[논문 리뷰] VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
이 논문은 대상 화자 임베딩을 사용하여 스피커-컨디션드 스펙트로그램 마스킹을 수행하는 두 네트워크 시스템인 VoiceFilter를 소개합니다. 다중 화자 혼합에서 대상 음성을 효과적으로 추출하고, 깨끗한 음성에 거의 영향을 미치지 않으면서 ASR WER를 개선합니다.
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
연구 동기 및 목표
- 대상의 스피치 분리를 사전에 화자 수를 알지 못해도 가능하게 하는 동기를 제공한다.
- 대상 화자를 위한 견고한 임베딩을 생성하는 화자 인코더를 개발한다.
- 대상 화자 임베딩을 이용해 간섭을 억제하는 스펙트로그램 마스킹 네트워크를 설계한다.
- 다중 화자 데이터에서 WER 개선을 입증하면서 단일 화자 성능은 보존한다.
제안 방법
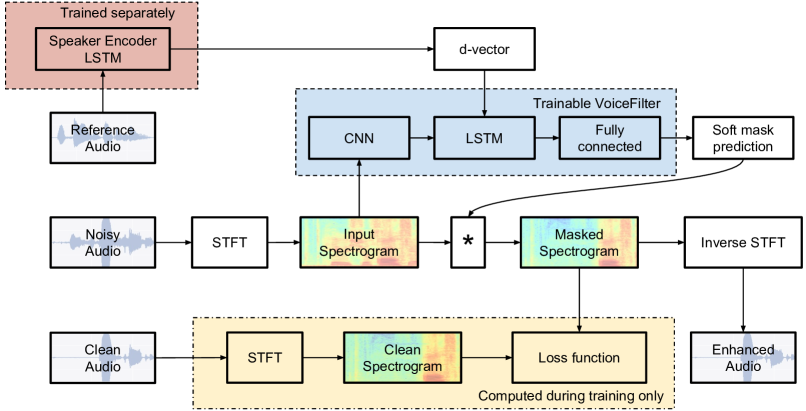
- 로그-멜(feature)로부터 256-dim d-vector를 생성하는 3-layer LSTM 화자 인코더를 학습시킨다.
- 대상 화자 d-vector와 잡음이 섞인 크기 스펙트로그램에 조건부로 작용하는 스펙트로그램 마스킹 네트워크를 학습시켜 소프트 마스크를 예측한다.
- 컨볼루션 및 LSTM 계층 사이에 d-vector를 주입해 시간-주파수 처리 특성을 보존한다.
- 강화된 크기 스펙트로그램과 대상 청정 크기 스펙트로그램 간의 재구성 손실로 마스크를 최적화한 뒤, 원래 위상으로 파형을 재구성한다.
- 학습 중에 16 kHz에서 3초 길이의 구간으로 음성을 처리한다.
- WER(단어 오류율)과 SDR(원천 왜곡 비율)을 사용해 평가한다.
실험 결과
연구 질문
- RQ1대상 화자 임베딩이 간섭 화자 수를 모르는 상태에서 엔드-투-엔드 분리를 가능하게 할 수 있는가?
- RQ2화자 조건화가 전통적 분리 방법에 비해 WER 및 SDR에 어떤 영향을 미치는가?
- RQ3다양한 시간 모델(℧ LSTM 없음, 단방향 LSTM, 양방향 LSTM) 간의 성능 차이는 어떻게 나타나는가?
- RQ4더 크고 다양한 데이터셋으로의 학습이 도메인 간 일반화에 기여하는가(LibriSpeech에서 VCTK 등로의 일반화 여부)?
주요 결과
- Bi-directional LSTM VoiceFilter가 잡음이 있는 LibriSpeech 데이터에서 최적의 WER를 달성한다(uni-LSTM의 23.4% vs 28.2%, LSTM 없음의 35.3%).
- VoiceFilter는 LibriSpeech 이중 화자 혼합에서 Noisy WER를 55.9%에서 23.4%로 감소시킨다(LibriSpeech 학습).
- LibriSpeech에서 Noisy WER 개선은 최적 모델로 상대적으로 58.1% 감소를 보이며 Clean WER은 Clean 기준선에 가깝게 유지된다(11.1% vs 10.9%).
- VCTK에서 LibriSpeech로 학습하면 Noisy WER가 60.6%에서 34.3%로 개선되며, Clean WER은 다소 감소(5.9% vs 6.1%); VCTK로 학습하면 Clean WER가 더 높아진다(21.1%).
- SDR 결과는 WER 추세와 일치한다; bi-LSTM이 LibriSpeech에서 평균/중간 SDR(17.9 dB/12.6 dB)을 가장 높게 달성한다.
- 화자 임베딩을 사용한 VoiceFilter가 permutation-invariant 손실 기반의 기준선보다 우수하여 대상 화자 조건화의 이점을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.