[논문 리뷰] Unlocking the Power of LSTM for Long Term Time Series Forecasting
P-sLSTM를 제안하는 것으로, patching과 채널 독립성을 갖춘 sLSTM 기반의 LSTM-기반 장기 시계열 예측 모델로 메모리 한계를 극복하고 최첨단 성능을 달성합니다.
Traditional recurrent neural network architectures, such as long short-term memory neural networks (LSTM), have historically held a prominent role in time series forecasting (TSF) tasks. While the recently introduced sLSTM for Natural Language Processing (NLP) introduces exponential gating and memory mixing that are beneficial for long term sequential learning, its potential short memory issue is a barrier to applying sLSTM directly in TSF. To address this, we propose a simple yet efficient algorithm named P-sLSTM, which is built upon sLSTM by incorporating patching and channel independence. These modifications substantially enhance sLSTM's performance in TSF, achieving state-of-the-art results. Furthermore, we provide theoretical justifications for our design, and conduct extensive comparative and analytical experiments to fully validate the efficiency and superior performance of our model.
연구 동기 및 목표
- sLSTM이 메모리 용량을 왜 향상시키는지와 시계열 예측에의 적용 가능성을 설명한다.
- sLSTM이 TSF에서 장기 의존성에 대한 장기 기억을 보장하지 못하는 것을 보이고, 이를 patching으로 해결한다.
- P-sLSTM를 도입하여 patching과 channel independence를 TSF에서의 기억력과 효율성을 향상시키는 방법.
- 다양한 실험을 통해 P-sLSTM이 LSTM 및 sLSTM를 능가하고 SOTA 모델과도 경쟁력이 있음을 보여준다.
제안 방법
- Markov 체인 형식을 통해 sLSTM의 메모리 특성과 기하적 ergodicity를 설명한다.
- 다변량 시계열을 독립 채널로 나누고 단변량 패치를 처리하기 위해 patching을 적용함으로써 P-sLSTM을 제안한다.
- 과 채널 독립성을 도입하여 과적합을 줄이고 효율성을 향상시킨다.
- 패치별 예측을 최종 다변량 예측으로 결합하기 위해 선형 프로젝션 파이프라인을 사용한다.
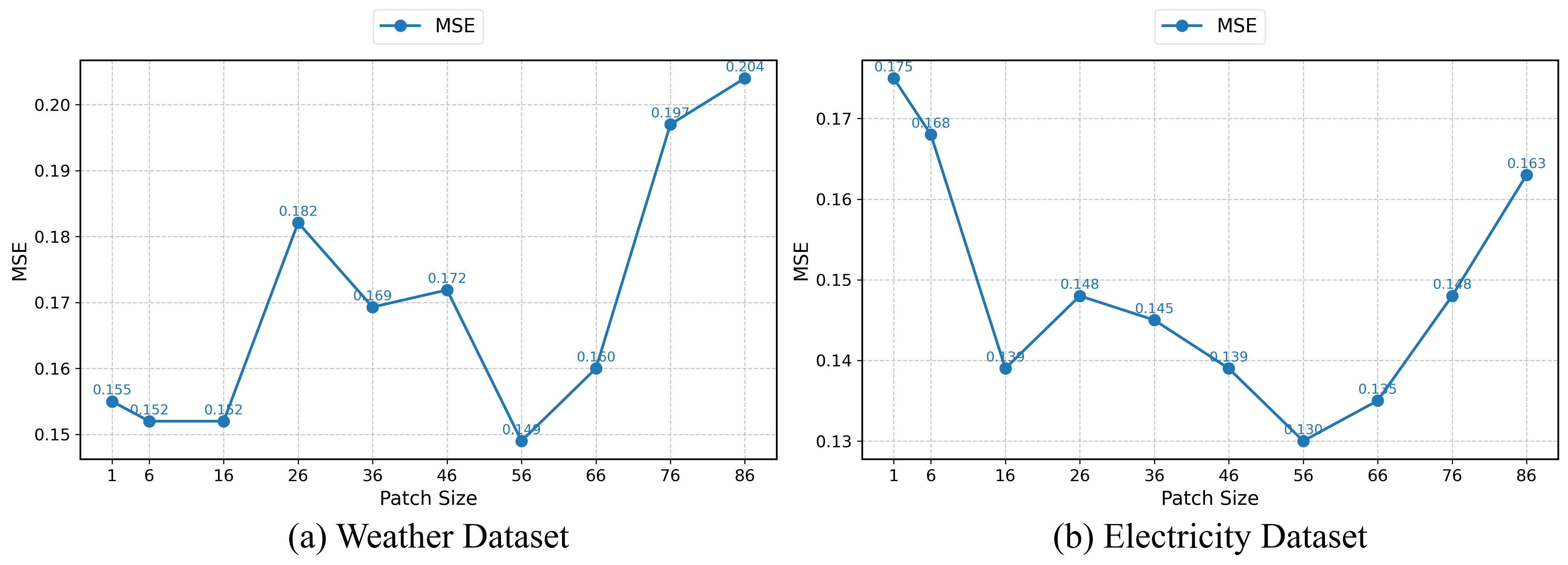
- 다양한 데이터셋에서 MSE/MAE 지표로 P-sLSTM를 다양한 베이스라인과 비교한다.

실험 결과
연구 질문
- RQ1sLSTM이 시계열 예측에서 장기 의존성을 효과적으로 포착할 수 있는가?
- RQ2패칭이 TSF에서 sLSTM의 장기 기억을 회복하거나 향상시키는가?
- RQ3채널 독립성이 RNN 기반 TSF 모델의 예측 정확도를 향상시키고 과적합을 줄이는가?
- RQ4표준 TSF 데이터셋에서 P-sLSTM가 LSTM, sLSTM, Transformer, MLP, SSM 베이스라인에 비해 어떤 성능을 보이는가?
주요 결과
- P-sLSTM은 여러 데이터셋에서 우수한 정확도를 달성하며, 대부분의 설정에서 sLSTM보다 우수하고 일반적으로 LSTM를 능가한다.
- P-sLSTM은 SOTA Transformer/MLP/SSM 모델과 견줄 만한 성능을 얻으면서도 학습 비용이 더 낮다.
- 패칭은 채널 내 세그먼트를 부분적으로 처리하도록 함으로써 장기 의존성을 포착하는 데 도움이 된다.
- 채널 독립성은 채널 혼합 변형에 비해 과적합을 방지하고 일반화를 향상시킨다.
- Ablation studies는 메모리 혼합이 미미한 이득을 제공하고 CI가 학습 오차를 감소시키며 검증/테스트 성능을 향상시킨다는 것을 보여준다.
- P-sLSTM은 보고된 실험에서 경쟁 베이스라인보다 계산 비용이 더 낮음을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.