[논문 리뷰] Using Large Language Models to Generate JUnit Tests: An Empirical Study
본 연구는 Codex, GPT-3.5-Turbo, StarCoder를 사용하여 Java의 제로샷 JUnit5 테스트 생성을 평가하고, HumanEval 및 SF110 벤치마크에서의 컴파일, 정답성, 커버리지, 테스트 냄새 및 다양한 맥락 스타일의 영향을 분석합니다.
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning for a strongly typed language like Java. To fill this gap, we investigated how well three models (Codex, GPT-3.5-Turbo, and StarCoder) can generate unit tests. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the effect of context generation on the unit test generation process. We evaluated the models based on compilation rates, test correctness, test coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.
연구 동기 및 목표
- 제로샷 LLM이 Java 클래스에 대해 JUnit 테스트를 얼마나 잘 생성할 수 있는지 평가한다.
- 테스트 생성을 좌우하는 다양한 맥락 입력(예: JavaDocs, 메서드 시그니처)의 효과를 조사한다.
- 컴파일, 정답성, 커버리지 및 냄새 지표 측면에서 LLM이 생성한 테스트와 Evosuite를 비교한다.
- LLM이 생성한 테스트에서 일반적인 테스트 냄새를 특성화하고 그 발생을 파악한다.
- 코드 생성 모델을 사용한 테스트 주도 개발에 대한 시사점을 논의한다.
제안 방법
- 세 가지 LLM(Codex, GPT-3.5-Turbo, StarCoder)을 사용하여 Java HumanEval 데이터셋과 SF110 벤치마크의 MUT에 대한 JUnit5 테스트를 생성한다.
- 테스트 대상 클래스 및 필요한 JUnit 임포트를 포함하는 프롬프트와 컨텍스트를 생성하여 테스트 가능 메서드당 하나의 테스트 파일을 생성한다.
- 생성된 테스트의 컴파일 이슈를 해결하기 위한 휴리스틱 수정 적용 및 수정 후 컴파일 비율 측정한다.
- JaCoCo로 라인/브랜치 커버리지 및 정답성을 프로덕션 코드의 정답성 가정하에 평가한다.
- 생성된 테스트와 Evosuite/수동 기준선에서 TsDetect로 테스트 냄새를 탐지한다.
- RQ1(전반적 테스트 생성 성능)과 RQ2(맥락 요소의 영향)에 초점을 맞춘 두 가지 실험을 수행한다.
- 컴파일의 근본 원인을 컴파일 오류를 클러스터링하여 공통 실패 모드를 식별한다.
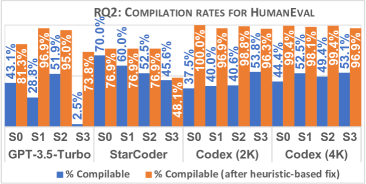
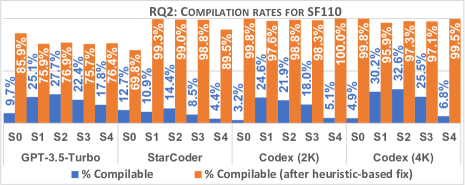
실험 결과
연구 질문
- RQ1RQ1: 선택한 벤치마크에서 LLM이 Java MUT에 대한 JUnit 테스트를 얼마나 잘 생성할 수 있는가?
- RQ2RQ2: 프롬프트의 서로 다른 컨텍스트 요소가 테스트 생성에서 LLM의 성능에 어떤 영향을 미치는가?
- RQ3LLM이 생성한 테스트가 컴파일, 정답성, 커버리지 및 냄새 측면에서 Evosuite와 어떻게 비교되는가?
주요 결과
- Codex는 HumanEval에서 80% 이상 커버리지를 달성했으나, 수정 이전에 SF110에서 어떤 모델도 2%의 커버리지를 넘지 못했다.
- 휴리스틱 수정 적용 후 데이터셋 전반에서 컴파일 비율이 평균적으로 41% 증가했다.
- StarCoder가 SF110에서 가장 높은 컴파일 가능한 테스트 비율(12.7%)을 보였으나 수정으로 인한 개선은 모델에 따라 다르게 나타났다.
- HumanEval에서 수정 후 StarCoder 테스트의 70%가 컴파일되었고; Codex (2K)는 37.5%에서 100%로, Codex (4K)는 44.4%에서 99.4%로 개선되었다.
- SF110에서 수정 전 컴파일 비율은 일반적으로 낮았으며(2.7%–12.7%), 수정 후 약 81% 증가했고; Evosuite는 설계상 100% 컴파일 가능을 달성했다.
- 정답성 비율은 비교적 낮았고: HumanEval에서 StarCoder는 약 81% 정답; 다른 모델은 Codex 변형에서 41–77% 범위였고; SF110 정답성은 더 낮아 최상은 StarCoder의 약 51.9% 정답.
- HumanEval 커버리지: Codex(4K)가 87.7% 라인 커버리지와 92.8% 브랜치 커버리지를 달성; Evosuite 및 수동 테스트가 경우에 따라 더 높은 커버리지를 보였다.
- SF110 커버리지는 LLM 전반에 걸쳐 상당히 낮았고(≤약 2%), Evosuite가 LLM보다 큰 차이로 우수했다.
- LLM이 생성한 테스트에서 테스트 냄새가 만연했으며 특히 매직 넘버(MNT)와 어설션 루렛(Roulette, AR)이 두드러졌다; SF110에서 StarCoder는 냄새 발생률이 특히 높았고(최소 하나의 냄새 포함 비율 96.7%).
- 맥락 시나리오(JavaDoc 존재 여부, 구현 가용성)가 컴파일 및 정답성에 영향을 미쳤고; GPT-3.5-Turbo는 특정 시나리오 구성에서 급격한 하락을 보인 반면, Codex와 StarCoder는 서로 다르게 반응했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.