[논문 리뷰] Universal Planning Networks
UPNs는 목표 조건 정책 내부에 미분 가능 그래디언트 기반 플래너를 내장하여 계획 가능한 잠재 표현을 학습하고, 시각운동 과제에서의 계획, 전이 및 보상 설계를 개선합니다. 이 접근 방식은 이미지 기반 목표 지정과 형태학 간 전이를 가능하게 하며, 잠재 공간은 RL 보상에 usable됩니다.
A key challenge in complex visuomotor control is learning abstract representations that are effective for specifying goals, planning, and generalization. To this end, we introduce universal planning networks (UPN). UPNs embed differentiable planning within a goal-directed policy. This planning computation unrolls a forward model in a latent space and infers an optimal action plan through gradient descent trajectory optimization. The plan-by-gradient-descent process and its underlying representations are learned end-to-end to directly optimize a supervised imitation learning objective. We find that the representations learned are not only effective for goal-directed visual imitation via gradient-based trajectory optimization, but can also provide a metric for specifying goals using images. The learned representations can be leveraged to specify distance-based rewards to reach new target states for model-free reinforcement learning, resulting in substantially more effective learning when solving new tasks described via image-based goals. We were able to achieve successful transfer of visuomotor planning strategies across robots with significantly different morphologies and actuation capabilities.
연구 동기 및 목표
- 시각 입력으로부터 목표 지향적 계획 및 제어에 효과적인 표현을 학습한다.
- 신경 정책 내에 미분 가능한 그래디언트 하강 플래너를 삽입하고 엔드-투-엔드로 학습한다.
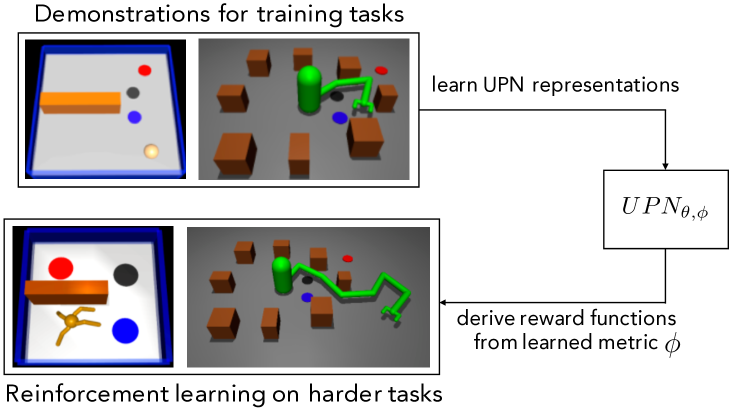
- 학습된 잠재 표현이 이미지 기반 목표 지정 및 형태학 간 전션을 지원함을 시연한다.
- 잠재 공간이 새로운 작업에서 모델 프리 RL에 대해 거리 기반 보상을 제공할 수 있음을 보인다.
제안 방법
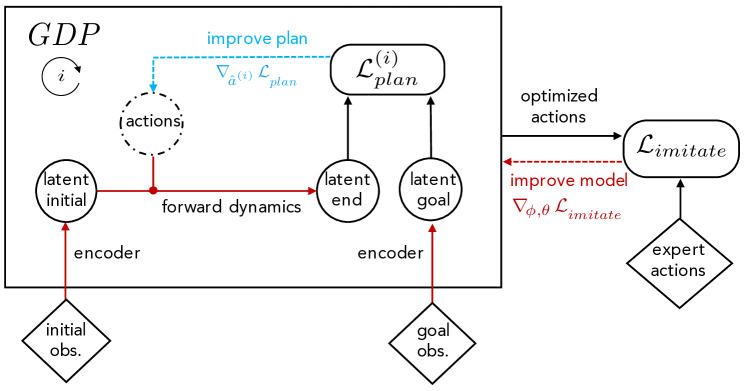
- 현재 관찰과 목표 관찰을 f_phi를 통해 잠재 공간으로 인코딩하고 forward 모델 g_theta로 전이들을 시뮬레이션한다.
- 잠재 공간에서 그래디언트 디센트 플래너(GDP)를 사용하여 인코딩된 목표와의 거리를 최소화하는 행동 시퀀스를 생성한다.
- 전 과정 그래프를 통해 플래닝 그래프의 그래디언트를 역전파하여 phi와 theta를 업데이트한다.
- 전형적 모방 학습 목표로 전문가 시연과 일치하도록 학습한다 (Algorithm 2).
- 테스트 시점에 MPC 스타일 재계획을 사용해 더 긴 시야를 다루도록 선택적으로 재계획한다.
- Huber 로스와 RL 미세조정으로 잠재 공간 보상 r(o_t,o_g) = -||f_phi(o_t)-f_phi(o_g)||^2 을 시연한다.
실험 결과
연구 질문
- RQ1정책 내부에 그래디언트 디센트 플래너를 삽입하는 것이 반응형이나 자기회귀 기반 기준선보다 픽셀로부터의 시각운동 모방 성능이 더 나은가?
- RQ2학습된 잠재 공간이 이미지 기반 목표를 통해 서로 다른 로봇 형태학과 더 복잡한 작업으로의 전이를 지원할 수 있는가?
- RQ3테스트 시점의 플래닝 업데이트가 성능을 향상시키고 전문가 성공에 근접하게 할 수 있는가?
- RQ4새로운 작업에서 모델 프리 RL에 사용할 거리 기반 보상을 정의하는 데 학습된 표현이 유용한가?
주요 결과
| 특징 공간 | 고정 | 다양한 |
|---|---|---|
| RIL-RL | 0% | 0.01% |
| AIL-RL | 0% | 4.72% |
| VAE-RL | 20.23% | 24.67% |
| UPN-160 Imitation | 45.82% | 47.99% |
| Expert | 46.77% | 51.1 % |
| UPN-RL | 69.84% | 71.12% |
- UPN은 기존 모방 학습자보다 데이터가 제한된 상황에서도 효과적인 시각 목표 지향 정책을 더 효율적으로 학습한다.
- 잠재 표현은 의미 있고 장애물 인지적 거리 메트릭을 제공하여 전이 및 보상 설계에 유용하다.
- 테스트 시점에서 더 많은 GDP 업데이트를 허용하면 계획 성능이 향상되고 충분한 시연으로 전문가 수준에 도달할 수 있다.
- 잠재 공간 보상에서 파생된 보상은 RL이 다른 특징 공간(VAE, RIL, AIL)보다 전이 작업에서 더 잘 수행되도록 한다.
- 하나의 형태학에서 학습된 UPN 표현은 보지 않은 형태학 및 더 복잡한 작업에서 RL 성능을 향상시킬 수 있다.
- UPN 유래 보상으로의 강화 학습은 일부 전이 설정에서 전문가 성능을 능가하는 경우가 많다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.