[논문 리뷰] Unified Training of Universal Time Series Forecasting Transformers
모이라이(Moirai)는 교차 주파수, 임의 다변수 입력 및 유연한 예측 분포를 처리하도록 LOTSA에서 학습된 마스크 인코더 기반의 보편 시계열 예측 트랜스포머를 도입하여 다양한 데이터셋에서 제로샷 강력한 성능과 경쟁력 있는 풀샷 결과를 달성한다.
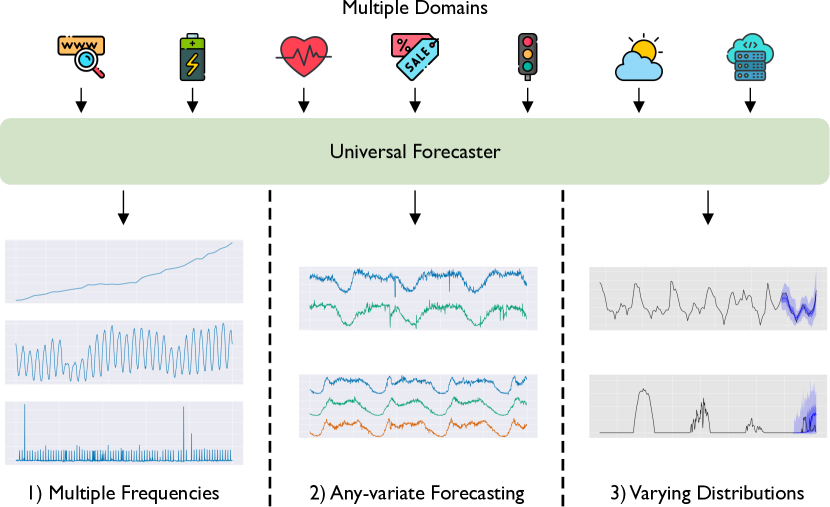
Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, data, and model weights can be found at https://github.com/SalesforceAIResearch/uni2ts.
연구 동기 및 목표
- 한 데이터셋당 하나의 모델 방식에서 보편적이고 사전 학습된 시계열 모델로의 전환을 추진한다.
- 보편적 예측에서 교차 주파수 학습, 임의 다변수 수, 다양한 데이터 분포를 다룬다.
- 유연한 주파수 처리, 임의 다변수 입력, 확률적 출력을 가능하게 하는 아키텍처 및 학습 향상을 개발한다.
- 보편적 예측기를 지원하기 위해 LOTSA를 대규모 오픈 시계열 아카이브로 생성하고 공개한다.
제안 방법
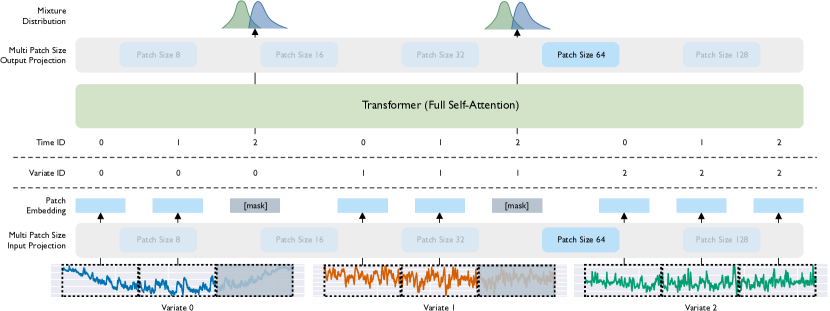
- 다양한 주파수를 다루기 위해 다중 패치 크기의 입력/출력 프로젝션을 갖춘 Masked Encoder 기반의 범용 시계열 예측 트랜스포머(Moirai)를 개발한다.
- 이진 주의 편향과 로터리 위치 임베딩을 통한 다변수 인코딩으로 펼쳐진 다변수 시계열을 처리하기 위해 Any-variate Attention을 도입한다.
- Student의 t, 음이항, 로그정규, 낮은 분산 정규 분포 등의 구성요소를 결합한 혼합 분포를 사용하여 확률적 예측을 수행한다.
- 9개 도메인에 걸친 276억 관측치를 가진 공개 시계열 아카이브 LOTSA에서 Moirai를 사전 학습시키며, 데이터/태스크 분포가 하위 데이터셋과 가변적 컨텍스트/예측 윈도를 샘플링하도록 한다.
- 제로샷 일반화를 가능케 하기 위해 시퀀스 패킹, 다양한 컨텍스트 길이, 베타-이항 다변수 샘플링 등을 포함한 통일된 학습 전략을 적용한다.
실험 결과
연구 질문
- RQ1다양한 데이터(LOTSA)에서 학습된 하나의 대형 시계열 모델이 다수의 데이터셋과 주파수에 대해 제로샷 예측을 수행할 수 있는가?
- RQ2Any-variate Attention, 다중 패치 크기 프로젝션 등 아키텍처 혁신과 혼합 분포가 데이터셋별 모델에 비해 보편적 예측 성능을 향상시키는가?
- RQ3Moirai는 분포 내(in-distribution)와 분포 외(out-of-distribution, 제로샷) 설정에서 전체 샷(baseline) 대비 어떻게 성능을 나타내는가?
- RQ4LOTSA의 규모와 학습 전략(패킹, 태스크 샘플링)이 교차 도메인 일반화에 어떤 영향을 미치는가?
- RQ5길고 짧은 시퀀스 데이터셋에서 컨텍스트 길이가 제로샷 예측 성능에 어떤 영향을 미치는가?
주요 결과
- Moirai 기본 모델과 대형 모델은 보지 않은 데이터셋에서 풀샷 기준과 비교해 경쟁력 있거나 우수한 제로샷 성능을 달성한다.
- Monash 계열 기준선과 비교하면, Moirai는 단일 모델로 다양한 도메인에서 분포 내 평가에 탁월하다.
- Moirai는 다수의 데이터셋에서 강력한 제로샷 확률 예측을 보여 주며, 때로는 최첨단 풀샷 방법을 일치시키거나 능가한다.
- 약간의 제거 실험은 다중 패치 크기, Any-variate Attention, 그리고 확률 예측을 위한 유연한 혼합 분포의 중요성을 보여준다.
- 긴 시퀀스 예측 결과는 Moirai가 변화하는 예측 길이에서도 경쟁력 있게 수행할 수 있음을 시사하며, 모델 크기 효과는 태스크에 따라 미묘하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.