[논문 리뷰] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
VideoMAE V2는 이중 마스킹과 점진적 학습을 도입하여 비디오 마스크드 오토인코더를 십억 매개변수 ViT로 확장하고, 액션 인식, 탐지 및 시간적 위치 식에서 최첨단 결과를 달성합니다.
Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner. The code and model is available at \url{https://github.com/OpenGVLab/VideoMAEv2}.
연구 동기 및 목표
- 다양한 작업에 일반화되도록 비디오 기초 모델에 대한 확장 가능한 자기감독 사전 학습을 동기로 삼는다.
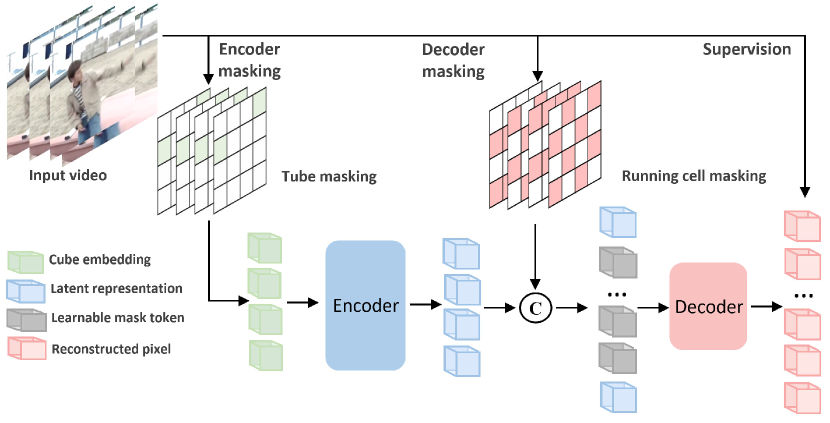
- 십억 매개변수 비디오 트랜스포머의 효율적 사전 학습을 가능하게 하는 이중 마스킹 체계 개발.
- 대규모 사전 학습을 지원하기 위해 백만 수준의 비표기 비디오 데이터와 혼합 레이블 비디오 데이터를 구성.
- 비지도 사전 학습 후 감독형 사전 학습을 포함하는 점진적 학습 파이프라인을 채택.
- VideoMAE V2 표현의 다수의 다운스트림 비디오 과제에 대한 전이 가능성을 시연한다.
제안 방법
- 높은 비율의 인코더 마스크와 디코더 마스크를 사용한 이중 마스킹 전략을 채택하여 디코더 입력 길이를 감소시킨다.
- 디코더에서 보이는 토큰의 하위 집합만 재구성하는 경량 디코더를 사용한다.
- 인코더에서 보이는 토큰으로부터의 정보 누수를 방지하면서 디코더에서 보이는 토큰에 대해 평균 제곱 오차 재구성 손실로 학습한다.
- 거대한 ViT 백본(예: ViT-g)을 사용하여 모델 용량을 확장하고 백만 수준의 비라벨 비디오 데이터 세트로 사전 학습 데이터를 다양화한다.
- UnlabeledHybrid에서의 비지도 사전 학습, LabeledHybrid에서의 감독형 후사전 학습, 그리고 이후 과제별 미세 조정의 점진적 학습 파이프라인을 구성한다.
- 백만-단위 수준의 비지도 데이터셋과 다중 소스 혼합의 라벨링 데이터셋을 구성하고 활용하여 십억 수준의 사전 학습 및 교차 작업 전이를 지원한다.
실험 결과
연구 질문
- RQ1VideoMAE 스타일의 마스킹 오토인코딩을 십억 매개변수의 비디오 트랜스포머로 효과적으로 확장할 수 있는가?
- RQ2이중 마스킹(인코더 및 디코더)이 표현 품질 저하 없이 학습 효율을 크게 개선하는가?
- RQ3데이터 규모와 다양성은 대규모 비디오 마스킹 사전 학습의 성능에 어떤 영향을 미치는가?
- RQ4하이브리드 라벨 데이터셋에서의 점진적 감독형 미세 조정이 큰 사전 학습 데이터와 작은 다운스트림 데이터셋 간의 격차를 줄일 수 있는가?
- RQ5다양한 벤치마크에서 VideoMAE V2 표현이 액션 인식, 공간 및 시간적 액션 탐지로 얼마나 잘 전이되는가?
주요 결과
- VideoMAE V2는 성공적으로 십억 매개변수를 가진 비디오 트랜스포머(ViT-g)를 학습시킨다.
- 이중 마스킹은 인코더 전용 마스킹과 비교하여 정확도 유지 또는 향상을 보장하면서 FLOPs와 메모리를 감소시킨다.
- 백만 수준의 비지도 혼합 비디오 데이터 세트에서의 사전 학습과 0.66M 클립, 710-카테고리 라벨이 있는 혼합 데이터 세트에 대한 후사전 학습은 강력한 다운스트림 성능을 제공합니다.
- VideoMAE V2는 Kinetics-400(90.0%), Kinetics-600(89.9%), Something-Something V1/V2(68.7%, 77.0%)에서 새로운 SOTA를 달성하고 AVA 및 시간적 액션 데이터셋에서도 강력한 결과를 보인다.
- 점진적 사전 학습과 데이터 다양화는 과적합을 완화하고 액션 인식 및 탐지 벤치마크 전반에서 다운스트림 작업으로의 전이를 개선한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.