[논문 리뷰] Vulnerability Detection with Code Language Models: How Far Are We?
이 논문은 취약점 탐지를 위한 코드 언어 모델을 평가하고, 기존 벤치마크의 데이터 품질 및 평가의 문제점을 밝히며, 고정밀 라벨링과 중복 제거를 갖춘 PrimeVul를 도입하고, 현재 모델이 현실적인 설정에서 성능이 낮음을 보여준다.
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
연구 동기 및 목표
- 기존 취약점 탐지 데이터셋과 벤치마크의 한계를 분석한다.
- 데이터 누출을 줄이기 위해 고정밀 라벨링과 중복 제거를 갖춘 PrimeVul를 제안한다.
- VD-S 및 페어드 함수 평가를 포함한 현실적인 평가 지침을 도입한다.
- PrimeVul에서 다양한 오픈 소스 코드 LMs를 실험적으로 평가하여 현실적인 성능 기준선을 확립한다.
제안 방법
- 기존 vd 벤치마크의 데이터 수집, 라벨링 정확도, 중복 여부를 비판적으로 분석한다.
- PrimeVul를 두 가지 라벨링 기법(PrimeVul - OneFunc 및 PrimeVul - NVDCheck)과 철저한 중복 제거를 사용하여 구성한다.
- 누출을 줄이고 VD-S 및 페어드 함수 평가를 도입하기 위해 연대순 학습/검증/테스트 분할을 적용한다.
- 현실적인 설정에서 PrimeVul에 대해 여러 오픈 소스 코드 LMs를 미세조정하고 평가한다.
- 실용적 활용도를 평가하기 위해 정확도, F1, VD-S 및 페어-간 결과를 포함한 지표를 보고한다.
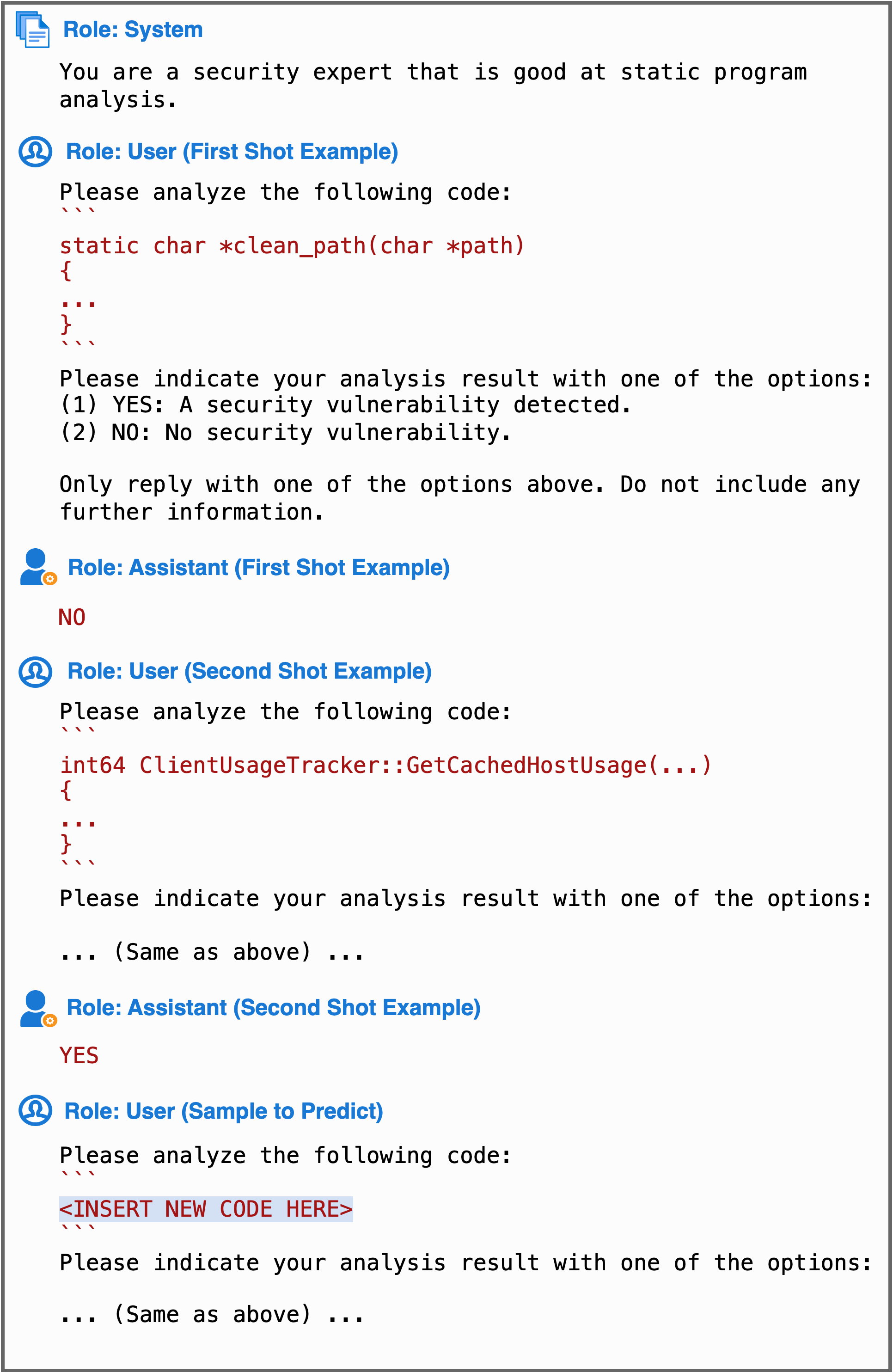
실험 결과
연구 질문
- RQ1RQ1: PrimeVul에서 오픈 소스 코드 LMs의 성능은 어떠한가?
- RQ2RQ2: 고급 학습 기법이 취약점 탐지 성능을 개선할 수 있는가?
- RQ3RQ3: 더 큰 언어 모델(LLMs)이 취약점 탐지 성능을 향상시킬 수 있는가?
주요 결과
| 모델 | 훈련 | 테스트 | 정확도 | F1 | VD-S | P-C | P-V | P-B | P-R |
|---|---|---|---|---|---|---|---|---|---|
| CT5 | BV | BV | 95.67 | 64.93 | 77.30 | 24.98 | 50.90 | 22.79 | 1.33 |
| PV | PV | PV | 97.00 | 5.82 | 95.97 | 0.18 | 3.01 | 96.10 | 0.71 |
| PV | PV | PV | 96.67 | 19.7 | 89.93 | 1.06 | 12.94 | 84.75 | 1.24 |
| CB | BV | BV | 95.57 | 62.88 | 81.77 | 22.60 | 48.34 | 27.83 | 1.23 |
| PV | BV | BV | 97.04 | 4.49 | 95.54 | 0.35 | 1.95 | 96.99 | 0.71 |
| PV | PV | PV | 96.87 | 20.86 | 88.78 | 1.77 | 11.35 | 86.17 | 0.71 |
| UC | BV | BV | 96.46 | 65.46 | 62.30 | 39.60 | 23.74 | 33.24 | 3.42 |
| PV | BV | BV | 97.27 | 1.94 | 95.11 | 0.35 | 0.35 | 98.76 | 0.53 |
| PV | PV | PV | 96.86 | 21.43 | 89.21 | 1.60 | 12.06 | 85.11 | 1.24 |
| SC2 | BV | BV | 96.20 | 68.26 | 69.14 | 35.23 | 41.98 | 20.61 | 2.18 |
| PV | BV | BV | 97.09 | 3.09 | 96.83 | 0.89 | 0.89 | 97.70 | 0.53 |
| PV | PV | PV | 97.02 | 18.05 | 89.64 | 2.30 | 8.16 | 84.22 | 1.95 |
| CG2.5 | BV | BV | 96.57 | 67.30 | 61.73 | 40.84 | 26.02 | 29.63 | 3.51 |
| PV | BV | BV | 97.23 | 1.91 | 95.68 | 1.24 | 0.00 | 98.76 | 0.00 |
| PV | PV | PV | 96.65 | 19.61 | 91.51 | 3.01 | 10.82 | 84.22 | 1.95 |
- 현존하는 벤치마크는 실제 설정에서 코드 LM의 취약점 탐지 성능을 과대 평가한다.
- PrimeVul는 6,968개의 취약 함수와 228,800개의 정상 함수가 140개의 CWE로 구성되어 있으며, 수동 벤치마크에 필적하는 높은 라벨링 정확도를 보인다.
- 코드 LMs는 PrimeVul에서 평가될 때 상당한 성능 차이를 보인다(예: BigVul에서 F1 68.26%를 기록한 모델이 PrimeVul에서 3.09% F1로 감소).
- 고급 학습 기법은 미미한 이득만을 가져오며, GPT-3.5 및 GPT-4의 결과는 엄격한 설정에서 신뢰할 만한 우수성을 보이지 않으며 무작위 추측에 가깝다.
- 새로운 평가 지표(VD-S)와 페어드 함수 평가가 전통적인 정확도/F1 지표로는 포착되지 않는 취약점을 드러낸다.
- 연대순 데이터 분할은 누출을 완화하고 실제 세계의 모델 배포 제약을 더 잘 반영한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.