[논문 리뷰] Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
본 논문은 Voice Transformer Network (VTN)를 소개하며, Transformer 기반의 seq2seq 음성 변환 모델과 데이터 효율성 및 음질 향상을 위한 두 단계 Text-to-Speech 사전학습 전략을 활용하여 RNN 기반 기준모형을 능가한다.
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.
연구 동기 및 목표
- 억양과 지속 시간 변화 를 포착하기 위한 seq2seq 음성 변환(VC)의 동기를 제시한다.
- VC를 위해 Transformer 아키텍처를 활용하여 RNN/CNN 기반 모델을 대체한다.
- 데이터 효율성을 높이고 잘못 발음들을 줄이기 위한 두 단계의 TTS 기반 사전학습을 도입한다.
- 제한된 VC 데이터로도 TTS-사전학습 VC가 고품질이며 이해 가능한 음성을 산출함을 입증한다.
제안 방법
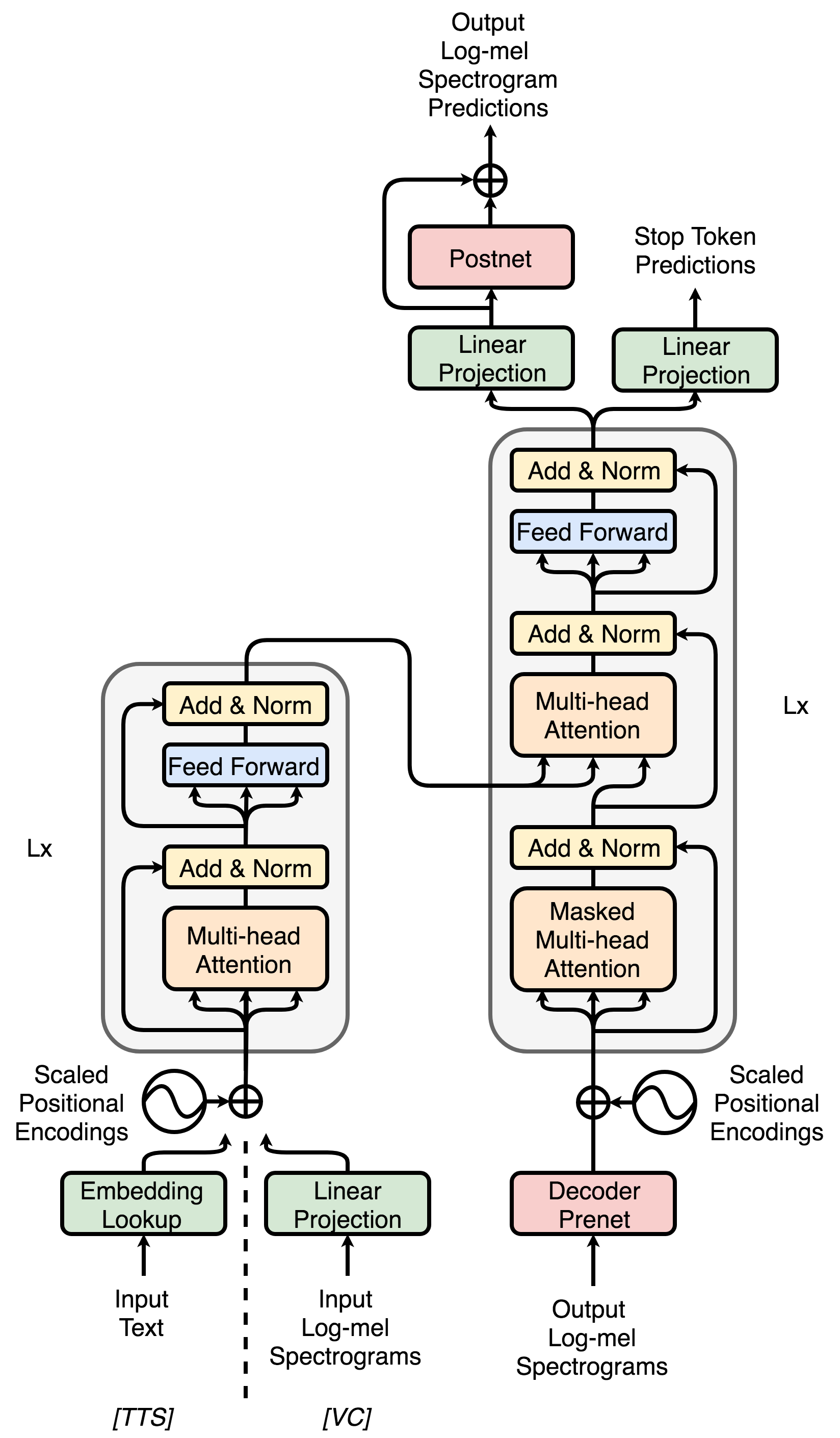
- 인코더 입력 임베딩을 선형 투영으로 교체하여 VC를 위한 Transformer-TTS 아키텍처를 적응시킨다.
- 학습 중 어텐션을 안정시키고 프레임을 스택하기 위한 인코더 축소 계수(reduction factor)를 도입한다.
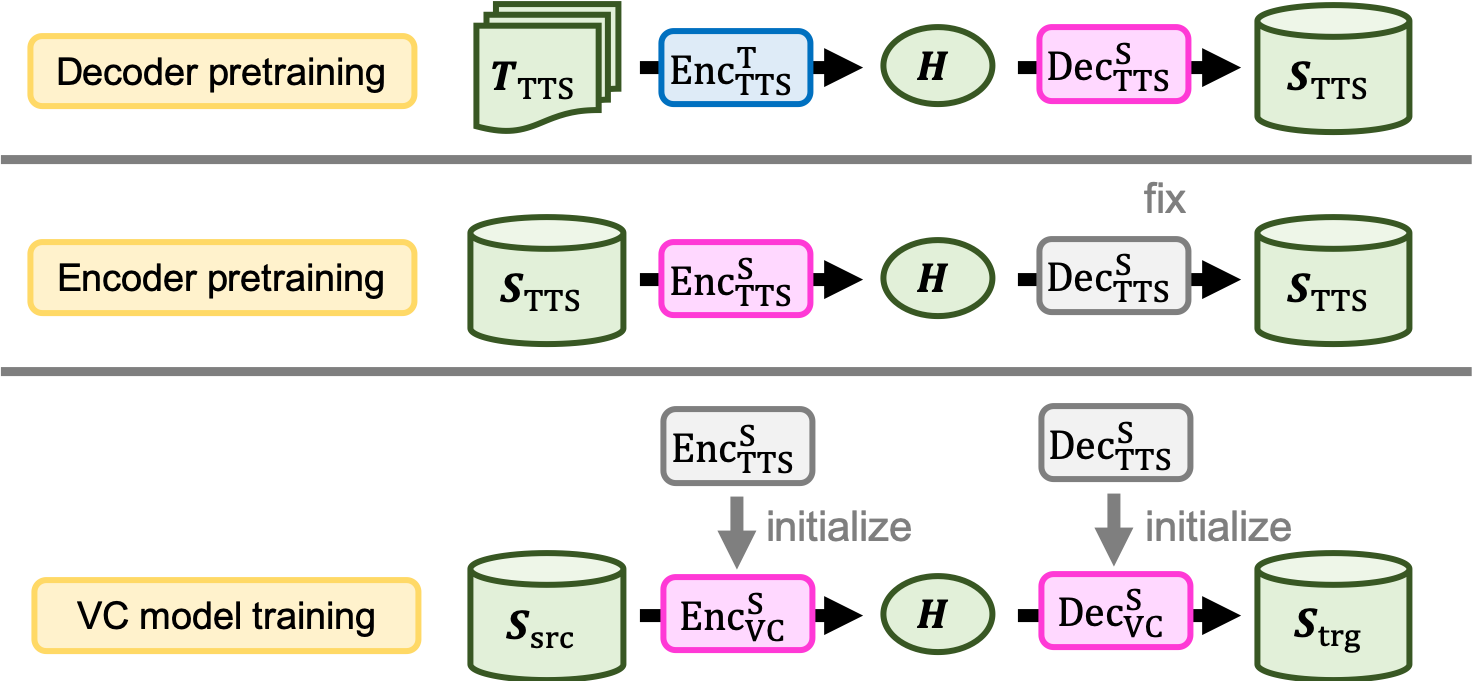
- 대규모 TTS 데이터로 디코더를 사전학습하고, 고정된 사전학습 디코더를 이용한 오토인코더를 통해 인코더를 사전학습하는 두 단계의 사전학습을 제안한다.
- 다중 화자, 비병렬 TTS 및 VC 데이터를 사용하고, TTS에서 VC로 미세한 표현을 전이시키는 두 단계 훈련을 수행한다.
- 스펙트럴 충실도와 가독성을 평가하기 위해 MCD, CER, WER 및 MOS 스타일의 주관적 평가로 평가한다.
실험 결과
연구 질문
- RQ1Transformer 기반 seq2seq VC 모델이 RNN 기반 seq2seq VC 모델보다 더 높은 이해 가능성과 자연스러움을 달성할 수 있는가?
- RQ2대규모 TTS 데이터로 VC 구성 요소를 사전학습하는 것이 작은 VC 데이터 데이터 세트에서 데이터 효율성과 강건성을 향상시키는가?
- RQ3제안된 VC 시스템은 스펙트럴 왜곡, ASR 호환성, 지각적 자연스러움 및 유사성 측면에서 어떻게 성능을 보이는가?
주요 결과
- VTN with TTS pretraining consistently outperforms the baseline ATTS2S on objective metrics when trained with the same data.
- Encoder pretraining combined with decoder pretraining yields robust gains, particularly as VC data size decreases.
- With full training data, VTN significantly improves naturalness and similarity over the baseline in subjective tests.
- Even with very limited VC data (e.g., 80 utterances), VTN remains superior to the baseline, indicating strong data efficiency.
- Compared to TTS adaptation alone, VTN with pretraining can achieve higher naturalness and similarity due to better prosody preservation and linguistic representations.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.