[논문 리뷰] Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Video-ChatGPT는 비디오에 맞게 조정된 CLIP 인코더와 Vicuna 기반 LLM을 결합하고, 100k 개의 비디오 지시 쌍으로 학습되었으며, 상세한 개방형 비디오 대화를 가능하게 하는 정량적 비디오 대화 평가 프레임워크를 도입합니다.
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of \emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
연구 동기 및 목표
- 전통적인 QA를 넘어 비디오에 대한 개방적이고 일관된 대화를 촉진한다.
- 비디오에 특화된 비전-언어 모델로 시간적 및 공간적 이해를 가능하게 한다.
- 고품질 비디오 지시 데이터의 확장 가능한 데이터 생성 프레임워크를 제공한다.
- 비디오 기반 대화 능력을 정량적으로 평가하는 벤치마크 프레임워크를 제공한다.
제안 방법
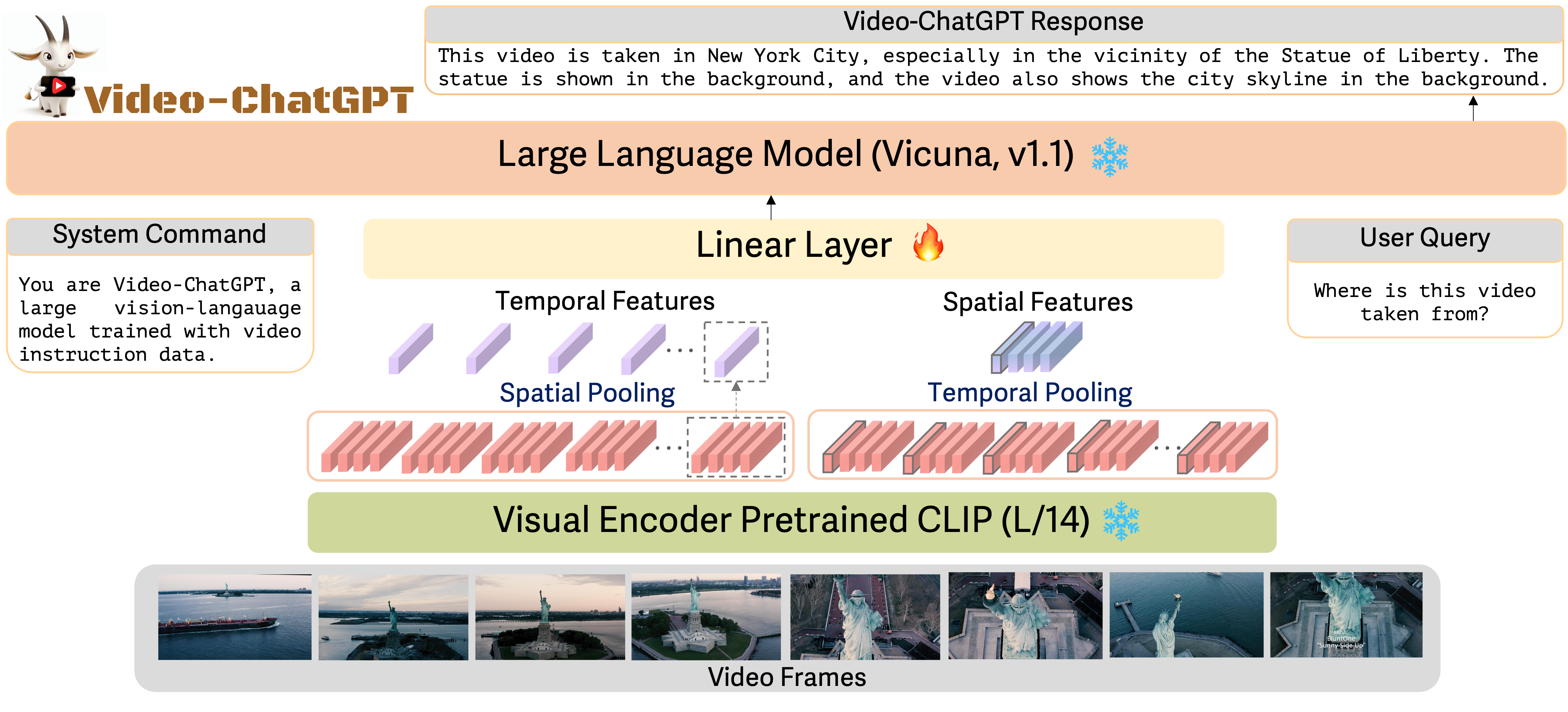
- 시각 인코더로 CLIP ViT-L/14를 적응시키고 Vicuna를 언어 디코더로 사용하여 비디오 확장 VL 모델을 설계한다.
- 대부분 백본 구성 요소를 고정한 채로 100k 비디오-지시 쌍에 대해 지시 조정으로 생성 및 미세 조정을 수행한다.
- LLM 입력 공간으로 시공간 비디오 특징을 투영하는 간단한 어댑터 g를 개발한다.
- 인간 보조 및 준자율 주석 파이프라인의 하이브리드를 통해 풍부한 비디오 지시 데이터를 생성한다.
- 정확성, 세부사항, 맥락, 시간적 및 일관성 측면을 다루는 비디오 기반 대화를 위한 정량적 평가 프레임워크를 제안한다.
실험 결과
연구 질문
- RQ1비전-언어 모델이 시공간적 비디오 콘텐츠를 얼마나 잘 이해하고 대화할 수 있는가?
- RQ2고정된 백본을 가진 경량 어댑터가 경쟁력 있는 비디오 기반 대화 성능을 달성할 수 있는가?
- RQ3고품질의 비디오 특화 지시 데이터가 개방형 비디오 대화에 미치는 영향은 무엇인가?
- RQ4여러 능력에 걸쳐 비디오 기반 대화 모델의 강점과 약점을 어떻게 정량화할 수 있는가?
주요 결과
| 모델 | MSVD-QA (정확도) | MSVD-QA (점수) | MSRVTT-QA (정확도) | MSRVTT-QA (점수) | TGIF-QA (정확도) | TGIF-QA (점수) | Activity Net-QA (정확도) | Activity Net-QA (점수) |
|---|---|---|---|---|---|---|---|---|
| FrozenBiLM | 32.2 | – | 16.8 | – | 41.0 | – | 24.7 | – |
| Video Chat | 56.3 | 2.8 | 45.0 | 2.5 | 34.4 | 2.3 | 26.5 | 2.2 |
| Video-ChatGPT | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 | 35.2 | 2.7 |
- Video-ChatGPT가 동시대 모델과 비교하여 다수의 데이터셋에서 제로샷 QA 성능이 경쟁력 있다.
- MSVD-QA, MSRVTT-QA, TGIF-QA, 및 ActivityNet-QA에서 Video-ChatGPT가 Video Chat 및 FrozenBiLM 베이스라인보다 더 높은 정확도/점수를 달성한다.
- 모델은 비디오 데이터에 대한 지시 조정 덕분에 강한 시간적 이해와 맥락 인식 응답을 보여준다.
- 인간 보조 및 반자율 주석이 있는 100k 비디오-지시 데이터셋은 비디오 특화 이해 및 대화 능력을 향상시킨다.
- 본 논문은 비디오 기반 대화 모델을 벤치마크하기 위한 최초의 정량적 비디오 대화 평가 프레임워크를 제시한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.