[논문 리뷰] Video Anomaly Detection in 10 Years: A Survey and Outlook
이 설문은 deep learning-based Video Anomaly Detection (VAD)을 포함한 감독학습, 약하게 감독된, 자기 감독된, 비감독된 방법 및 vision-language 모델을 포함한 VAD를 검토하고 데이터셋, 손실 및 향후 방향에 대해 논의합니다.
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
연구 동기 및 목표
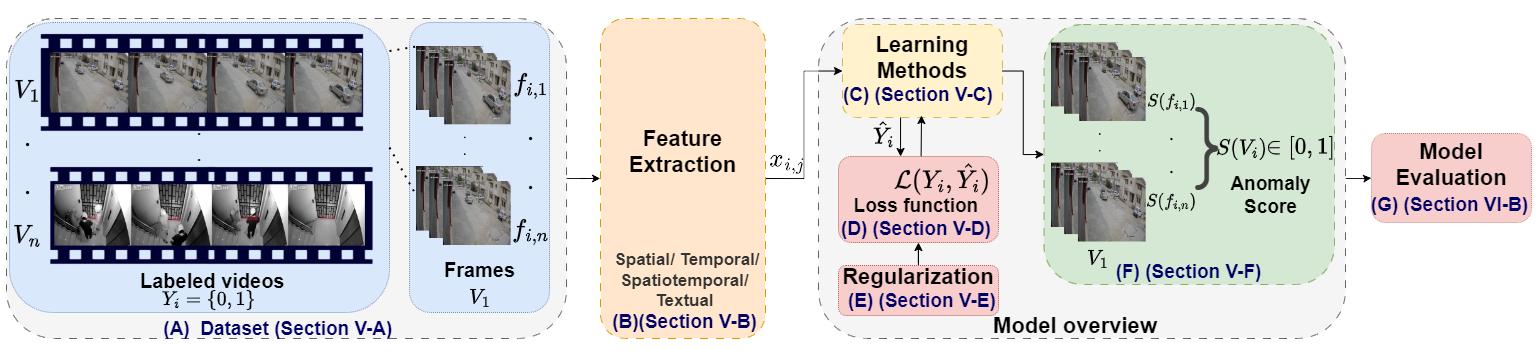
- 현대 VAD의 핵심 과제 식별, 대규모 데이터셋, 특징 추출, 손실 함수, 정규화, 이상점수 예측을 포함.
- VAD 성능에 대한 딥 러닝 접근법(감독, 약하게 감독된, self-supervised, 비감독)의 영향 평가.
- VAD를 위한 특징 추출기로서 vision-language 모델의 가능성 탐색.
- 데이터셋 벤치마크를 종합하고 향후 VAD 연구와 실무를 위한 권고안을 제시.
제안 방법
- 상위 컴퓨터 비전 학술지/학회(CVPR, ICCV, ECCV, TPAMI, IJCV, CVIU)에서 지난 10년간 문헌에 대한 체계적 검토.
- 방법을 supervised, unsupervised, self-supervised, weakly supervised 범주로 분류.
- 데이터셋, 특징 추출 기법(공간적, 시간적, 공간-시간적, 텍스트 기반), 손실/정규화 체계 분석.
- 벤치마크 데이터셋에서 최첨단 모델 평가(정성적 및 정량적)로 강점과 약점 식별.
- VAD의 특징 추출기로서 vision-language models (VLMs)의 논의 및 성능에 대한 영향.
- 강 robust VAD 시스템을 위한 향후 방향 및 권고 제안.
![Figure 1: Performance improvement from 2017 until 2023 on two popular benchmarks. Performance is measured by the area under the ROC curve (AUC%). Note that some of the models were developed before the datasets were created but were used after the creation by other researchers such as [ 15 , 16 ] . T](https://ar5iv.labs.arxiv.org/html/2405.19387/assets/Figures/introchart.png)
실험 결과
연구 질문
- RQ1비디오 이상 탐지에 사용되는 지배적 딥 러닝 패러다임은 무엇이며(감독, 약하게 감독된, self-supervised, unsupervised) 어떻게 비교되는가?
- RQ2특징 추출 선택(공간적, 시간적, 공간-시간적, 텍스트 기반)과 손실 함수가 VAD 성능에 어떤 영향을 미치는가?
- RQ3VAD에서 vision-language 모델의 역할은 무엇이며 이상점수 예측 및 로컬라이제이션에 어떤 영향을 미치는가?
- RQ4실세계 VAD 과제를 잘 포착하는 데이터셋과 평가 프로토콜은 무엇이며 벤치마크는 어떻게 발전해야 하는가?
- RQ5데이터 다양성, 현실성, 장기 맥락, 멀티모달 데이터 등 현재 한계를 다룰 수 있는 VAD의 향후 방향은 무엇인가?
주요 결과
- 딥 러닝 기반 VAD는 지난 10년간 성능을 크게 향상시켰으며, Vision-Language 모델에서 주목할 만한 향상을 보였다.
- 데이터셋은 복잡성 및 현실성이 다양하며, 이상 다양성의 제한 및 클래스 불균형과 같은 문제가 도전과제로 강조된다.
- 공간적 특징과 시간적 특징이 모두 필수적이며, 이를 spatiotemporal 표현으로 통합하면 탐지 및 로컬라이제이션이 향상된다.
- 약하게 감독된 및 비감독 패러다임은 주석 달기 부담을 줄이면서 견고한 탐지를 유지하는 데 점점 더 중요해지고 있다.
- Vision-language 특징은 이상 이해 및 점수 산정에 보완적인 의미 맥락을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.