[논문 리뷰] Unifying (Machine) Vision via Counterfactual World Modeling
이 논문은 Counterfactual World Modeling (CWM)을 소개합니다. 구조화된 마스킹과 반사실 프롬프트를 사용하여 0샷 방식으로 여러 시각 계산(예: 핵심점, 광학 흐름, 차폐, 분할, 깊이)을 유도하는 통합된 자가감독 비전 프레임워크입니다.
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
연구 동기 및 목표
- 언어 모델의 제로샷 다재다능함을 닮은 시각용 기초 모델 접근 방식을 고무한다.
- 구조화된 마스킹을 통해 장면의 구조와 동역학을 학습하는 비지도, 통합 예측기를 개발한다.
- 레이블이 없는 데이터를 통해 다양한 시각 계산을 도출하기 위한 반사실 프롬프트를 통한 일반적인 태스크 인터페이스를 가능하게 한다.
- 카운트와 장면 다이나믹의 기하를 반사실 입력을 통해 추출하고 조작할 수 있는 방법을 보여준다.
제안 방법
- 첫 프레임의 대부분과 두 번째 프레임의 일부분을 드러내는 구조화된 마스킹을 사용하여 외관을 다이나믹스로부터 분리하도록 시간적으로 요인화된 마스크 예측기를 학습한다.
- 실제 입력과 수정된 입력(반사실)에 대한 예측을 비교하여 다양한 시각 계산을 도출하기 위해 반사실 프롬프트를 사용한다.
- 핵심점을 재구성 명확도를 극대화하는 패치로 형식화하여 다른 표현을 도출하기 위한 부트스트래핑을 가능하게 한다.
- 광학 흐름, 차폐, 이동 가능한 물체 분할 및 상대 깊이가 예측기의 미분 또는 반사실로 얻어질 수 있음을 시연한다.
- 표현 및 태스크를 확장하기 위해 마스킹 체계와 컨디셔닝(예: 머리 움직임, 다중 프레임 마스킹)을 확장한다.
- 모델의 반사실 미분이 어떻게 효율적이고 제로샷 태스크 인터페이스를 제공하는지 설명한다.
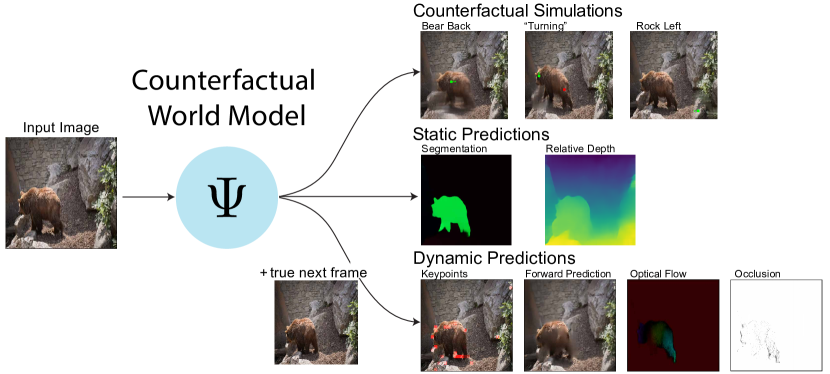
실험 결과
연구 질문
- RQ1구조화된 마스킹을 통해 단일 비지도 시각 모델이 핵심 장면 구조와 다이나믹스를 학습할 수 있는가?
- RQ2반사실 프롬프트가 predictions를 제로샷 솔루션으로 다수의 시각 태스크로 전환할 수 있는가?
- RQ3광학 흐름, 차폐, 분할 및 깊이가 하나의 통합 예측기로부터 도출될 수 있는가?
- RQ4부트스트래핑과 도함수가 다양한 시각 표현을 추출하는 역할은 무엇인가?
- RQ5마스킹 정책의 변화가 학습된 표현과 태스크 커버리지에 어떤 영향을 미치는가?
주요 결과
- 시간적으로 요인화된 마스킹 예측기가 외관을 다이나믹스로부터 분해하는 것을 학습한다.
- 반사실 프롬프트는 같은 모델에서 다중 시각 계산에 대한 제로샷 접근을 제공한다.
- 광학 흐름과 차폐는 예측기의 도함수와 반사실 교란으로부터 도출될 수 있다.
- 핵심점은 재구성 오차를 가장 크게 줄이는 패치로 등장하여 객체 수준 분석을 가능하게 한다.
- 이 프레임워크는 비전의 기초모델 스타일 접근으로 여러 고전적 비전 개념들을 하나로 통합한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.