[논문 리뷰] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
UP-DETR은 라벨이 없는 이미지에서 새로운 임의 쿼리 패치 탐지 작업을 사용해 DETR 트랜스포머를 사전 학습하며, 사전 학습 중 CNN 백본을 고정시켜 DETR의 수렴 속도와 객체 탐지, 원샷 탐지, 팬오픽 분할에서의 성능을 향상시킨다.
DEtection TRansformer (DETR) for object detection reaches competitive performance compared with Faster R-CNN via a transformer encoder-decoder architecture. However, trained with scratch transformers, DETR needs large-scale training data and an extreme long training schedule even on COCO dataset. Inspired by the great success of pre-training transformers in natural language processing, we propose a novel pretext task named random query patch detection in Unsupervised Pre-training DETR (UP-DETR). Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the input image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade off classification and localization preferences in the pretext task, we find that freezing the CNN backbone is the prerequisite for the success of pre-training transformers. (2) To perform multi-query localization, we develop UP-DETR with multi-query patch detection with attention mask. Besides, UP-DETR also provides a unified perspective for fine-tuning object detection and one-shot detection tasks. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher average precision on object detection, one-shot detection and panoptic segmentation. Code and pre-training models: https://github.com/dddzg/up-detr.
연구 동기 및 목표
- LIMITED 데이터에서 처음부터 시작하기보다 트랜스포머를 사전 학습시켜 DETR의 성능을 개선하려는 동기를 제시한다.
- DETR의 위치 추적 초점에 부합하는 자기지도 사전 텍스트(task)로 임의 쿼리 패치 탐지를 도입한다.
- CNN 백본을 고정하고 분류 특성 vs 위치 특성의 균형을 맞춰 안정적인 사전 학습을 보장한다.
- 같은 사전 학습 모델로 객체 탐지와 원샷 탐지에 대한 통합 미세조정 경로를 가능하게 한다.
- 멀티 쿼리 패치 탐지 및 NMS와 유사한 동작을 모방하기 위한 어텐션 마스킹과 확장의 가능성을 탐색한다.
제안 방법
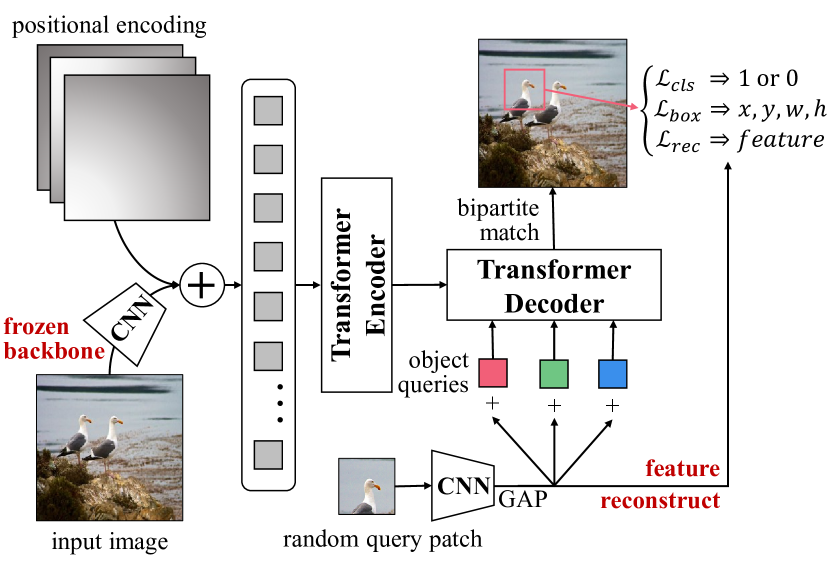
- 라벨이 없는 이미지에서 임의 쿼리 패치 탐지 작업으로 트랜스포머 인코더-디코더를 사전 학습한다.
- 패치 특징을 추출하기 위해 CNN 백본을 사용하고, 쿼리 패치 및 객체 쿼리를 트랜스포머 디코더에 입력해 패치 바운딩 박스를 예측한다.
- 분류, 박스 회귀(L1 + IoU), 선택적 패치 재구성 손실을 결합한 휴르당(Hungarian) 매칭 손실을 사용해 위치 특성/특징을 보존한다.
- 사전 학습 중 CNN 백본을 고정해 특징 구별 능력을 유지하고 효과적인 위치 학습을 가능하게 한다.
- 객체 쿼리를 그룹화하고 그룹 간 상호작용을 제어하는 어텐션 마스크를 적용해 다중 쿼리 패치 탐지를 확장한다.
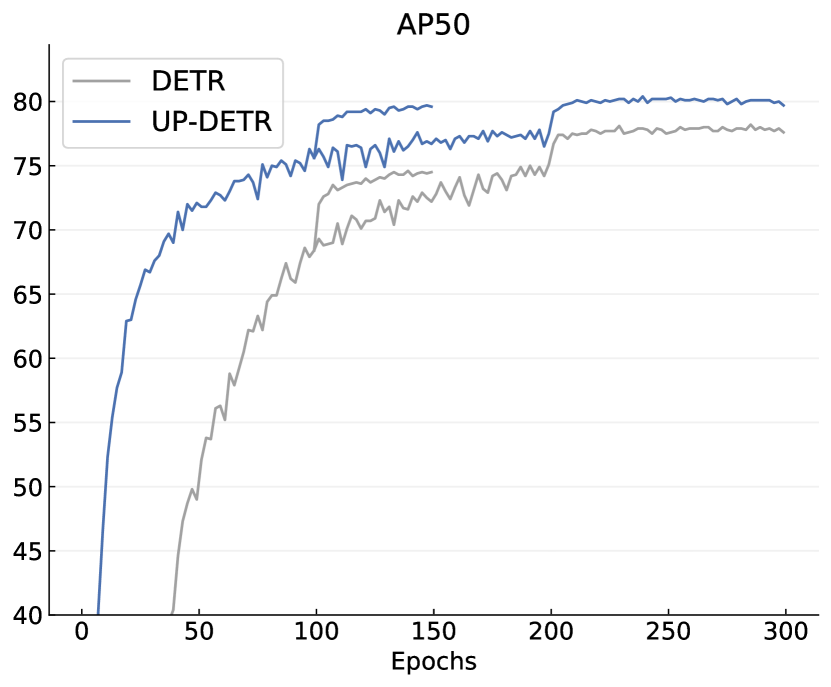
실험 결과
연구 질문
- RQ1무지도 사전 학습이 VOC/COCO 데이터셋에서의 수렴 속도와 탐지 정확도를 처음부터 학습하는 경우보다 향상시키는가?
- RQ2랜덤 쿼리 패치 탐지 사전 텍스트가 고정된 CNN 백본과 함께 DETR의 위치 추적 초점을 더 효과적으로 활용하는가?
- RQ3다중 쿼리 패치 탐지 및 어텐션 마스킹이 쿼리 간 경쟁을 더 잘 반영하고 원샷 탐지 및 팬오픽 분할과 같은 하위 작업을 개선하는가?
- RQ4UP-DETR가 DETR에 비해 원샷 탐지 및 팬오픽 분할로의 전이가 얼마나 잘 이루어지는가?
- RQ5패치 특징 재구성이 위치 학습 중 분류 스타일의 특징 보존에 미치는 영향은 무엇인가?
주요 결과
- UP-DETR은 VOC와 COCO에서 짧은 학습 주기와 긴 학습 주기 모두에서 DETR보다 더 빠르게 수렴하고 더 높은 AP를 달성한다.
- PASCAL VOC에서 고정 백본을 가진 UP-DETR은 DETR보다 최대 +6.2 AP(150 에폭) 및 +7.5 AP(300 에폭)를 달성하여 Faster R-CNN 성능에 근접한다.
- COCO에서 150 에폭의 경우 UP-DETR은 DETR을 약간 능가하고 유사한 스케줄에서 Faster R-CNN과 일치하며, 300 에폭에서 DETR을 상회하고 Faster R-CNN(R50-FPN)보다 약간 앞선 AP를 달성한다.
- 원샷 탐지 결과에서 UP-DETR은 DETR에 비해 크게 향상되어 보이는 설정의 seen/ unseen 클래스 모두에서 상당한 이점을 보인다.
- 팬오픽 분할 결과에서 UP-DETR은 PQ, SQ, RQ 지표에서 DETR보다 개선되며, 더 높은 AP seg 및 관련 팬오픽 점수로 이어진다.
- 消 Abelation reveals that multi-query patches (M=10) outperform single-query patches, and freezing the backbone plus patch feature reconstruction enhances pre-training effectiveness.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.