[논문 리뷰] Unmasked Teacher: Towards Training-Efficient Video Foundation Models
이 논문은 Unmasked Teacher (UMT)를 소개합니다. 이는 라벨이 없는 비디오 마스킹을 CLIP 기반 교사를 통해 안내하고, scratch에서 빠르게 수렴하며 다중모달 능력을 가능하게 하는 훈련 효율적 프레임워크입니다.
Video Foundation Models (VFMs) have received limited exploration due to high computational costs and data scarcity. Previous VFMs rely on Image Foundation Models (IFMs), which face challenges in transferring to the video domain. Although VideoMAE has trained a robust ViT from limited data, its low-level reconstruction poses convergence difficulties and conflicts with high-level cross-modal alignment. This paper proposes a training-efficient method for temporal-sensitive VFMs that integrates the benefits of existing methods. To increase data efficiency, we mask out most of the low-semantics video tokens, but selectively align the unmasked tokens with IFM, which serves as the UnMasked Teacher (UMT). By providing semantic guidance, our method enables faster convergence and multimodal friendliness. With a progressive pre-training framework, our model can handle various tasks including scene-related, temporal-related, and complex video-language understanding. Using only public sources for pre-training in 6 days on 32 A100 GPUs, our scratch-built ViT-L/16 achieves state-of-the-art performances on various video tasks. The code and models will be released at https://github.com/OpenGVLab/unmasked_teacher.
연구 동기 및 목표
- 데이터 희소성 및 높은 계산 비용으로 인해 훈련 효율적인 비디오 기초 모델(VFM)의 필요성을 동기화합니다.
- 교사가 안내하는 마스ed 비디오 마스킹을 사용하여 처음부터 학습하는 확장 가능한 프레임워크를 제안합니다.
- 언마스크드 비디오 토큰을 CLIP 기반 교사와 정렬하여 다중모달 비디오 이해를 가능하게 합니다.
- 공개 데이터로 벤치마크에서 최첨단 성능을 영상 전용 및 영상-언어 벤치마크에서 보여줍니다.
- 이전 웹 규모 접근 방식과 비교하여 훈련 비용 및 배출량을 감소시키는 환경적 이점을 보여줍니다.
제안 방법
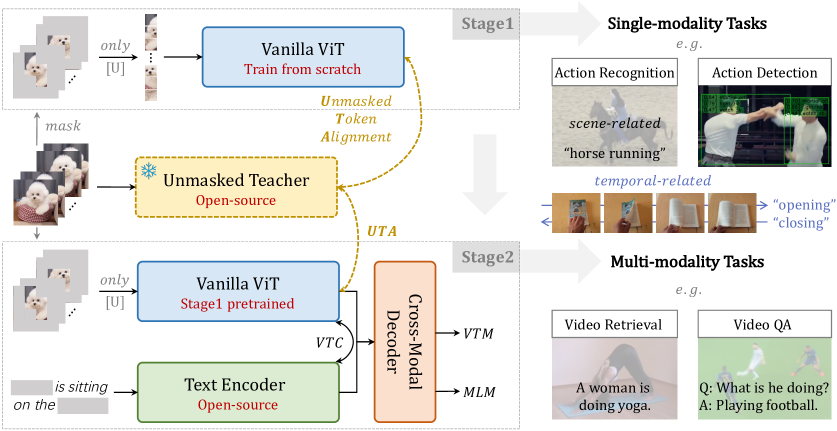
- Image Foundation Model(IFM)을 Unmasked Teacher(UMT)로 사용하여 바닐라 ViT를 처음부터 훈련합니다.
- 비디오 토큰에 대해 높은 80% 의미적 마스킹을 적용하고, 토큰 공간에서 MSE를 통해 마스킹되지 않은 토큰만을 교사와 정렬합니다.
- 프레임 단위 처리를 유지하여 시간적 다운샘플링 없이 프레임-수준의 교사-학생 정렬을 가능하게 합니다.
- 교사 안내 정렬과 학생 처리 모두에서 시공간 주의(attention)를 채택하여 토큰 간 상호 작용을 촉진합니다.
- 점진적 사전 학습 파이프라인을 채택합니다: 단계 1은 UM T를 이용한 비디오 전용 마스킹 모델링; 단계 2는 비전-언어 데이터와 목표를 포함한 다중모달 학습으로 구성합니다.
- 2단계 목표에는 비디오-텍스트 대조( VTC ), 비디오-텍스트 매칭(VTM), 마스킹된 언어 모델링(MLM)이 포함되며, Unmasked Token Alignment(UTA)가 UMT의 핵심 가이드입니다.
![Figure 1 : Comparison with SOTA methods. “ZS” and “FT” refer to “zero-shot” and “fine-tuned”. “T2V” means video-text retrieval. For Kinetics action recognition, [ 86 ] and [ 76 ] are excluded since they utilize model ensemble. With only public sources for pre-training, our approach achieves SOTA per](https://ar5iv.labs.arxiv.org/html/2303.16058/assets/x1.png)
실험 결과
연구 질문
- RQ1마스크된 비디오 모델링을 사용하여 처음부터 훈련 효율적인 VFM을 가능하게 하는 Unmasked Teacher 프레임워크가 가능한가요?
- RQ2CLIP 기반 교사와 마스킹되지 않은 비디오 토큰을 정렬하는 것이 픽셀 재구성이나 전체 모델 전달보다 수렴 및 다중모달 전이 향상에 도움이 되나요?
- RQ3마스킹 전략, 시간 샘플링, 주의 유형이 장면 관련 및 시간 관련 비디오 작업의 성능에 어떠한 영향을 미치나요?
- RQ4공개 데이터와 점진적 사전 학습 구성을 사용한 VFM의 성능 이점과 데이터 효율성은 어느 정도인가요?
- RQ5감소된 계산량으로 제안된 방법이 행동 인식, 로컬라이제이션 및 비디오-언어 벤치마크에서 최첨단 결과를 달성하는 정도는 어느 정도인가요?
주요 결과
- 공개 데이터를 사용하고 32개의 A100 GPU에서 6일 만에 여러 비디오 작업에서 최첨단 결과를 달성합니다(예: K400의 상위 1% 90.6%, AVA의 39.8 mAP, MSRVTT의 R@1 58.8, MSRVTT VQA의 47.1%).
- 의미론적 마스킹을 가진 Unmasked Token Alignment(UTA)가 피실험 재구성 목표 및 단일 재구성 접근법보다 효율성과 정확도 모두에서 뛰어납니다.
- 의미론적 마스킹과 희소 프레임 샘플링 및 마지막 계층 정렬이 무작위 마스킹이나 큰 시간 샘플링보다 더 나은 결과를 냅니다.
- 사전 학습 중 시공간 주의가 결합되어 성능이 향상되며, UMT는 비디오 영역 전이에서 CLIP 교사보다 우수한 성능을 보입니다.
- 비디오 전용에서 비전-언어로의 단계적 점진적 학습은 데이터와 계산을 줄이면서도 강력한 비디오-언어 이해를 가능하게 합니다.
- CoCa와 비교했을 때 UMT는 약 70배의 이산탄소 배출을 줄이면서도 작업 성능은 경쟁력 있거나 우수합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.