[논문 리뷰] Uni3D: Exploring Unified 3D Representation at Scale
Uni3D는 6M에서 10억까지 확장되는 십억 파라미터 규모의 통합 3D 기초 모델을 제시하여 3D 포인트 클라우드를 이미지-텍스트 CLIP 특징과 정렬하고 제로샷, 파샷 및 오픈월드 3D 이해에서 최첨단 성능을 달성한다.
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
연구 동기 및 목표
- 2D/ NLP 기초 모델과 유사한 규모의 통합 3D 표현 학습의 필요성을 제시한다.
- 풍부한 2D 사전학습을 활용해 3D 백본을 초기화하고 십억 파라미터 모델로 확장한다.
- 다중 모달 대비 학습을 통해 3D 포인트 클라우드 특징을 이미지-텍스트 정렬 특징과 맞춘다.
- 다양한 3D 작업에서 강력한 제로샷, 파샷 및 오픈월드 성능을 보여준다.
- 현장 환경에서의 3D 페인팅 및 검색과 같은 다운스트림 응용을 탐구한다.
제안 방법
- 3D 백본으로 통합된 일반 트랜스포머(ViT 유사)를 사용한다.
- ViT 패치 임베딩을 포인트 토크나이저로 대체하여 포인트를 패치로 묶고 작은 PointNet을 사용해 3D 토큰을 생성한다.
- 사전학습을 엔드투엔드로 수행하여 3D 포인트 클라우드 특징을 사전 학습된 CLIP 모델의 이미지-텍스트 특징과 정렬한다.
- 2D 사전학습 모델(EVA, DINO 등) 또는 교차모달 모델(CLIP)로 Uni3D를 초기화한 다음 이미지/텍스트 인코더를 고정하고 3D 인코더를 미세조정한다.
- 3D, 이미지, 텍스트 간 다중모달 대비 손실(트리플릿 대비 목표)을 사용하고 OpenAI CLIP, EVA-CLIP 등 유연한 CLIP 교사를 허용한다.
- 통합된 2D/NLP 확장 법칙을 따르며 모델을 6M에서 1B 파라미터로 확장한다; 거의 백만 개의 3D 형태, 1000만 장의 이미지, 7000만 개의 텍스트를 사용해 학습한다.
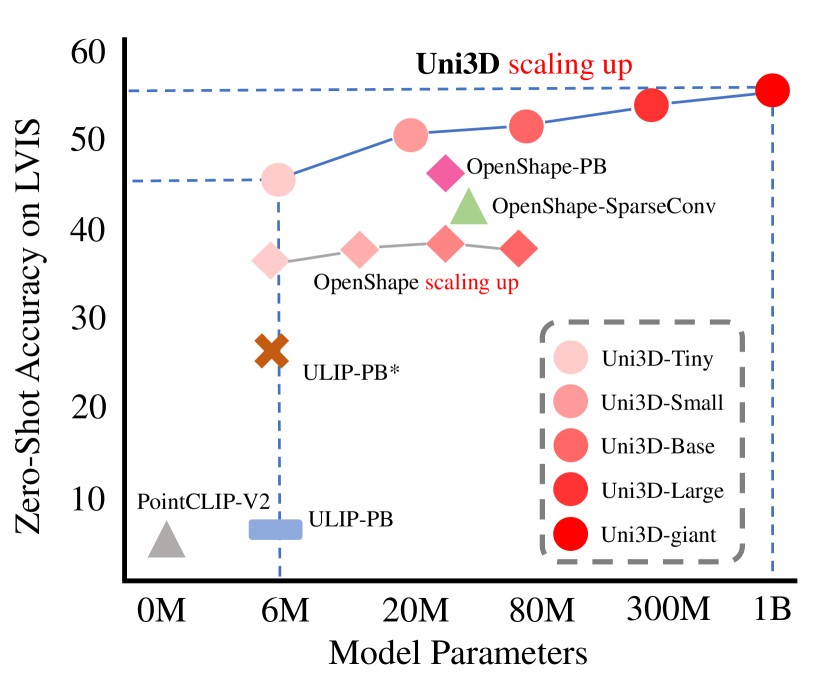
실험 결과
연구 질문
- RQ1십억 규모에서 학습된 통합 3D 표현이 제로샷, 파샷, 오픈월드, 분할 등 다양한 3D 작업으로 효과적으로 이전될 수 있는가?
- RQ22D 사전학습으로 초기화하고 이미지-텍스트 표현에 맞추는 것이 대규모 데이터로 확장 가능한 3D 학습을 가능하게 하는가?
- RQ3CLIP 스타일 교사와 확장 전략이 3D 기본 모델을 얼마나 개선할 수 있는가?
- RQ4십억 파라미터 3D 모델에서 어떤 다운스트림 기능이 나타나는가(예: 검색, 페인팅, 개방 어휘 분할)?
주요 결과
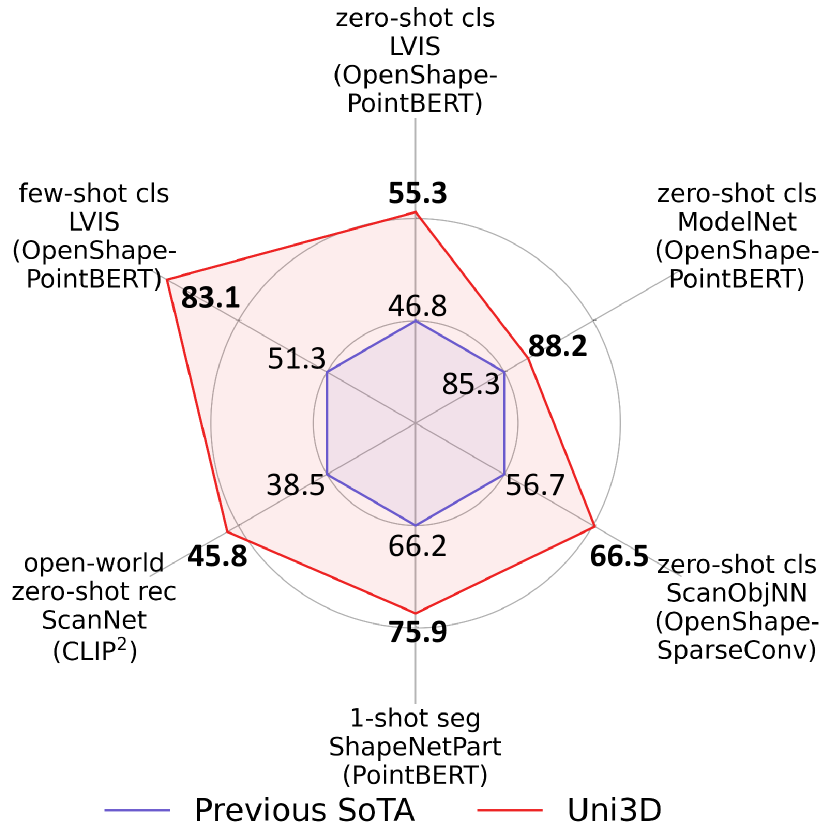
- Uni3D는 여러 3D 벤치마크에서 최첨단 제로샷 및 파샷 성능을 달성하고 이전 방법들을 능가한다.
- 다중모달 정렬로 학습된 10억 파라미터 Uni3D 모델은 오픈월드 이해 및 부분 분할에 잘 일반화된다.
- ModelNet에서의 제로샷 분류는 논문에 보고된 대로 상위 5위 88.2%에 도달하여 강한 교차 모달 일반화를 보여준다.
- Uni3D는 현장 환경에서 포인트 클라우드 페인팅 및 다중모달 3D 형태 검색과 같은 실용적 응용을 가능하게 한다.
- 프레임워크는 여전히 유연하다: CLIP 교사를 전환하고 다양한 2D/사전학습 모델에서 초기화하는 것이 규모와 함께 일관되게 결과를 개선한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.