[논문 리뷰] V2X-Boosted Federated Learning for Cooperative Intelligent Transportation Systems with Contextual Client Selection
이 논문은 차량 네트워크에서 연합학습을 위한 4단계 맥락적 클라이언트 선택 파이프라인을 제시하고, V2X 데이터를 사용하여 미래 네트워크 지연을 예측하며, 데이터 분포에 따라 클라이언트를 클러스터링하고, 비 iid 설정에서 FL 성능을 향상시키기 위해 저지연 클라이언트를 선택합니다.
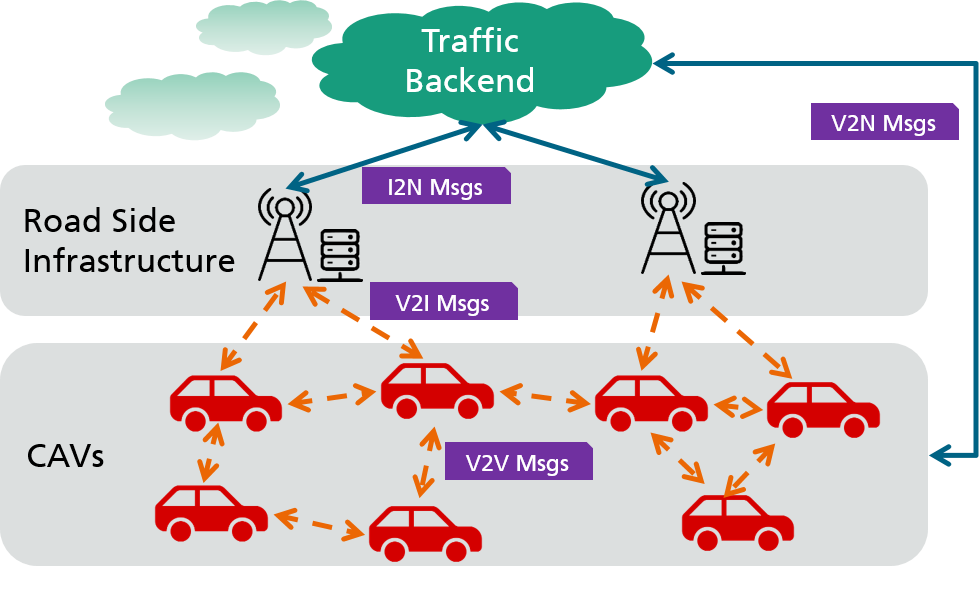
Machine learning (ML) has revolutionized transportation systems, enabling autonomous driving and smart traffic services. Federated learning (FL) overcomes privacy constraints by training ML models in distributed systems, exchanging model parameters instead of raw data. However, the dynamic states of connected vehicles affect the network connection quality and influence the FL performance. To tackle this challenge, we propose a contextual client selection pipeline that uses Vehicle-to-Everything (V2X) messages to select clients based on the predicted communication latency. The pipeline includes: (i) fusing V2X messages, (ii) predicting future traffic topology, (iii) pre-clustering clients based on local data distribution similarity, and (iv) selecting clients with minimal latency for future model aggregation. Experiments show that our pipeline outperforms baselines on various datasets, particularly in non-iid settings.
연구 동기 및 목표
- 협력 ITS(C-ITS)를 위한 연합학습의 데이터 및 네트워크 이질성 해결.
- V2X 메시지를 활용해 미래 네트워크 지연 및 도로 토폴로지를 예측.
- 로컬 데이터 분포 유사성으로 클라이언트를 클러스터링해 비 iid 효과를 줄임.
- 대표적이고 저지연인 클라이언트를 선택해 집계 효율성과 수렴 속도 향상.
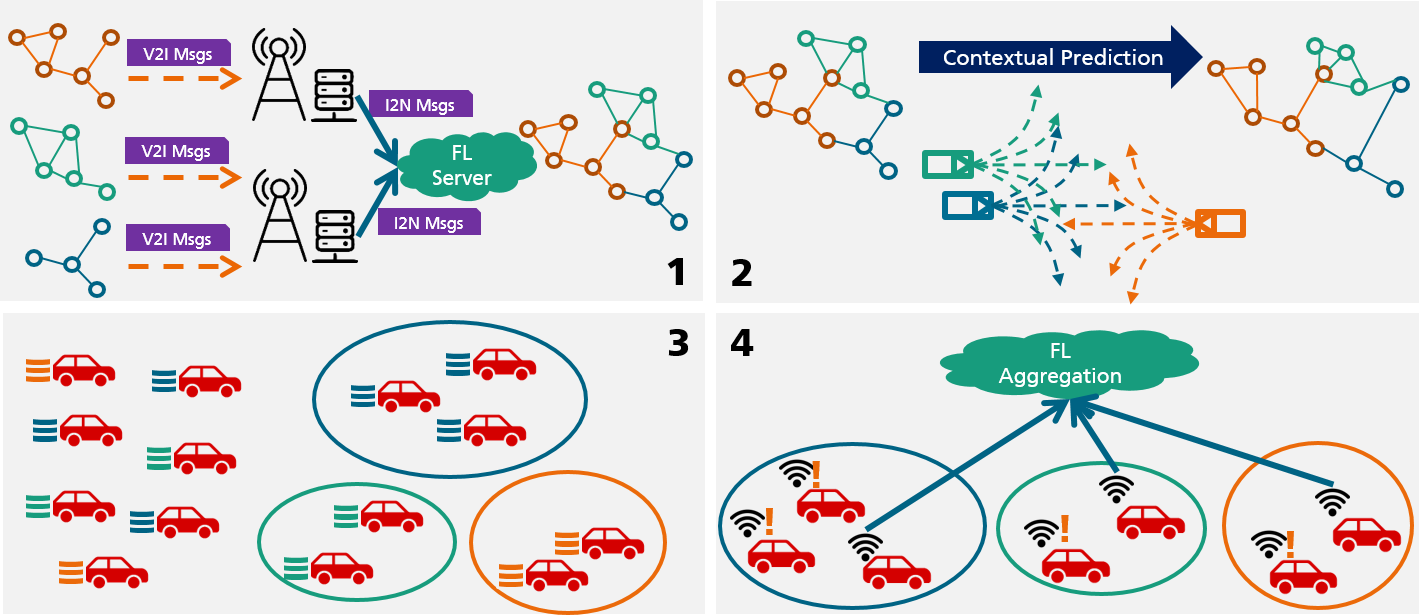
제안 방법
- CAM/CPM V2X 메시지를 융합해 도로 교통 토폴로지 그래프(RTTG)를 구성.
- 향후 RTTG를 예측해 다가오는 라운드의 각 클라이언트 연결 품질을 추정.
- 데이터 수준 클러스터링을 위해 그래디언트/파라미터 유사도로 클라이언트를 데이터 분포 유사성으로 그룹화.
- 예측된 RTTG 지연과 Fast-gamma 규칙을 사용해 각 클러스터에서 소규모의 저지연 클라이언트 집합을 선택해 집계.
- 비 iid MNIST, CIFAR-10, 및 SVHN가 100대 차량에 분포된 상황에서 그리디, 가십, 데이터 기반, 네트워크 기반 기준선과 비교 평가.
실험 결과
연구 질문
- RQ1V2X 정보를 어떻게 융합하고 활용해 차량 네트워크의 연합학습에서 미래 지연을 예측할 수 있는가?
- RQ2데이터 수준 및 네트워크 수준의 맥락적 클라이언트 선택이 CAV 간 비 iid 데이터에서 FL 성능을 향상시킬 수 있는가?
- RQ3맥락적 선택 프레임워크가 정확도 수렴 및 통신 효율성 측면에서 표준 기준선과 어떻게 비교되는가?
- RQ4다양한 네트워크 연결 속도와 데이터 이질성에 대해 접근 방식이 얼마나 견고한가?
주요 결과
- 맥락적 클라이언트 선택이 비 iid 설정에서 MNIST, CIFAR-10, SVHN에 대해 네 가지 기준선(그리디, 가십, 데이터 기반, 네트워크 기반)을 능가한다.
- 연구 방식은 수렴 속도를 가속화하며, 0.5 정확도 도달까지의 시간 감소가 다양한 연결 속도에서 기준선보다 20배 이상이다.
- 데이터 이질성이 존재하더라도 네트워크 기반 전략보다 더 안정적인 수렴을 보인다.
- 연결된 클라이언트 비율이 20%까지 떨어져도 성능 이점이 지속된다.
- 실험은 테스트 정확도에서 일관되게 우수하고 비 iid 데이터 분포에 대한 강건성을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.