[논문 리뷰] VerifAI: Verified Generative AI
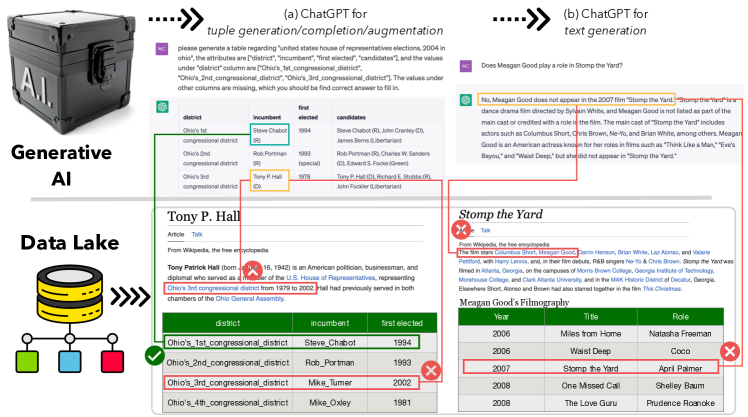
VerifAI는 멀티모달 데이터 레이크를 검색하고 추론하여 생성형 AI 출력의 신뢰성을 높이는 모듈식 프레임워크를 제시합니다. 이는 tuple, table, text 출력에 대한 신뢰성을 개선합니다.
Generative AI has made significant strides, yet concerns about the accuracy and reliability of its outputs continue to grow. Such inaccuracies can have serious consequences such as inaccurate decision-making, the spread of false information, privacy violations, legal liabilities, and more. Although efforts to address these risks are underway, including explainable AI and responsible AI practices such as transparency, privacy protection, bias mitigation, and social and environmental responsibility, misinformation caused by generative AI will remain a significant challenge. We propose that verifying the outputs of generative AI from a data management perspective is an emerging issue for generative AI. This involves analyzing the underlying data from multi-modal data lakes, including text files, tables, and knowledge graphs, and assessing its quality and consistency. By doing so, we can establish a stronger foundation for evaluating the outputs of generative AI models. Such an approach can ensure the correctness of generative AI, promote transparency, and enable decision-making with greater confidence. Our vision is to promote the development of verifiable generative AI and contribute to a more trustworthy and responsible use of AI.
연구 동기 및 목표
- 생성형 AI 출력의 검증을 위한 데이터 관리 관점을 촉진한다.
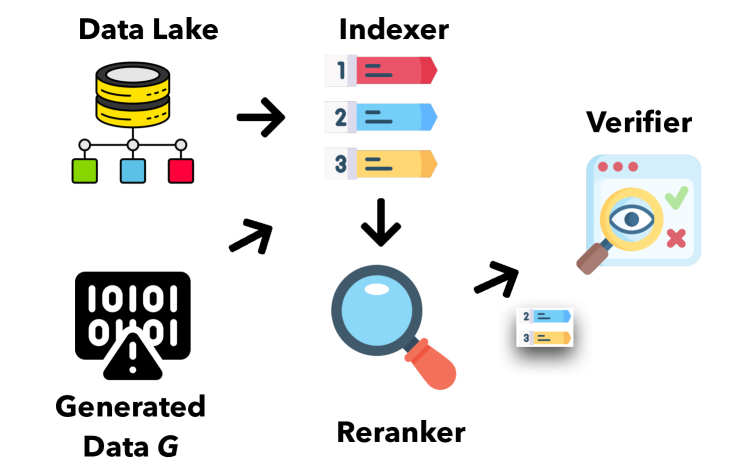
- 데이터 레이크 증거에 대해 생성된 데이터를 색인화하고 재랭킹하며 검증할 수 있는 모듈식 프레/framework를 개발한다.
- 튜플 및 텍스트 검증에 대한 예비 실험으로 가능성을 시연한다.
- 교차 모달 데이터 발견 및 검증의 개방형 문제와 도전을 강조한다.
제안 방법
- 다중 모달 데이터를 다루기 위해 콘텐츠 기반(Elasticsearch) 및 벡터 기반(Faiss) 인덱싱을 갖춘 인덱서.
- 정밀하고 작업별 랭킹을 제공하는 재랭커 (ColBERT를 통한 text-text; OpenTFV를 통한 text-table).
- 일반 모델(예: ChatGPT)과 로컬화된 모델을 모두 포함한 검증기 앙상블( OpenTFV/PASTA로 표 검증, RoBERTa 기반 튜플 검증).
- 0/1/2 라벨(verified, refuted, not related)을 갖는 (g, x) 매핑을 사용한 증거 기반 검증.
- 인증 계보를 추적하고 사람의 디버깅을 지원하기 위한 출처 관리.
- 데이터 레이크에서 검색된 데이터를 사용하여 생성된 표와 텍스트 검증을 검증하는 실험적 설정.
실험 결과
연구 질문
- RQ1모듈식 검증기(Indexer-Reranker-Verifier)가 데이터 레이크 증거를 사용하여 생성형 AI의 출력들을 신뢰성 있게 검증하거나 반박할 수 있는가?
- RQ2다중 모달 데이터 레이크가 생성된 튜플, 표, 텍스트 주장에 대한 검증을 어떻게 지원하는가?
- RQ3다양한 모달리티에서 일반 모델과 로컬화된 검증 모델의 상대적 성능은 어떠한가?
- RQ4생성형 AI 출력의 검증에서 실질적인 도전 과제(개인정보 보호, 신뢰성, 출처 관리)는 무엇인가?
주요 결과
| Generated data type | Retrieved data type | Recall |
|---|---|---|
| 튜플 | 튜플 | 0.99 |
| 텍스트 | 텍스트 파일 | 0.58 |
| 텍스트 주장 | 표 | 0.88 |
- VerifAI는 검증 작업에 대해 관련 데이터를 검색하는 데 높은 재현율을 달성한다(튜플-투-튜플 0.99, 텍스트-투-텍스트 0.58, 텍스트 주장-표 0.88).
- Verifier로서의 ChatGPT는 (tuple, tuple) 검증에서 0.88 정확도를 달성할 수 있으며 일부 텍스트-표 시나리오에서 특정 전문 모델보다 우수하다; 관련 표가 검색될 때 (text, table) 검증에서 PASTA가 ChatGPT를 능가할 수 있다.
- 텍스트 주장 검증은 검색된 표의 이점을 얻고, 일부 관련 케이스에서 PASTA가 ChatGPT를 능가하는 반면, 많은 표가 무관할 때는 ChatGPT가 더 잘 일반화한다.
- 본 연구는 데이터 소스의 출처 관리와 신뢰성의 중요성을 강조하고, 교차 모달 발견 및 검증을 핵심 개방 문제로 식별한다.
- 검색은 (tuple, tuple) 및 (textual claim, table)에 대해 효과적임을 보이고, tuple-backed 증거에 연결될 때 텍스트-파일 검색은 성능이 약하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.