[논문 리뷰] Visual Instruction Tuning
이 논문은 LLaVA를 도입합니다. 이는 vision encoder와 LLM을 GPT-4가 생성한 비전-언어 데이터로 지시를 학습시켜 대화를 가능하게 하는 대형 다중모달 모델이며, GPT-4와 결합할 때 ScienceQA에서 최첨단 성능을 달성합니다.
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
연구 동기 및 목표
- 비전-언어 모델에 대한 지시 학습 확장을 통해 일반 목적의 시각적 어시스턴트를 가능하게 한다는 동기를 제시한다.
- 언어 모델을 사용하여 다중모달 지시-수행 데이터를 생성하는 확장 가능한 파이프라인을 제공한다.
- 비전 인코더와 언어 모델을 결합한 대형 다중모달 모델인 LLaVA를 개발·평가한다.
- 멀티모달 지시 수행을 위한 챗과 추론 과제를 위한 벤치마크(LLaVA-Bench)를 생성하고 공개한다.
제안 방법
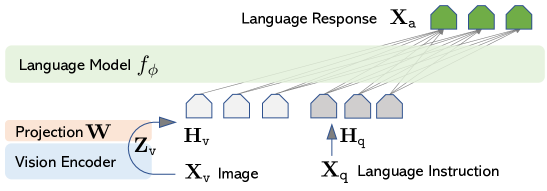
- CLIP 비주얼 인코더를 Vicuna 언어 모델에 학습 가능한 프로젝션 W를 통해 연결해 시각 토큰을 생성한다.
- 이미지-텍스트 데이터를 바탕으로 GPT-4(및 이전의 ChatGPT)로부터 대화, 상세 설명, 복합 추론의 세 가지 형식으로 158K 개의 다중모달 지시-수행 샘플을 생성한다.
- 2단계 학습: 1단계는 CC3M의 서브샘플을 사용해 이미지 특징을 LLM 임베딩과 맞춰 시각 토크나이저를 예비 학습한다; 2단계는 생성된 데이터로 W와 φ(LM)을 이용해 엔드 투 엔드로 미세 조정한다.
- 다중모달 챗 데이터를 사용해 학습하고 다중모달 챗 및 ScienceQA에서 평가한다; 결과 향상을 위해 GPT-4를 앙상블한다.
실험 결과
연구 질문
- RQ1GPT-4가 생성한 비전-언어 데이터가 다중모달 모델의 효과적인 시각 지시 학습을 가능하게 하는가?
- RQ2CLIP-Vicuna 아키텍처가 GPT-4 생성 데이터 파이프라인과 결합될 때 열린 멀티모달 과제에서 얼마나 잘 작동하는가?
- RQ3LLaVA를 GPT-4와 결합하면 멀티모달 추론 벤치마크에서 최첨단 성과를 낼 수 있는가?
- RQ4대화, 상세 설명, 복합 추론 등 서로 다른 유형의 지시 수행 데이터가 다중모달 정렬에 어떤 가치를 제공하는가?
주요 결과
| 모델 | 대화 | 상세 설명 | 복합 추론 | 전체 |
|---|---|---|---|---|
| OpenFlamingo | 19.3 ± 0.5 | 19.0 ± 0.5 | 19.1 ± 0.7 | 19.1 ± 0.4 |
| BLIP-2 | 54.6 ± 1.4 | 29.1 ± 1.2 | 32.9 ± 0.7 | 38.1 ± 1.0 |
| LLaVA | 57.3 ± 1.9 | 52.5 ± 6.3 | 81.7 ± 1.8 | 67.3 ± 2.0 |
| LLaVA † | 58.8 ± 0.6 | 49.2 ± 0.8 | 81.4 ± 0.3 | 66.7 ± 0.3 |
- LLaVA는 강력한 멀티모달 챗 능력을 달성하여 보지 않은 이미지와 지시에서 멀티모달 GPT-4에 근접한다.
- 합성 다중모달 지시-수행 데이터 셋에서 LLaVA는 GPT-4 대비 상대 점수 85.1%를 달성한다.
- ScienceQA에 대해 GPT-4 앙상블로 미세 조정하면 새로운 최첨단 정확도 92.53%를 달성한다.
- LLaVA-Bench(In-the-Wild)는 지시 학습의 큰 이점을 보여주며 세 가지 데이터 유형 모두 85.1%의 최고의 전체 성능을 제공한다.
- 근거 연구는 사전 학습 및 모델 규모가 결과에 실질적으로 영향을 미치며, 13B LLaVA 모델은 ScienceQA에서 90.92%를 달성하고 GPT-4와 결합 시 SOTA에 진입한다.
![Table 3 : Example prompt from GPT-4 paper [ 36 ] to compare visual reasoning and chat capabilities. Compared to BLIP-2 [ 28 ] and OpenFlamingo [ 5 ] , LLaVA accurately follows the user’s instructions, instead of simply describing the scene. LLaVA offers a more comprehensive response than GPT-4. Even](https://ar5iv.labs.arxiv.org/html/2304.08485/assets/figures/img_extreme_ironing.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.