[논문 리뷰] VisualBERT: A Simple and Performant Baseline for Vision and Language
VisualBERT는 텍스트와 이미지 영역을 동시에 인코딩하는 간단한 Transformer 기반 모델로, COCO 자막으로의 사전 학습과 시각적-언어 목표 두 가지를 활용해 다수의 비전-언어 과제에서 경쟁력 있는 결과를 얻습니다.
We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks. VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. We further propose two visually-grounded language model objectives for pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2, and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between verbs and image regions corresponding to their arguments.
연구 동기 및 목표
- 다양한 과제(VQA, VCR, NLVR 2, Flickr30K)에서 시각과 언어를 함께 추론하는 간단하고 유연한 모델을 동기화한다.
- 어떤 특화된 과제 아키텍처 없이도 언어 토큰을 이미지 영역 제안과 암묵적으로 정렬하기 위해 Transformer 자기 주의( self-attention )를 활용한다.
- 이미지-자막 데이터에 대한 태스크 독립적(pre-training) 사전 학습이 다운스트림 V+L 과제로의 전달을 향상시킨다는 것을 보여준다.
제안 방법
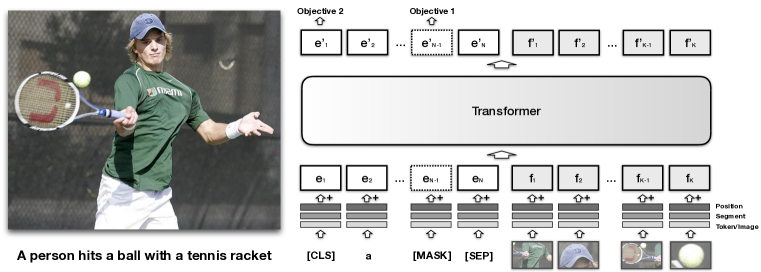
- 객체 탐지기로부터 파생된 이미지 영역에 대한 시각 임베딩으로 BERT를 확장한다.
- 텍스트 임베딩과 시각 임베딩을 연결하고 이를 공유 Transformer 스택에 입력하여 공동 처리한다.
- COCO 자막에 대해 두 가지 목표로 VisualBERT를 사전 학습한다: 이미지 맥_CONTEXT를 활용한 마스킹 언어 모델링과 문장-이미지 매칭.
- 다운스트림 비전-언어 과제에서 엔드-투-엔드로 미세 조정하며, 태스크 데이터에 대한 선택적 태스크-특정 사전 학습을 수행한다.
- 초기 융합 없이 VisualBERT를 포함한 변형과 COCO 사전 학습 없이 구성 요소 기여를 평가한다.
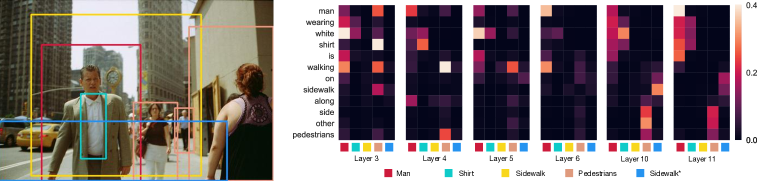
실험 결과
연구 질문
- RQ1하나의 단일 Transformer 기반 아키텍처가 다수의 V+L 과제에서 시각과 언어를 함께 모델링할 수 있는가?
- RQ2모든 Transformer层에서 시각적 특징과 텍스트 특징의 초기 융합이 성능을 향상시키는가?
- RQ3이미지-자막 데이터에 대한 태스크 독립적 사전 학습이 다운스트림 과제로의 전이에서 얼마나 중요한가?
- RQ4어떤 주의(head)가 언어를 이미지 영역에 정ground하고 구문 관계를 반영하는가?
주요 결과
| 모델 | 테스트-Dev | 테스트-Std |
|---|---|---|
| VisualBERT | 70.80 | 71.00 |
- VisualBERT는 VQA 2.0, VCR, NLVR 2, Flickr30K 정ground에서 경쟁력 있거나 더 우수한 성능을 달성하며, 더 복잡한 베이스라인을 능가하는 경우가 많다.
- 시각과 언어의 초기 융합(트랜스포머 레이어 간의 상호 작용)은 강력한 성능을 위한 결정적 요소이다.
- COCO 자막에 대한 태스크 독립적 사전 학습은 결과를 상당히 향상시키며, COCO 사전 학습을 건너뛰면 성능이 저하된다.
- VisualBERT는 명시적 감독 없이도 언어를 이미지 영역에 근거시킬 수 있으며, 특정 주의 헤드는 구문 의존 관계(예: 동사와 그 인수)를 추적한다.
- 정성적 분석은 주의 패턴이 층 간 정렬을 다듬고 시간이 지남에 따라 모호한 근거를 해결할 수 있음을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.