[논문 리뷰] VideoPrism: A Foundational Visual Encoder for Video Understanding
VideoPrism은 고품질 자막과 노이즈 텍스트의 대규모 혼합으로 사전학습된 범용 동영상 인코더로, 분류, 로컬라이제이션, 검색, 자막 생성, QA를 포함한 대부분의 비디오 이해 벤치마크에서 최첨단 성능을 달성합니다.
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks. Our models are released at https://github.com/google-deepmind/videoprism.
연구 동기 및 목표
- 외관과 모션 이해의 균형을 맞춘 진정한 기초 영상 모델의 필요성을 제시합니다.
- 비디오-텍스트 쌍과 비디오 전용 데이터를 활용하는 두 단계 사전학습 전략을 제안합니다.
- 동결된 비디오 인코더가 최소한의 태스크 특화 적응으로도 다양한 태스크에서 최첨단 결과를 달성할 수 있음을 보여줍니다.
- 일반 비디오 태스크와 과학 CV 도메인에서의 VideoPrism의 효율성을 보여주어 광범위한 일반화 가능성을 입증합니다.
제안 방법
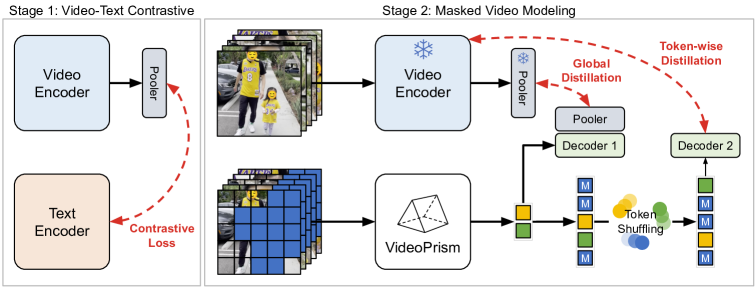
- Two-stage pretraining: Stage 1은 비디오-텍스트 대조 학습을 통해 의미론적 비디오 임베딩을 학습합니다.
- Stage 2는 비디오 전용 데이터에서 글로벌-로컬 증류를 사용하여 개선된 마스킹 비디오 모델링을 수행합니다.
- 마스킹 모델링 중 디코딩 숏컷을 방지하기 위해 토큰 셔플링 스키HEME를 도입합니다.
- 1단계 임베딩의 글로벌 증류를 사용하여 재앙적 망각을 완화합니다.
- 공간-시간 인자 분해를 갖는 Vision Transformer 기반 아키텍처이며, 공간 인코더 뒤에 글로벌 풀링이 없습니다.
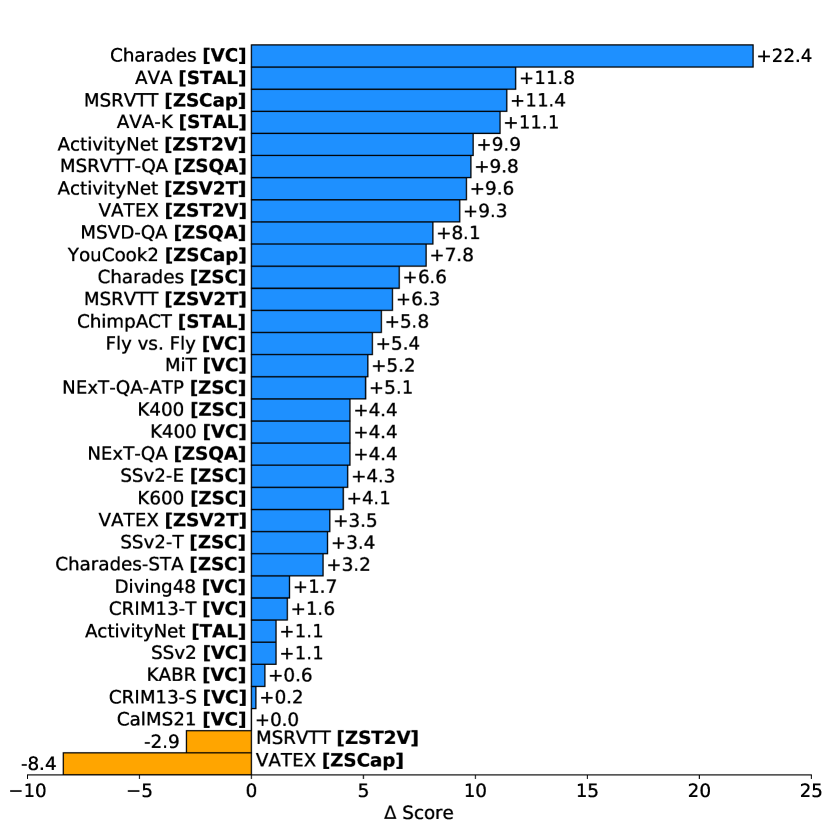
실험 결과
연구 질문
- RQ1이질적 비디오-텍스트 데이터와 비디오 전용 데이터로 학습된 단일 동결 비디오 인코더가 광범위한 비디오 이해 태스크에서 최첨단 성능을 달성할 수 있을까요?
- RQ2글로벌-로컬 증류와 토큰 셔플링이 결합된 두 단계 사전학습 방식이 비디오의 모션 및 외관 이해를 향상시킬까요?
- RQ3작업 특화 파인튜닝 없이 제로샷 비디오-텍스트 검색, 자막 생성, QA 및 과학 도메인 데이터셋에 대해 VideoPrism이 얼마나 잘 일반화합니까?
- RQ4인코더를 동결하고 태스크 헤드만 학습하는 것이 다양한 벤치마크에서 경쟁력 있는 결과를 내기에 충분합니까?
주요 결과
- VideoPrism은 네 가지 태스크 그룹에 걸쳐 33개 비디오 이해 벤치마크 중 30개에서 최첨단 성능을 달성합니다.
- 동결된 VideoPrism 변형(B 및 g)은 VideoGLUE 유사 벤치마크와 제로샷 태스크에서 일관되게 기준선보다 우수합니다.
- 글로벌-로컬 증류 및 토큰 셔플링이 포함된 두 단계 사전학습은 SSv2와 같은 모션 중심 데이터셋에서 특히 상당한 이득을 제공합니다.
- 제로샷 비디오-텍스트 검색 및 분류가 새로운 기록에 도달하며, 종종 더 크거나 다중 모달 모델보다 추가 모달리티를 가진 경우도 우수합니다.
- VideoPrism은 과학용 CV 데이터셋에 대해 강한 일반화를 보여 주로 도메인 특화 모델을 능가하며, 특히 기본 규모와 대규모 변형에서 그렇습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.