[논문 리뷰] VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
VioLA는 음성 및 텍스트 작업을 하나의 디코더-전용 Transformer로 통합하며, 음성을 이산 코덱 토큰으로 변환하고 작업 및 언어 ID를 활용한 다중 작업 목표로 학습한다.
Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
연구 동기 및 목표
- 다양한 모듬의 음성 및 텍스트 작업을 모두 포괄하는 단일 디코더-전용 모델의 필요성을 제시한다.
- 음성 신호를 이산 코덱 토큰으로 변환하여 모든 작업을 토큰 시퀀스 문제로 다루는 방법을 제시한다.
- 작업 ID와 언어 ID를 도입하여 언어와 작업을 구별한다.
- 통합 디코더가 여러 음성 작업에서 강력한 베이스라인에 맞추거나 능가할 수 있음을 보여준다.
제안 방법
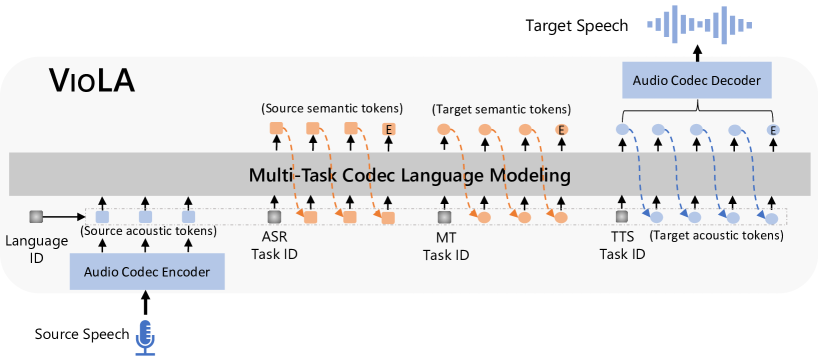
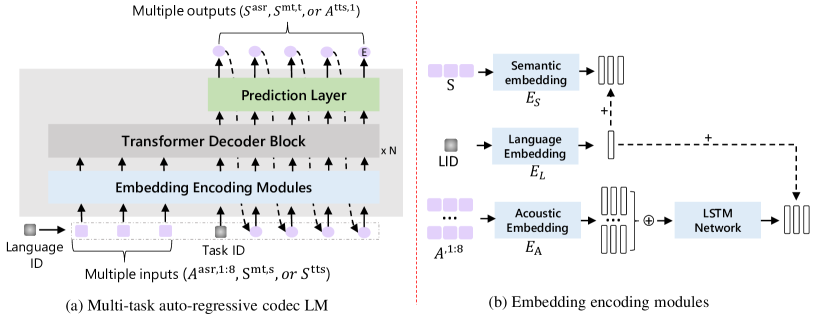
- 자동 회귀(autoregressive) 코덱 Transformer 언어 모델을 핵심 네트워크로 사용한다.
- 음성은 EnCodec를 통해 8층 음향 토큰 시퀀스로, 텍스트는 음소 시퀀스로 변환한다.
- 사전 네트 embedding 모듈과 Transformer 디코더를 통해 시맨틱 및 음향 토큰을 융합한다.
- 다중 작업 목표를 통해 ASR, MT, TTS를 위한 p(y|x,θ)를 최대화하도록 학습한다.
- 작업 ID와 언어 ID를 도입하여 모델을 작업 및 언어에 조건화한다.
- TTS의 경우 VALL-E X와 같이 모든 계층의 음향 토큰을 생성하기 위해 비자기회귀 코덱 LM을 사용한다.
실험 결과
연구 질문
- RQ1코덱 기반 프레임워크에서 하나의 디코더-전용 모델이 ASR, MT, TTS 및 교차 모달 번역을 모두 수행할 수 있는가?
- RQ2음성을 이산 코덱 토큰으로 인코딩하는 것이 다수의 음성 작업에서 토큰 기반 시퀀스 모델링을 효과적으로 가능하게 하는가?
- RQ3모델 규모와 음향 토큰 계층화가 작업 간 성능에 미치는 영향은 무엇인가?
- RQ4작업 ID와 언어 ID가 다국어 및 다작업 능력에 어떤 영향을 미치는가?
주요 결과
- VioLA (18L) 는 AED 베이스라인과 비슷한 매개변수 수로 WMT2020 MT에서 상태급 BLEU(56.97)를 달성하였다.
- ASR에서 18층 VioLA는 PER 11.36을 달성하여 AED 성능에 근접하고 일부 디코더-전용 베이스라인보다 우수하다.
- S2TT에서 VioLA를 사용한 코덱 기반 계단식 LM은 BLEU 55.70–55.85를 달성하여 Fbank 기반 계단식 AED 모델과 경쟁하지만 매개변수가 더 적다.
- 제로샷 EN TTS 및 교차 언어 TTS는 VALL-E X에 비해 화자 유사성과 자연스러움이 개선되었고 WER 감소 및 SN 점수에서 SAL 개선이 나타난다.
- 프레임당 음향 코드 계층 수를 늘리면 ASR 성능이 크게 향상되어 PER이 눈에 띄게 감소한다.
- 임베딩 모듈에 LSTM을 도입하면 ASR 및 TTS 성능이 더 향상되어 디코딩 품질이 향상된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.