[논문 리뷰] Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
시각-사고 체인(VCoT)은 시퀀스 데이터의 논리적 간극을 메우기 위해 다중모달 인필링을 생성하고 선택함으로써 비전-언어 도메인에 사고 흐름 프롬프팅을 확장하고, 데이터 증강을 통해 시각적 스토리텔링 및 WikiHow 요약과 같은 하류 추론 작업을 개선합니다.
Recent advances in large language models elicit reasoning in a chain-of-thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain-of-thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain-of-thought baselines, which can be used to enhance downstream performance.
연구 동기 및 목표
- 텍스트에서 다중모달 시퀀스로의 사고 흐름 추론을 확장하여 논리적 간극을 해결하려는 동기 부여.
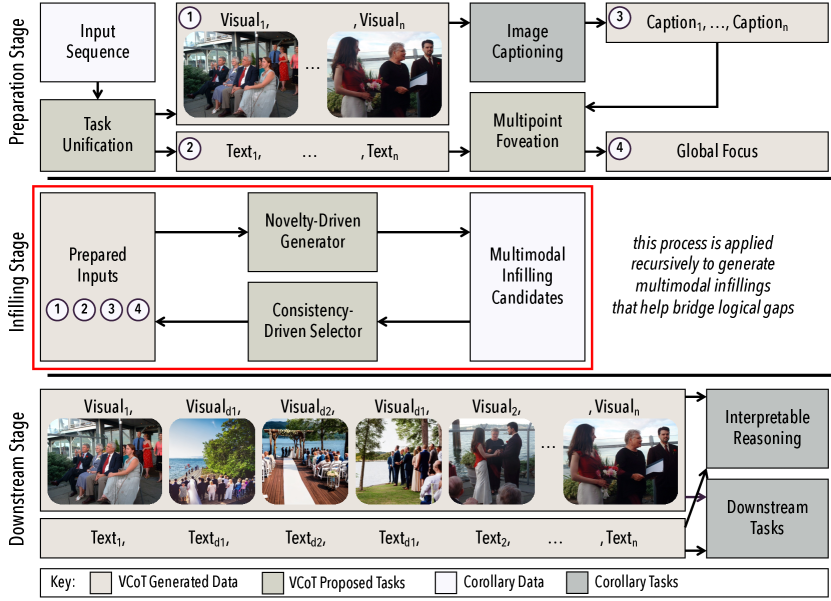
- 합성 텍스트-비주얼 인필링을 생성하는 학습-free, 반복적 생성-선택 프레임워크를 제안.
- 다른 태스크에 대한 데이터 증강을 가능하게 하면서 다단계 추론에 대한 해석 가능한 통찰을 제공.
제안 방법
- Stable Diffusion으로 텍스트 전용 데이터를 위한 후보 비주얼을 생성하고 CLIP으로 주어진 텍스트와의 유사도를 가장 잘 맞는 것을 선택하여 텍스트-비주얼 쌍으로 시퀀스를 통합합니다.
- 다중 포인트 포베이션을 통해 입력 시퀀스에서 글로벌 포커스를 추출하고 일관된 인필링 생성을 안내합니다.
- GPT-3.5와 시각적 정 grounding에 의해 안내되는 신선함(novelty) 및 일관성에 기반한 접근으로 다중 모달 인필링을 재귀적으로 생성합니다.
- CLIP 기반 유사도로 가장 일관된 텍스트 및 비주얼 인필링을 선택하고 고정 재귀 깊이(depth-limit = 2)를 사용합니다.
- 새로움, 일관성, 응집성, 서술성을 강조하는 인간 판단으로 인필링을 평가합니다.

실험 결과
연구 질문
- RQ1시각적 및 텍스트 컨텍스트에서 생성된 다중모달 인필링이 하류 작업의 논리적 간극을 메울 수 있는가?
- RQ2VCoT 인필링은 비주얼-언어 태스크 전반에서 단일 모달 사고 흐름 기반 대조군에 비해 일관성과 새로움을 향상시키는가?
- RQ3합성 다중모달 증강은 시각적 스토리텔링 및 WikiHow 스타일 요약의 하향 성능에 어떤 영향을 미치는가?
- RQ4생성된 인필링 간의 일관성을 유지하는 데 있어 정 grounding 및 포베이션의 역할은 무엇인가?
주요 결과
- VCoT 인필링은 인간 평가자가 Chain-of-Thought(CoT) 및 Chain-of-Images(CoI) 기준선보다 새로움과 일관성에서 더 높은 점수를 부여했다.
- VCoT는 WikiHow 요약 및 시각적 스토리텔링에서 기준선 대비 하류 성능을 향상시켰으며, WikiHow에서 새로움 이점이 더 크고 Vist에서 일관성이 더 나아졌다.
- 일관성은 다중 포베이션과 CLIP-가이드 선택에 의해 촉진되고, 새로움은 텍스트 인필링의 GPT-3.5 주도 생성과 Stable Diffusion으로 생성된 비주얼을 통해 달성된다.
- VCoT은 추론 과정의 다중모달 해석가능성을 제공하고 순차 추론의 데이터 증강으로서 논리적 도약을 줄여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.