[논문 리뷰] Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
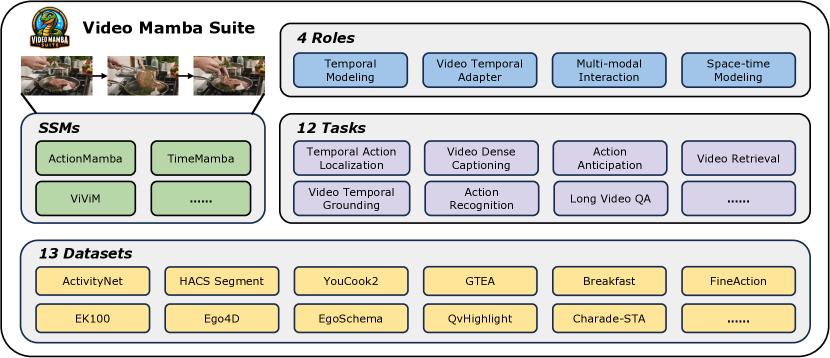
본 논문은 State Space Models(SSMs), 특히 Mamba 및 그 변형들을 Transformer의 실용적 대안으로 간주할 수 있는지 여부를 다루며, 12개의 작업에 걸친 Video Mamba Suite를 통해 14개의 모델을 제시한다. 이는 영상 이해의 광범위한 작업에서 경쟁력 있는 성능과 시간적, 크로스-모달 및 시공간 영상 모델링에서 우수한 효율성을 보임.
Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.
연구 동기 및 목표
- 비디오 이해를 위한 Mamba가 트랜스포머의 실현 가능한 대안이 될 수 있는지 평가한다.
- 여러 작업에 걸쳐 SSM 기반 모델 14개로 구성된 Video Mamba Suite를 구성하고 평가한다.
- Mamba를 시간 모델, 시간 모듈, 다중 모달 상호작용 네트워크, 시공간 모델의 네 가지 역할에서 분석한다.
- 다양한 영상 데이터셋에서 Mamba 변형을 트랜스포머 기준선과 비교하여 강점과 트레이드오프를 밝힌다.
제안 방법
- S4, Mamba 등 State Space Models와 0차 보유(zero-order hold)를 이용한 이들의 이산 형식을 설명하고 Ā와 B̄를 얻는다.
- Mamba, ViM, DBM 등 네 가지 Mamba 기반 블록 변형과 양방향 및 방향성 스캐닝에 대한 아키텍처 차이점을 도입한다.
- 12개 작업에 걸친 14개 모듈로 Video Mamba Suite를 구축하여 시간적 로컬라이제이션, 분할, 자막 생성, 행동 예측, 그리고 크로스-모달 비디오 바인딩을 포괄한다.
- 강력한 베이스라인의 트랜스포머 블록을 Mamba 블록으로 교체하여 공정한 비교를 위한 경쟁력 있는 Mamba 기반 모델을 형성한다.
- 13개의 주요 데이터셋에서 평가하고 mAP, 정확도, BLEU/METEOR/CIDEr/SODA, 그리고 검색 지표와 같은 지표를 보고한다.
- Flash-attention과 프레임 길이 확장에 따른 추론 속도 비교를 통해 효율성을 분석한다.
실험 결과
연구 질문
- RQ1다양한 영상 이해 작업에서 Mamba 기반 SSM이 트랜스포머와 비슷한 성능을 달성할 수 있는가?
- RQ2어떤 역할(시간 모델링, 시간 모듈, 다중 모달 상호작용, 시공간 모델링)이 비디오 작업에서 Mamba를 가장 잘 활용하는가?
- RQ3긴 영상 시퀀스에 대해 Mamba 변형이 유리한 효율-성능 트레이드오프를 제공하는가?
- RQ4트랜스포머 기반 기준선과 비교하여 시간적 바인딩 및 다중 모달 작업에서 Mamba 기반 크로스-모달 모델의 성능은 어떤가?
- RQ5양방향 대 방향 스캐닝 및 분해된 블록 설계가 성능에 미치는 영향은 무엇인가?
주요 결과
- Video Mamba Suite에서 시간적 행동 로컬라이제이션 및 세분화에서 Mamba 기반 모델이 트랜스포머 기준선보다 종종 우수한 성능을 보인다.
- DBM 블록을 사용하는 ActionMamba가 HACS Segment에서 트랜스포머 상대 대비 평균 mAP를 더 높은 수치로 달성한다(44.56 대 43.34).
- 밀집 영상 자막 생성에서 DBM(자사)이 ActivityNet 및 YouCook2에서 METEOR와 CIDEr를 베이스라인보다 향상시킨다.
- DBM을 이용한 크로스-모달 UniVTG가 QvHighlight 및 Charade-STA 데이터셋에서 트랜스포머 UniVTG보다 평균 mAP가 더 높게 나타난다.
- TimeMamba는 Ego4D로 사전학습되었을 때 Epic-Kitchens-100에서 제로샷 다중 인스턴스 검색 및 행동 인식에서 일반적으로 TimeSformer보다 우수하다.
- ViViM 기반의 시공간 모델링은 ViT 변형에 비해 제로샷 검색에서 강한 이점을 보여주며 긴 시퀀스 영상 작업에서 효과를 시사한다.
![Figure 2 : Illustration of three SSMs blocks. (a) is the vanilla Mamba block [ 30 ] . (b) is the ViM block [ 96 ] . (c) is our proposed DBM block, which separates the input projector and shares the parameters of SSM in both scanning directions.](https://ar5iv.labs.arxiv.org/html/2403.09626/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.