[논문 리뷰] VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
VideoCrafter1은 고품질 비디오 생성을 위한 두 개의 오픈소스 확산 모델을 제시합니다: 텍스트-투-비디오(T2V) 모델은 시네마 해상도 비디오를 생성하고, 이미지-투-비디오(I2V) 모델은 주어진 이미지를 유지하되 애니메이션합니다.
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 imes 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
연구 동기 및 목표
- 오픈소스 비디오 생성을 고품질 텍스트-투-비디오 합성으로 진전
- 입력 콘텐츠와 구조를 보존하는 이미지 조건 비디오 생성을 가능하게
- 일관된 비디오를 위한 시간적 주의를 포함한 잠재 공간 확산 기법 조사
- 고해상도 비디오 생성을 지원하는 학습 전략과 데이터세트 제공
- 커뮤니티 채택 및 평가를 촉진하는 도구와 벤치마크 제공
제안 방법
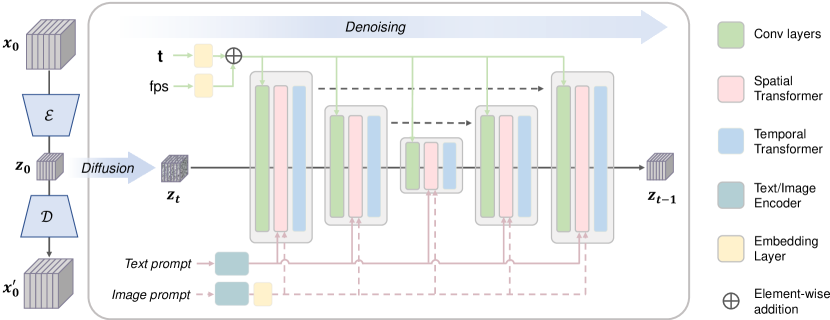
- 비디오 VAE와 잠재 공간에서 작동하는 비디오 확산 모델을 갖춘 Latent Video Diffusion Model(LVDM) 구축
- 3D 디노이징 U-Net에 시간적 주의층을 도입하여 시간적 일관성 보장
- 텍스트 프롬프트를 통한 의미적 제어 주입; 프레임 속도(FPS)/시간 임베딩을 사용해 모션 속도 제어
- I2V의 경우 CLIP의 이미지 인코더에서 풍부한 이미지 임베딩 추출하고 이를 텍스트 임베딩과 이중 교차 주의로 융합
- 진행식 해상도 전략(256×256 to 1024×576)으로 대규모 이미지 및 비디오 데이터 세트에서 T2V 학습
- 오픈소스 I2V 매핑 개발: 이미지 임베딩을 확산 모델의 교차 주의 공간에 정렬

실험 결과
연구 질문
- RQ1오픈소스 확산 모델이 고품질의 시네마 해상도 T2V 비디오 생성을 달성할 수 있는가?
- RQ2오픈소스 I2V 모델이 참조 이미지의 콘텐츠와 구조를 보존하면서 모션을 가능하게 할 수 있는가?
- RQ3시간적 일관성과 모션 크기를 개선하는 아키텍처 및 학습 전략은 무엇인가?
- RQ4이미지 조건 토큰이 이미지-투-비디오 조건부에서 전역 의미 토큰과 비교해 어떻게 다른가?
- RQ5오픈소스 설정에서 견고한 고해상도 비디오 생성을 가능하게 하는 데이터세트 및 학습 규칙은 무엇인가?
주요 결과
- T2V 모델은 오픈소스 프레임워크에서 높은 시각적 품질과 고해상도 비디오 생성을 지원
- I2V 모델은 입력 이미지의 콘텐츠와 구조를 보존하는 동시에 애니메이션 가능
- 풍부한 이미지 임베딩(전체 CLIP 패치 토큰)이 이미지 조건 비디오 생성에서 전역 의미 토큰보다 충실도를 향상
- 이중 교차 주의로 텍스트와 이미지 입력을 I2V 생성에 통합하되 추가 매개변수는 최소화
- 잠재 공간 확산과 시간적 주의는 일부 기준선에 비해 시간적 일관성과 모션 다이나믹스에서 우수한 성능
- 오픈소스 모델은 여러 평가 측면에서 상용 counterpart와 경쟁적이며 지속성과 모션 현실성 측면에서 추가 개선 여지 존재
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.