[논문 리뷰] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
VAR은 이미지 자기회귀를 다음 규모 예측으로 재구성하여 거친-세부(coarse-to-fine) 병렬 토큰 맵 생성을 가능하게 하며, ImageNet 256×256에서 확산 트랜스포머보다 더 빠른 추론 속도로 성능이 앞섭니다.
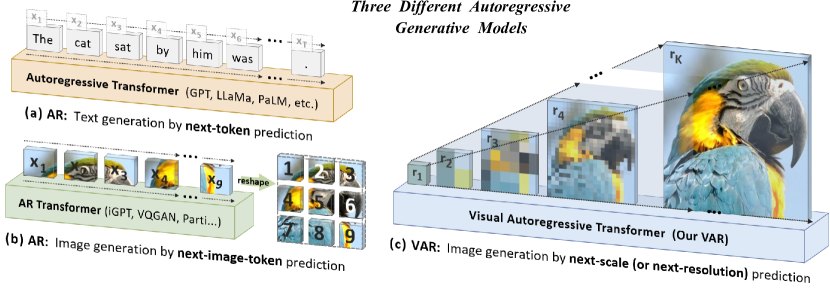
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-like AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
연구 동기 및 목표
- LLM 및 인간 시각 계층 구조에서 영감을 받은 이미지의 확장 가능한 자기회귀 패러다임을 고안한다.
- 공간 구조를 보존하고 효율성을 향상시키는 다중 스케일 토크나이제이션과 next-scale 자기회귀 학습 체계를 개발한다.
- 스케일링 법칙, 제로샷 일반화, 그리고 확산 모델 대비 경쟁력 있는(또는 우수한) 이미지 품질을 입증한다.
제안 방법
- 다중 스케일 VQVAE 토크나이제이션으로 증가 해상도에서 K 토큰 맵을 생성한다.
- p(r1,r2,...,rK)=Πp(rk|r1,...,rk-1) 형태의 next-scale 자기회귀 모델링을 정의하고 각 rk를 병렬로 생성한다.
- conditioning을 위한 AdaLN과 폭, 깊이, 드롭아웃에 대한 단순한 스케일 규칙을 사용하는 GPT-2 스타일 디코더-전용 트랜스포머를 사용한다.
- VQVAE 재구성과 VAR에 대한 표준 크로스 엔트로피(토큰) 손실을 결합 손실로 학습한다.
- VAR이 생성 복잡도를 O(n4)로 축소하고 각 스케일 내에서 병렬 토큰 생성을 달성함을 입증한다.

실험 결과
연구 질문
- RQ1거친-세부(multi-scale) 자기회귀 프레임워크가 래스터-스캔 AR 방법에 비해 이미지 생성 품질과 속도를 향상시킬 수 있는가?
- RQ2VAR 모델이 LLM과 유사한 스케일링 법칙 및 제로샷 일반화를 보이는가?
- RQ3다중 스케일 토큰 맵이 시공간 지역성, 학습 역학, 데이터 효율성에 어떤 영향을 미치는가?
- RQ4VAR 모델이 FID/IS, 속도, 확장성 측면에서 확산 기반 트랜스포머와 경쟁력 있거나 우수한가?
주요 결과
| 유형 | 모델 | FID ↓ | IS ↑ | Pre ↑ | Rec ↑ | #매개변수 | #스텝 | 시간 |
|---|---|---|---|---|---|---|---|---|
| AR | VQGAN† [19] | 18.65 | 80.4 | 0.78 | 0.26 | 1.4B | 256 | 24 |
| AR | VQGAN-re [19] | 5.20 | 280.3 | - | - | 1.4B | 256 | 24 |
| AR | VQVAE-2 † [52] | 31.11 | ~45 | 0.36 | 0.57 | 13.5B | 5120 | - |
| Diff. | ADM [16] | 10.94 | 101.0 | 0.69 | 0.63 | 554M | 250 | 168 |
| Diff. | CDM [25] | 4.88 | 158.7 | - | - | - | 8100 | - |
| Diff. | DiT-L/2 [46] | 5.02 | 167.2 | 0.75 | 0.57 | 458M | 250 | 31 |
| Diff. | DiT-XL/2 [46] | 2.27 | 278.2 | 0.83 | 0.57 | 675M | 250 | 45 |
| Diff. | L-DiT-3B [2] | 2.10 | 304.4 | 0.82 | 0.60 | 3.0B | 250 | - |
| Diff. | L-DiT-7B [2] | 2.28 | 316.2 | 0.83 | 0.58 | 7.0B | 250 | - |
| MaskGIT [11] | MaskGIT-re [11] | 4.02 | 355.6 | - | - | 227M | 8 | 0.5 |
| MaskGIT [11] | MaskGIT [11] | 6.18 | 182.1 | 0.80 | 0.51 | 227M | 8 | 0.5 |
| AR | VAR-d16 | 3.60 | 257.5 | 0.85 | 0.48 | 310M | 10 | 0.4 |
| AR | VAR-d20 | 2.95 | 306.1 | 0.84 | 0.53 | 600M | 10 | 0.5 |
| AR | VAR-d24 | 2.33 | 320.1 | 0.82 | 0.57 | 1.0B | 10 | 0.6 |
| AR | VAR-d30 | 1.97 | 334.7 | 0.81 | 0.61 | 2.0B | 10 | 1 |
| AR | VAR-d30-re | 1.80 | 356.4 | 0.83 | 0.57 | 2.0B | 10 | 1 |
- VAR는 ImageNet 256×256에서 2B 파라미터로 FID 1.80 및 IS 356.4를 달성하고, 기본 AR 모델 대비 추론 속도가 20× 더 빠르다.
- VAR은 여러 모델 규모에서 Diffusion Transformer(DiT)보다 FID, IS, 데이터 효율성 및 확장성 면에서 우수하다.
- VAR은 LLM과 유사한 모델 규모와 계산에서 멀티로그 스케일링 법칙을 보이며, 더 큰 모델과 더 많은 학습 계산에서 성능이 향상됨을 시사한다.
- 특수한 아키텍처 변경 없이 제로-샷 특성은 인페인트(in-painting), 아웃-페인팅(out-painting), 편집 작업에서 입증된다.
- VAR 기반 모델은 품질과 효율성 측면에서 전통적인 AR 기반(예: VQGAN 기반 AR) 대비 크게 우수하다.
- 512×512 합성에서, d36을 사용한 VAR은 FID 2.63 및 IS 303.2를 달성하였으며 시간 측면에서도 경쟁력을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.