[논문 리뷰] VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging
VISTA3D는 자동 및 대화형 가지가 있는 통합 3D CT 분할 기초 모델을 제안하며, 11454개의 CT 스캔에서 127개 클래스에 대해 제로샷 성능과 강력한 전이 학습을 달성합니다.
Foundation models for interactive segmentation in 2D natural images and videos have sparked significant interest in building 3D foundation models for medical imaging. However, the domain gaps and clinical use cases for 3D medical imaging require a dedicated model that diverges from existing 2D solutions. Specifically, such foundation models should support a full workflow that can actually reduce human effort. Treating 3D medical images as sequences of 2D slices and reusing interactive 2D foundation models seems straightforward, but 2D annotation is too time-consuming for 3D tasks. Moreover, for large cohort analysis, it's the highly accurate automatic segmentation models that reduce the most human effort. However, these models lack support for interactive corrections and lack zero-shot ability for novel structures, which is a key feature of "foundation". While reusing pre-trained 2D backbones in 3D enhances zero-shot potential, their performance on complex 3D structures still lags behind leading 3D models. To address these issues, we present VISTA3D, Versatile Imaging SegmenTation and Annotation model, that targets to solve all these challenges and requirements with one unified foundation model. VISTA3D is built on top of the well-established 3D segmentation pipeline, and it is the first model to achieve state-of-the-art performance in both 3D automatic (supporting 127 classes) and 3D interactive segmentation, even when compared with top 3D expert models on large and diverse benchmarks. Additionally, VISTA3D's 3D interactive design allows efficient human correction, and a novel 3D supervoxel method that distills 2D pretrained backbones grants VISTA3D top 3D zero-shot performance. We believe the model, recipe, and insights represent a promising step towards a clinically useful 3D foundation model. Code and weights are publicly available at https://github.com/Project-MONAI/VISTA.
연구 동기 및 목표
- 일상적인 해부 구조를 포괄하고 즉시 사용 가능한 정확도를 가진 3D CT 분할의 기초 모델 정의.
- 향상된 분할 결과를 위한 대화형 정제 기능 활성화.
- 주석이 거의 없는 상태에서 보지 못한 구조를 분할하기 위한 제로샷 능력 개발.
- 새로운 클래스에 빠르게 적응할 수 있도록 교육 레시피와 아키텍처 제공.
- 대규모 CT 데이터셋에서 평가하고 태스크 특화 모델과 비교하기.
제안 방법
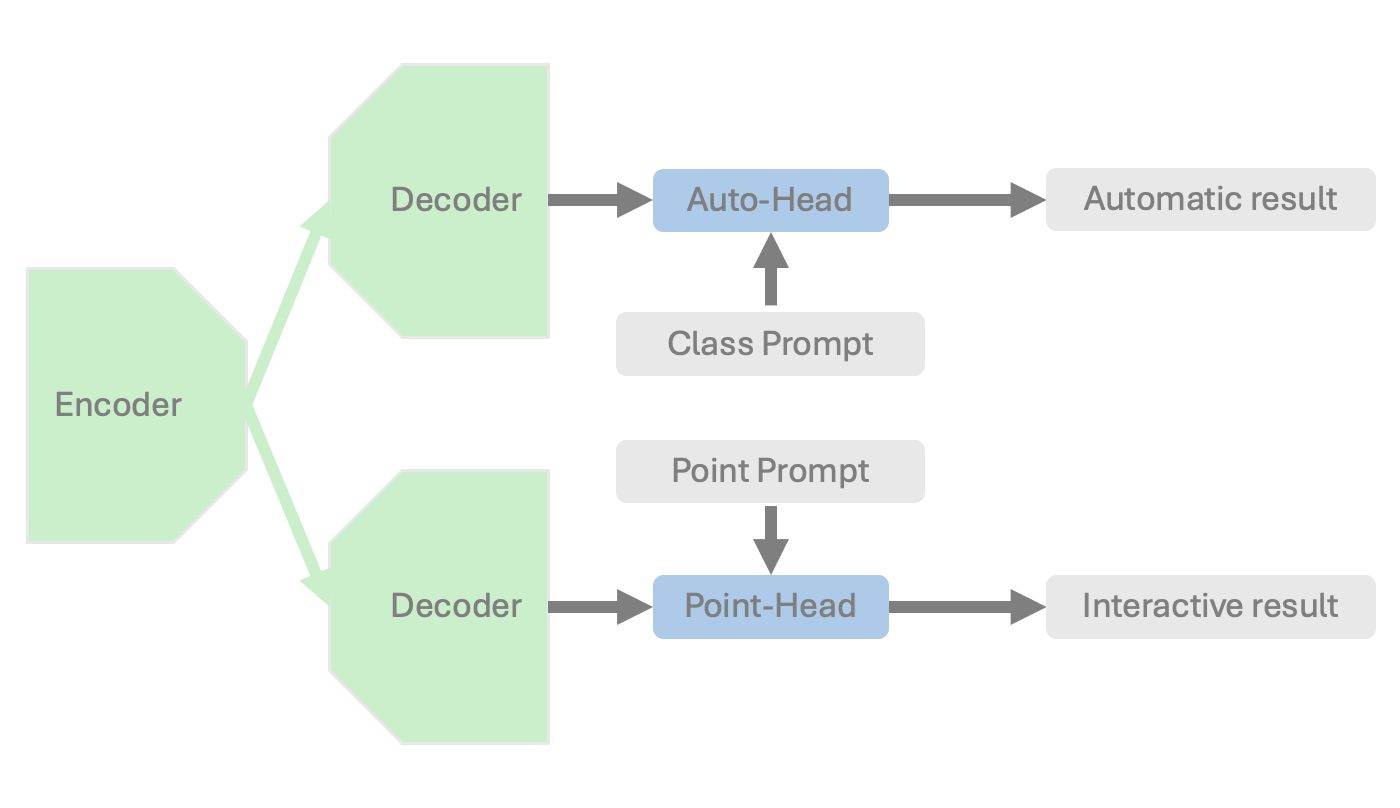
- SegResNet 기반 이미지 인코더를 공유하는 이중 가지 아키텍처: 즉시 사용 가능한 127개 클래스 분할용 자동 헤드와 3D 포인트 프롬프트를 받는 대화형 헤드.
- 자동 가지는 학습 가능한 클래스 임베딩과 포스트 매핑 레이어를 사용해 클래스 특정 분할 로짓을 생성.
- 대화형 가지는 3D로 SAM의 포인트-프롬프트 인코더를 적용하고 포인트 헤드의 3D 다운샘플링 및 클래스 인식 포인트 임베딩을 사용.
- 학습은 수동 라벨, TotalSegmentator로부터의 의사 라벨, 그리고 SAM에서 증류된 3D 초볼텍셀을 활용한 4단계 레시피를 통해 제로샷 분할 가능성을 가능하게 함.
- 자동 및 대화형 출력의 통합은 잘못된 영역을 보존하기 위한 구성 요소 수준의 정제 전략(Alg. 1)을 사용하여 수행.
- 데이터 구성은 11454개의 CT 볼륨과 127개 클래스, 의사 라벨과 초볼텍셀로 보강; 3D 패치 기반 학습과 슬라이딩 윈도우 추론으로 구성.
실험 결과
연구 질문
- RQ1단일 3D CT 분할 모델이 여러 오르간과 병변에 대해 즉시 사용 가능한 정확한 성능을 달성할 수 있는가?
- RQ2통합 된 대화형 가지가 3D CT 데이터에서 보지 못한 클래스에 대한 효과적인 제로샷 분할을 가능하게 하는가?
- RQ3의사 라벨과 초볼텍셀로 학습된 이중 가지 아키텍처가 손으로 라벨이 된 태스크 특화 모델과 경쟁력 있는 성능을 낼 수 있는가?
- RQ4새로운 데이터셋이나 이상현상에 적응하기 위한 소수샷 미세조정에서 VISTA3D의 성능은 어떤가?
주요 결과
| 데이터셋 | Auto3dSeg | nnUNet | TotalSegmentator | VISTA3D auto | VISTA3D point | VISTA3D auto+point |
|---|---|---|---|---|---|---|
| MSD03 Hepatic tumor [3] | 0.616 | 0.617 | - | 0.588 | 0.701 | 0.687 |
| MSD06 Lung tumor [3] | 0.562 | 0.554 | - | 0.613 | 0.682 | 0.719 |
| MSD07 Pancreatic tumor [3] | 0.485 | 0.488 | - | 0.324 | 0.603 | 0.638 |
| MSD08 Hepatic tumor [3] | 0.683 | 0.659 | - | 0.682 | 0.733 | 0.757 |
| MSD09 Spleen [3] | 0.965 | 0.967 | 0.966 | 0.952 | 0.938 | 0.954 |
| MSD10 Colon tumor [3] | 0.475 | 0.473 | - | 0.439 | 0.609 | 0.633 |
| Airway [43] | 0.896 | 0.899 | - | 0.852 | 0.819 | 0.867 |
| Bone Lesion | 0.343 | 0.396 | - | 0.491 | 0.536 | 0.585 |
| BTCV-Abdomen [37] | 0.807 | 0.825 | 0.846 | 0.849 | 0.815 | 0.859 |
| BTCV-Cervix [38] | 0.598 | 0.640 | 0.611 | 0.672 | 0.736 | 0.775 |
| VerSe [40] | 0.786 | 0.828 | 0.832 | 0.825 | 0.896 | 0.906 |
| AbdomenCT-1K [5] | 0.934 | 0.939 | 0.921 | 0.935 | 0.903 | 0.940 |
| AMOS22 [21] | 0.854 | 0.854 | 0.824 | 0.841 | 0.785 | 0.856 |
| TotalSegV2 [7] | 0.882 | *0.906 | *0.942 | 0.893 | 0.884 | 0.918 |
| Average | 0.706 | 0.718 | - | 0.711 | 0.760 | 0.792 |
- VISTA3D는 테스트 데이터에서 127개 클래스에 대해 자동 분할에서 경쟁력 있는 성능을 달성한다.
- 대화형 가지는 보지 못한 클래스에 대한 제로샷 분할을 효과적으로 가능하게 하며, 포인트 프롬프트를 반복적으로 사용하면서 성능이 향상된다.
- 여러 데이터셋에서 VISTA3D auto+point는 단일 클릭으로 평가될 때 기본 방법보다 우수한 성능을 보여 강력한 대화형 정제 능력을 입증한다.
- 소수의 사례(1~10건)로의 미세조정은 mouse micro-CT와 WORD 데이터셋에서 VISTA3D가 베이스라인보다 더 큰 이득을 얻는다.
- 제로샷 결과는 대화형 제로샷 접근 방식을 사용할 때 외부 데이터셋(마우스 기관 및 부신/간 종양)에서 분할이 향상됨을 보여준다.
- 자동 가지에 대한 합성 데이터를 포함시키면 다양한 구조에 걸쳐 강인성이 추가로 향상된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.