[논문 리뷰] Using Imperfect Surrogates for Downstream Inference: Design-based Supervised Learning for Social Science Applications of Large Language Models
이 논문은 디자인 기반 감독 학습(DSL)을 소개하며, LLM에서 얻은 불완전한 대리 라벨과 소량의 gold-standard 라벨 서브셋을 결합하여 사회 과학 회귀에서 유효한 하위 추론을 가능하게 하는 이중 강건한(Doubly Robust) 방법입니다. 대리 라벨이 편향되어 있어도 일관성, 점근적 정상성 및 유효한 신뢰 구간을 보장합니다.
In computational social science (CSS), researchers analyze documents to explain social and political phenomena. In most scenarios, CSS researchers first obtain labels for documents and then explain labels using interpretable regression analyses in the second step. One increasingly common way to annotate documents cheaply at scale is through large language models (LLMs). However, like other scalable ways of producing annotations, such surrogate labels are often imperfect and biased. We present a new algorithm for using imperfect annotation surrogates for downstream statistical analyses while guaranteeing statistical properties -- like asymptotic unbiasedness and proper uncertainty quantification -- which are fundamental to CSS research. We show that direct use of surrogate labels in downstream statistical analyses leads to substantial bias and invalid confidence intervals, even with high surrogate accuracy of 80-90%. To address this, we build on debiased machine learning to propose the design-based supervised learning (DSL) estimator. DSL employs a doubly-robust procedure to combine surrogate labels with a smaller number of high-quality, gold-standard labels. Our approach guarantees valid inference for downstream statistical analyses, even when surrogates are arbitrarily biased and without requiring stringent assumptions, by controlling the probability of sampling documents for gold-standard labeling. Both our theoretical analysis and experimental results show that DSL provides valid statistical inference while achieving root mean squared errors comparable to existing alternatives that focus only on prediction without inferential guarantees.
연구 동기 및 목표
- 불완전한 대리 라벨(예: LLM 출력)을 사회과학의 하위 통계 분석에서 사용하여 유효한 추론을 보장하면서 동기를 부여하고 formalize한다.
- 대리 라벨의 편향 여부와 상관없이 일관성과 올바른 커버리지를 달성하는 편향 보정된 디자인 기반 추정기를 개발한다.
- 골드 표준 라벨링의 알려진 샘플링 확률 하에서 일관성, 점근적 정상성, 유효한 신뢰구간(CIs)에 대한 이론적 보장을 제공한다.
- DSL의 바이어스 제어 및 경쟁력 있는 효율성을 보여주는 18개 실제 데이터셋에 걸친 실험적 성능을 Demonstrate한다.
제안 방법
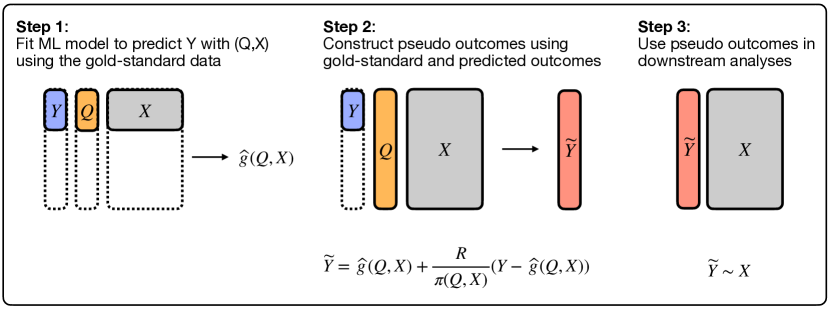
- 대리 Q, 골드 표준 Y, 공변량 X, 및 샘플링 지시자 R과 알려진 확률 pi(Q,W,X)를 가지는 데이터 생성 설정을 정의한다.
- K-fold 교차 적합을 사용하여 편향 보정 의사-결과 tilde{Y}_i^k = hat{g}_k(Q_i,W_i,X_i) + (R_i/pi(Q_i,W_i,X_i))(Y_i - hat{g}_k(Q_i,W_i,X_i))를 도입한다.
- 의사-결과를 사용하는 로지스틱 회귀 모멘트를 풀어준다: sum_k sum_{i in D_k} (tilde{Y}_i^k - expit(X_i^T beta)) X_i = 0.
- Assumption 1 하에서 DSL 추정치 beta_hat의 일관성과 점근적 정상성을 보이고 일관된 분산 추정량 V_hat을 얻을 수 있음을 증명한다.
- 다수의 대리 라벨과 모멘트 추정기를 허용하는 디자인 기반 모멘트들로 확장한다(Definition 2, Equation 7).
- DSL을 Surrogate Only (SO), Gold-Standard Only (GSO), 및 Supervised Learning (SL)과 18개 데이터셋에서 벤치마킹하여 DSL이 유효한 커버리지를 달성하고 RMSE에서 경쟁력을 보임을 보인다.
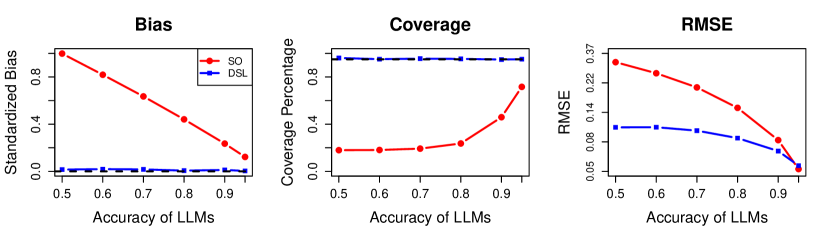
실험 결과
연구 질문
- RQ1불완전한 대리 라벨을 사용하여도 하위 회귀 분석에서 유효한 통계적 추론을 수행할 수 있는가?
- RQ2알려진 골드-스탠다드 샘플링 확률 하에서 대리 모델이 편향되더라도 편향 보정 의사-결과가 일관성과 점근적 정상성을 보일 수 있는가?
- RQ3다양한 사회과학 데이터셋에서 DSL은 편향, 커버리지, RMSE 면에서 SO, GSO, SL과 어떻게 비교되는가?
- RQ4로지스틱 회귀를 넘어 모멘트 기반 추정기의 광범위한 클래스에도 이 방법을 확장할 수 있는가?
주요 결과
- 대리 라벨을 사용하되 편향 보정 의사-결과를 활용하면 하위 회귀 계수에 대해 DSL이 일관성과 점근적 정상성을 제공한다.
- DSL 분산 추정기가 일관되며 대리 모델의 올바른 사양 여부를 요구하지 않고도 유효한 신뢰 구간을 제공한다.
- 골드 표준 라벨링 확률이 알려져 있고 0보다 멀리 떨어져 있는 한 대리 라벨이 임의로 편향되어 있어도 DSL은 여전히 유효하다.
- 18개 데이터셋에 걸친 실험 결과는 DSL이 작은 바이어스와 명목상 또는 거의 명목상의 커버리지를 달성하고, RMSE가 예측 중심 대안과 비슷하거나 골드-표준 기반 벤치마크보다 개선되는 모습을 보인다.
- 대리 라벨의 정확도가 높아질수록 DSL의 효율성이 향상되며, 대리 라벨의 품질이 높을수록 RMSE에 큰 이득이 나타난다.
- 이 프레임워크는 다중 대리 라벨과 디자인 기반 모멘트 확장을 지원하여 일반적인 사회과학 추정기에 넓게 적용 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.