[논문 리뷰] User-LLM: Efficient LLM Contextualization with User Embeddings
User-LLM은 다중 모달 사용자 상호작용을 컴팩트 임베딩으로 축약하고 이를 LLM에 크로스 어텐션으로 교차 주시하여, 전체 LLM 재학습 없이도 효율적이고 긴 맥락의 개인화를 가능하게 한다.
Large language models (LLMs) have achieved remarkable success across various domains, but effectively incorporating complex and potentially noisy user timeline data into LLMs remains a challenge. Current approaches often involve translating user timelines into text descriptions before feeding them to LLMs, which can be inefficient and may not fully capture the nuances of user behavior. Inspired by how LLMs are effectively integrated with images through direct embeddings, we propose User-LLM, a novel framework that leverages user embeddings to directly contextualize LLMs with user history interactions. These embeddings, generated by a user encoder pretrained using self-supervised learning on diverse user interactions, capture latent user behaviors and interests as well as their evolution over time. We integrate these user embeddings with LLMs through cross-attention, enabling LLMs to dynamically adapt their responses based on the context of a user's past actions and preferences. Our approach achieves significant efficiency gains by representing user timelines directly as embeddings, leading to substantial inference speedups of up to 78.1X. Comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate that User-LLM outperforms text-prompt-based contextualization on tasks requiring deep user understanding, with improvements of up to 16.33%, particularly excelling on long sequences that capture subtle shifts in user behavior. Furthermore, the incorporation of Perceiver layers streamlines the integration between user encoders and LLMs, yielding additional computational savings.
연구 동기 및 목표
- 다양한 상호작용에서 얻은 압축된 사용자 표현을 활용해 personalized LLM를 동기부여한다.
- 두 단계 프레임워크를 제시한다: (1) 임베딩을 생성하는 사용자 인코더를 사전 학습, (2) 임베딩을 LLM에 크로스 어텐션이나 소프트 프롬프트로 통합.
- 다양한 데이터셋에서 장문의 시퀀스 및 다중 모달 데이터에 대해 효율성과 확장성을 시연.
- 임베딩 기반 개인화와 텍스트 프롭프트 baselines 및 전체 파인튜닝을 포함한 파라미터 효율적 학습 전략과 비교.
제안 방법
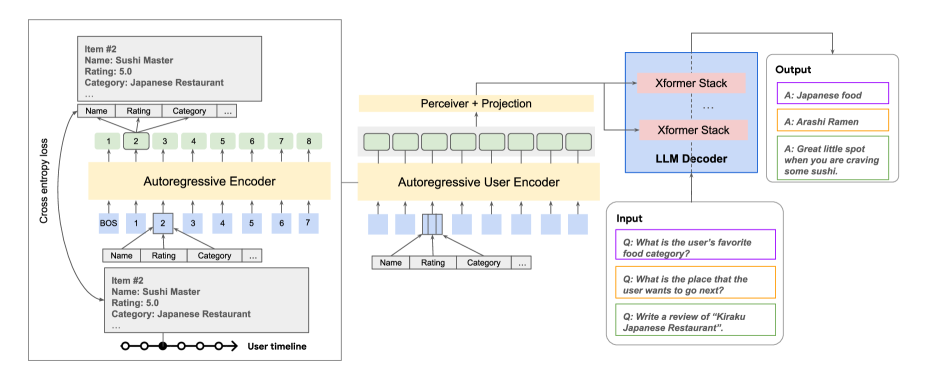
- 다중 모달 사용자 이력을 대상으로 트랜스포머 기반 자기회귀 사용자 인코더를 학습해 이벤트별 밀집 임베딩을 산출한다.
- 두 개 이상의 모달리티에서 얻은 임베딩을 하나의 사용자 임베딩 시퀀스로 융합한다.
- 크로스 어텐션(또는 소프트 프롬프트)을 통해 LLM과 사용자 임베딩을 통합해 생성 및 예측을 조건화한다.
- Perceiver 계층으로 임베딩을 압축하고 LLM의 어텐션 부하를 줄여 효율성을 높인다.
- 네 가지 학습 전략을 탐구한다: Full 파인튜닝, Enc(LLM 동결), LoRA, Proj(LLM 및 인코더 동결).
- PaLM-2 XXS를 LLM으로, 6-레이어, 128-차원 트랜스포머를 사용자 인코더로 사용하며, 교차 어텐션 vs 소프트 프론트 융합을 연구한다.
실험 결과
연구 질문
- RQ1다중 모달 상호작용에서 추출된 사용자 임베딩이 텍스트 프롬프트보다 더 효율적으로 LLM 개인화를 개선할 수 있는가?
- RQ2크로스 어텐션과 소프트 프론트 융합은 LLM에 사용자 임베딩을 통합하는 데 어떻게 비교되는가?
- RQ3긴 이력에서 사용자 임베딩과 Perceiver 압축을 사용할 때 FLOPs 및 컨텍스트 길이 측면의 효율성 향상은 어느 정도인가?
- RQ4사전 학습된 사용자 인코더가 다음 항목 예측 외의 작업(장르 예측, 리뷰 생성 등)에서도 일반화되는가?
- RQ5다양한 학습 전략(Full, Enc, LoRA, Proj)이 성능 및 파라미터 효율성에 미치는 영향은 무엇인가?
주요 결과
| 데이터셋 | Rec | Baseline | User-LLM | MovieLens20M @1 | MovieLens20M @5 | MovieLens20M @10 | Google Review @1 | Google Review @5 | Google Review @10 | Amazon Review @1 | Amazon Review @5 | Amazon Review @10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MovieLens20M | @1 | 0.044 | 0.038 | 0.054 | ||||||||
| MovieLens20M | @5 | 0.135 | 0.135 | 0.164 | ||||||||
| MovieLens20M | @10 | 0.206 | 0.158 | 0.243 | ||||||||
| Google Review | @1 | 0.005 | 0.005 | 0.015 | ||||||||
| Google Review | @5 | 0.012 | 0.019 | 0.052 | ||||||||
| Google Review | @10 | 0.023 | 0.033 | 0.071 | ||||||||
| Amazon Review | @1 | 0.021 | 0.034 | 0.037 | ||||||||
| Amazon Review | @5 | 0.026 | 0.051 | 0.047 | ||||||||
| Amazon Review | @10 | 0.031 | 0.062 | 0.051 |
- User-LLM은 MovieLens 및 Google Local Review에서 다음 아이템 예측 성능에서 비-LMM 베이스라인을 능가한다; Amazon Review는 데이터셋 희소성의 영향을 강조하며 Bert4Rec를 선호한다.
- 임베딩 기반 컨텍스트 처리는 입력 시퀀스 길이에 관계없이 LLM이 고정 길이 프롬프트(32 토큰)를 처리하도록 하며, 텍스트 프롬프트 baselines에 비해 상당한 FLOPs 감소(최대 78.1배)를 달성한다.
- 사전 학습된 사용자 인코더는 무작위로 초기화된 것보다 일관된 이점을 제공한다 across tasks.
- 크로스 어텐션 융합은 일반적으로 소프트 프롟트 융합보다 더 나은 성능을 보이며, 특히 리뷰 생성 작업에서 그렇다.
- 인코더와 투영 층만 파인튜닝하는 Enc 방식은 전체 파인튜닝보다 훨씬 적은 파라미터로 경쟁력 있는 성능을 제공하며 LLM의 지식을 보존한다.
- Perceiver 기반 압축은 임베딩 토큰 수를 줄이면서도 성능 저하를 최소화하여 추론 효율을 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.