[논문 리뷰] Voices Obscured in Complex Environmental Settings (VOICES) corpus
VOICES 코퍼스는 LibriSpeech 전경을 다양한 방해 소음과 함께 사용하는 실제 소음실의 원거리 다중 마이크 음성 데이터를 개방적으로 제공하며 baselines ASR 및 SID 평가를 포함합니다.
This paper introduces the Voices Obscured In Complex Environmental Settings (VOICES) corpus, a freely available dataset under Creative Commons BY 4.0. This dataset will promote speech and signal processing research of speech recorded by far-field microphones in noisy room conditions. Publicly available speech corpora are mostly composed of isolated speech at close-range microphony. A typical approach to better represent realistic scenarios, is to convolve clean speech with noise and simulated room response for model training. Despite these efforts, model performance degrades when tested against uncurated speech in natural conditions. For this corpus, audio was recorded in furnished rooms with background noise played in conjunction with foreground speech selected from the LibriSpeech corpus. Multiple sessions were recorded in each room to accommodate for all foreground speech-background noise combinations. Audio was recorded using twelve microphones placed throughout the room, resulting in 120 hours of audio per microphone. This work is a multi-organizational effort led by SRI International and Lab41 with the intent to push forward state-of-the-art distant microphone approaches in signal processing and speech recognition.
연구 동기 및 목표
- 현실적인 룸 음향과 배경 소음으로 자유롭게 접근 가능한 원거리 마이크 음성 코퍼스를 제공하여 음성 및 신호 처리 연구를 발전시키는 것
- 다중 룸 녹음을 다양한 마이크 배치와 방해 소음으로 실제 환경 조건을 반영하는 것
- VOICES 데이터에 대한 벤치마크 모델링을 위한 베이스라인 ASR 및 화자 식별 결과를 제시하는 것
- 잡음 환경에서 이벤트/백그라운드 탐지, 소스 분리, 음성 향상 및 위치추정 연구를 촉진하는 것
제안 방법
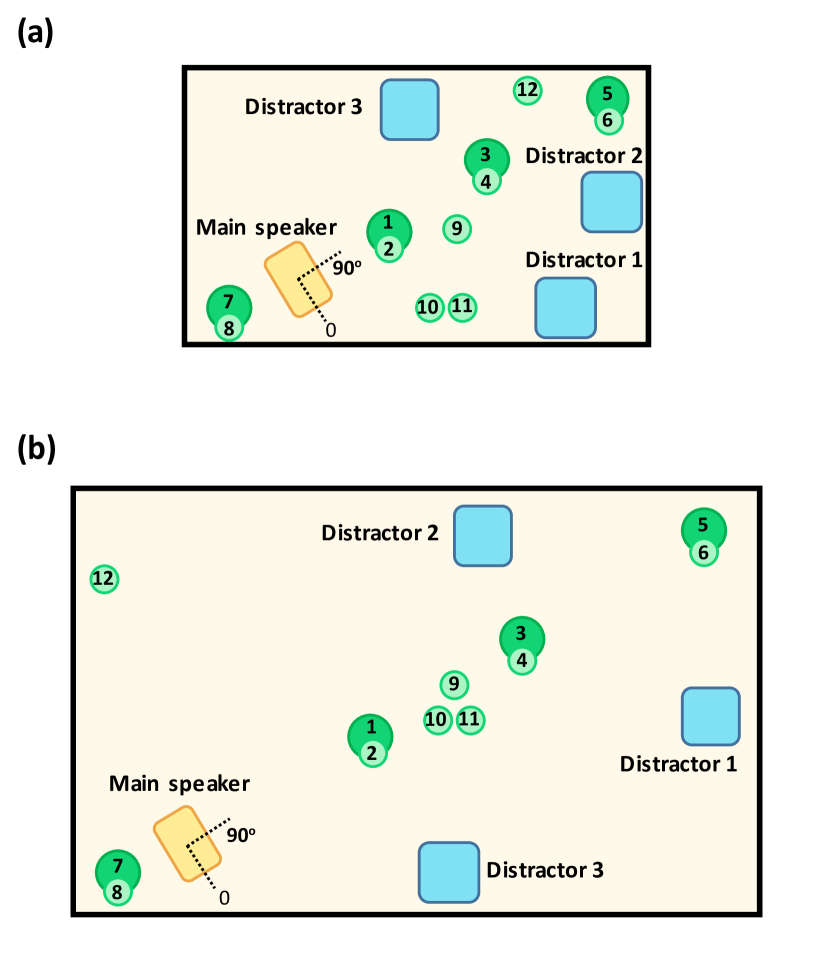
- 두 개의 가구가 비치된 서로 다른 음향 프로필의 방에서 LibriSpeech 파생 전경 음성을 녹음하는 것
- 전경 음성과 함께 synchronized한 방해 소음(TV, 음악, 잡음)들을 재생하고 12개의 원거리 마이크로 녹음하는 것
- 마이크당 120시간의 데이터(374,688 개의 오디오 파일)를 48 kHz/24-bit(또는 16 kHz 옵션)로 제공하며 원천 오디오와 전사를 함께 제공하는 것
- 헤드 움직임을 시뮬레이션하기 위해 회전하는 전경 화자를 사용하고 반향/잡음 조건을 비교하는 것
- 정식 전사 및 화자 레이블로 주석을 달고 기본 통계(SNR, RMS, 진폭)를 계산하며 baseline ASR/SID 실험을 제공하는 것
실험 결과
연구 질문
- RQ1현실적인 룸 리버브와 방해 소음 하에서 근접 음원에서 학습된 모델이 원거리 마이크 음성 인식을 얼마나 잘 수행하는가?
- RQ2마이크 거리와 룸 음향이 VOICES 코퍼스의 ASR 및 SID 성능에 미치는 영향은 무엇인가?
- RQ3개방된 VOICES 데이터가 소음 환경에서의 음성/화자 인식, 탐지 및 향상을 위한 강인한 음향 모델 개발에 어떤 도움을 주는가?
- RQ4노이즈 유형과 마이크 배치에 따른 VOICES 데이터에서 표준 ASR 및 SID 시스템의 기본 성능은 어느 정도인가?
주요 결과
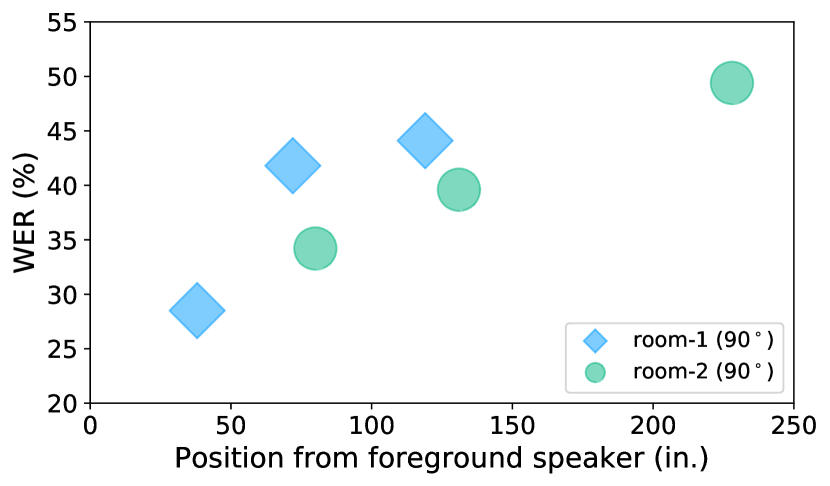
- ASR WER은 거리 및 방해 소음에 따라 크게 증가하는데, 예를 들어 소스 대비 9.3%에서 잡음(베이블) 시 33.0%까지 증가( Room-1, 90°의 SRI 시스템 ).
- 거리 증가로 SID 성능이 저하된다: EER은 소스에서 5.72%에서 Room-1/Room-2의 멀리 있는 마이크에서 15.1–16.6%로 상승(방해 소음 없음).
- 방해 소음은 SID를 추가로 약 2–3.5% 포인트의 EER 감소로 악화시키며 소음 유형에 따라 다름(No distractor 대 TV/음악/잡음).
- 방과 조건 전반의 평균 SNR은 거리에 따라 악화되며 room-1 평균 22.19 dB, room-2 평균 19.50 dB.
- VOICES 데이터세트는 마이크당 120시간, 12개 마이크, 374,688 오디오 파일을 포함하고 화자 식별 및 음성 인식 작업에 LibriSpeech 전경과 맞춘 데이터이다.
- 베이스라인 ASR 결과는 근접 음향 환경과 비교하여 현실적인 음향 환경에서 상당한 악화를 보임을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.