[논문 리뷰] VerilogEval: Evaluating Large Language Models for Verilog Code Generation
이 논문은 VerilogEval을 소개합니다. Verilog 코드 생성 평가를 위한 Verilog-focused 벤치마크(156 HDLBits 문제)로, 자동 테스트 파이프라인과 성능 향상을 위한 합성 감독 미세조정 데이터(synthetic supervised fine-tuning data)를 포함합니다.
The increasing popularity of large language models (LLMs) has paved the way for their application in diverse domains. This paper proposes a benchmarking framework tailored specifically for evaluating LLM performance in the context of Verilog code generation for hardware design and verification. We present a comprehensive evaluation dataset consisting of 156 problems from the Verilog instructional website HDLBits. The evaluation set consists of a diverse set of Verilog code generation tasks, ranging from simple combinational circuits to complex finite state machines. The Verilog code completions can be automatically tested for functional correctness by comparing the transient simulation outputs of the generated design with a golden solution. We also demonstrate that the Verilog code generation capability of pretrained language models could be improved with supervised fine-tuning by bootstrapping with LLM generated synthetic problem-code pairs.
연구 동기 및 목표
- Verilog 코드 생성을 위한 도메인 특화 벤치마크를 HDLBits 문제를 활용하여 명확한 정답 기준과 함께 동기부여합니다.
- 생성된 Verilog 코드의 기능적 정확성을 평가하기 위한 자동화된 테스트 환경을 제공합니다.
- LLMs가 생성한 합성 감독 미세조정 데이터가 Verilog 코딩 성능을 향상시킬 수 있음을 보여줍니다.
- 모델 크기와 기본 모델이 Verilog 코딩 능력과 SFT 효과에 미치는 영향을 조사합니다.
제안 방법
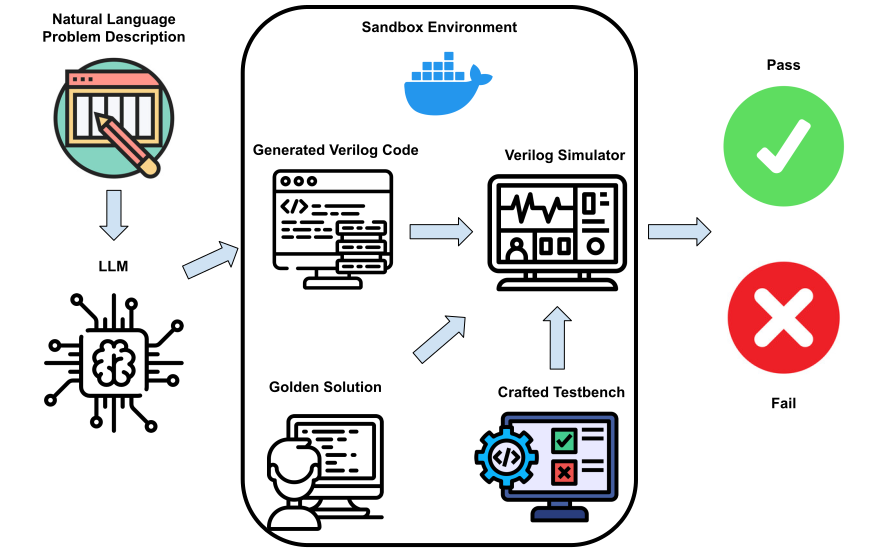
- HumanEval을 모방한 샌드박스 평가 프레임워크를 Verilog 코드 생성용으로 구성합니다.
- HDLBits에서 자체 포함 모듈을 포함한 156문제의 Verilog 평가 세트를 구성합니다.
- 도커 샌드박스 내에서 ICARUS Verilog의 기능 시뮬레이션을 통해 골든 솔루션과 자동으로 생성된 Verilog 완성을 테스트합니다.
- GitHub에서 자체 포함 Verilog 모듈을 추출하고, LLM으로 설명 텍스트를 생성한 뒤 이를 코드와 쌍으로 연결하는 합성 SFT 데이터를 만듭니다.
- 합성 SFT 데이터로 CodeGen 계열 모델을 미세조정하고 pass@k 지표로 평가합니다(k는 {1,5,10}).
- GPT-3.5/4 및 Verilog 중심의 기본 모델(codegen-nl, codegen-multi, codegen-Verilog) 간의 성능을 비교하고 데이터 품질의 효과를 분석합니다.
실험 결과
연구 질문
- RQ1LLMs가 다양한 작업에 대해 자연어 설명에서 올바른 Verilog 코드를 신뢰성 있게 생성할 수 있나요?
- RQ2샌드박스화된 자동 테스트 워크플로가 Verilog 솔루션의 기능적 정확성과 상관관계가 있나요?
- RQ3합성 SFT 데이터가 LLM을 미세조정할 때 Verilog 코드 생성 성능을 얼마나 개선할 수 있나요?
- RQ4모델 크기와 기본 모델 선택이 VerilogEval 성능에 어떤 영향을 미치나요?
- RQ5SFT 데이터 품질이 Downstream Verilog 코딩 성능에 미치는 영향은 무엇인가요?
주요 결과
- VerilogEval은 기능적 정확성이 골든 솔루션에 대한 자동 시뮬레이션으로 측정될 수 있음을 보여줍니다.
- 더 크고 더 능력 있는 모델일수록 일반적으로 Verilog 코딩 성능이 더 좋습니다.
- 합성 SFT 데이터는 Verilog으로 학습된 모델과 일부 다중 언어 기반 모델의 다운스트림 Verilog 성능을 향상시키며, VerilogEval-머신 결과에서 현저한 이득이 있습니다.
- SFT 데이터의 품질은 중요합니다. 문제-코드 쌍에 잘못된 데이터를 도입하면 성능이 저하되어 고품질 합성 데이터의 중요성을 강조합니다.
- GPT-4는 여러 구성에서 GPT-3.5보다 pass@1, pass@5, pass@10 점수가 더 높으며, Verilog 중심의 SFT는 일부 베이스라인에서 GPT-3.5의 성능에 근접할 수 있습니다.
- SFT에는 트레이드오프가 있습니다: 에포크 수를 늘리면 pass@1은 개선되지만 pass@5와 pass@10은 SFT 데이터에 과적합으로 악화될 수 있습니다.
![Figure 7: Variance in estimating pass@ k with $n$ . Samples from codegen-16B-verilog [ 12 ] for VerilogEval-human .](https://ar5iv.labs.arxiv.org/html/2309.07544/assets/figs/variance.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.