴을 학습하지 못할 수 있어 계층별 동작 차이를 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.