[논문 리뷰] VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model
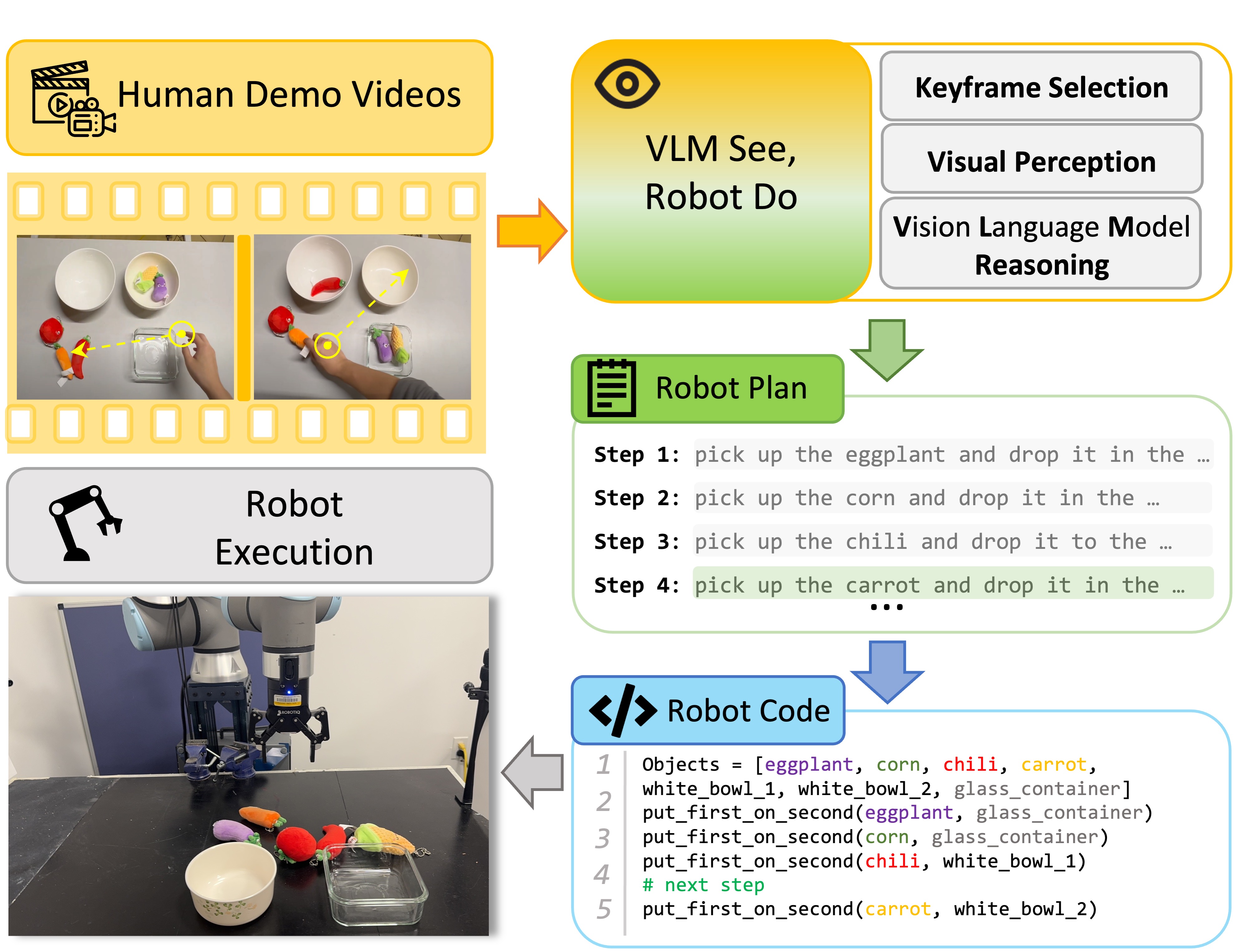
SeeDo는 핵심 프레임 선택과 시각 인지 프롬프트를 갖춘 비전-언어 모델 파이프라인을 사용하여 인간 시연 비디오를 로봇 작업 계획으로 변환하고, 시뮬레이션과 실제 로봇에서 언어 모델 프로그램으로 실행됩니다.
Vision Language Models (VLMs) have recently been adopted in robotics for their capability in common sense reasoning and generalizability. Existing work has applied VLMs to generate task and motion planning from natural language instructions and simulate training data for robot learning. In this work, we explore using VLM to interpret human demonstration videos and generate robot task planning. Our method integrates keyframe selection, visual perception, and VLM reasoning into a pipeline. We named it SeeDo because it enables the VLM to ''see'' human demonstrations and explain the corresponding plans to the robot for it to ''do''. To validate our approach, we collected a set of long-horizon human videos demonstrating pick-and-place tasks in three diverse categories and designed a set of metrics to comprehensively benchmark SeeDo against several baselines, including state-of-the-art video-input VLMs. The experiments demonstrate SeeDo's superior performance. We further deployed the generated task plans in both a simulation environment and on a real robot arm.
연구 동기 및 목표
- 비전-언어 모델을 사용하여 장기 시나리오의 인간 시연 비디오로부터 로봇 학습을 촉진한다.
- 하위 작업 분해를 통해 비디오를 로봇 작업 계획으로 해석하는 파이프라인을 개발한다.
- 지각 강화 추론을 통해 VLM의 영상 처리 및 공간 관계 도전 과제를 완화한다.
- 다양한 장기 태스크에 걸쳐 SeeDo를 최첨단 비디오 VLM과 벤치마크한다.
제안 방법
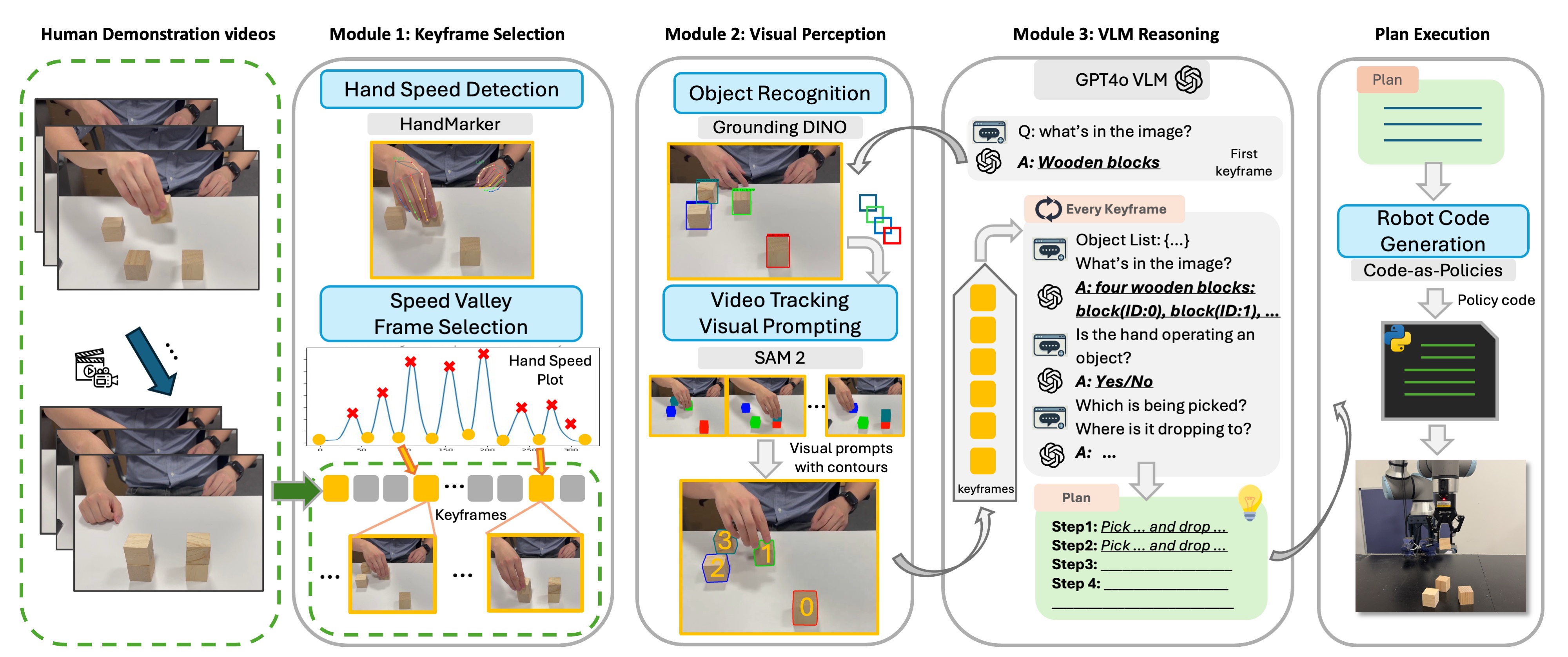
- 세 모듈로 구성된 SeeDo 파이프라인: Keyframe Selection, Visual Perception, 및 VLM Reasoning.
- Hand-speed 기반의 Keyframe 추출을 사용하여 중요한 동작 프레임을 포착한다.
- 객체 추적 및 시각 프롬프트(윤곽, ID, 중심) 적용으로 VLM 인식을 향상시킨다.
- 체인 오브 생각(chain-of-thought) 프롬트로 GPT-4o를 활용하여 작업 계획을 생성한다.
- 생성된 계획을 Language Model Programs (LMPs)으로 변환하여 로봇 API를 통해 실행한다.
- 시뮬레이션(Pybullet)과 UR10e 실제 로봇을 아우르는 세 가지 태스크에 대해 평가한다.
실험 결과
연구 질문
- RQ1비전-언어 모델이 인간 시연 비디오를 해석하여 실행 가능한 로봇 계획을 생성할 수 있는가?
- RQ2Keyframe 선택 및 시각 인지 모듈을 추가하면 VLM 기반 계획의 시간적 및 공간적 추론이 향상되는가?
- RQ3장기 태스크에서 SeeDo가 최첨단 비디오 VLM과 어떤 차이가 있는가?
- RQ4생성된 작업 계획이 시뮬레이션과 실제 하드웨어 모두로 옮겨질 수 있는가?
주요 결과
- SeeDo는 모든 태스크에서 TSR, FSR, SSR에 대해 baselines(비공개 및 오픈 소스 비디오 VLM)보다 우수하다.
- SSRs은 SeeDo 구성에서 목재 블록에서 52.48% 이상, 의류 정리에서 66.50%를 초과한다.
- 채소 정리에서 SeeDo는 TSR 60.53%, FSR 60.53%이고 SSR은 80.40%로 다른 모델을 능가한다.
- 시각 프롬프트는 공간 추론을 현저히 개선하며 프롬프트 없는 SeeDo와 비교했을 때 공간 오차율을 감소시킨다.
- ablation은 키프레임 샘플링과 손 감지 기반 키프레임이 맥락과 성능 유지를 위해 결정적임을 보여준다.
- 생성된 작업 계획은 시뮬레이션 및 실제 UR10e 설비 모두에서 LMP로 실행될 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.