[논문 리뷰] We're Different, We're the Same: Creative Homogeneity Across LLMs
연구는 광범위한 LLM과 인간의 창의적 산출물을 표준화된 창의성 테스트를 사용해 비교하고, LLM 응답이 인간 응답에 비해 모델 간에 현저히 더 균질하다는 것을 발견한다.
Numerous powerful large language models (LLMs) are now available for use as writing support tools, idea generators, and beyond. Although these LLMs are marketed as helpful creative assistants, several works have shown that using an LLM as a creative partner results in a narrower set of creative outputs. However, these studies only consider the effects of interacting with a single LLM, begging the question of whether such narrowed creativity stems from using a particular LLM -- which arguably has a limited range of outputs -- or from using LLMs in general as creative assistants. To study this question, we elicit creative responses from humans and a broad set of LLMs using standardized creativity tests and compare the population-level diversity of responses. We find that LLM responses are much more similar to other LLM responses than human responses are to each other, even after controlling for response structure and other key variables. This finding of significant homogeneity in creative outputs across the LLMs we evaluate adds a new dimension to the ongoing conversation about creativity and LLMs. If today's LLMs behave similarly, using them as a creative partners -- regardless of the model used -- may drive all users towards a limited set of "creative" outputs.
연구 동기 및 목표
- LLMs가 집단으로서 인간에 비해 창의적 산출물에서 더 많거나 더 적거나 비슷한 변이를 보이는지 평가한다.
- 여러 모델 계열과 프롬프트에 걸쳐 교차-LLM 동질성이 지속되는지 결정한다.
- LLM 및 인간의 창의적 산출물에서 콘텐츠 유사성과 구조적 유사성을 구분한다.
제안 방법
- 표준화된 창의성 테스트(AUT, Forward Flow, DAT)를 사용하여 인간 및 7개 이상 다양한 LLM으로부터 창의적 응답을 이끌어낸다.
- 원효 임베딩(GloVe)과 코사인 거리 기반으로 개별 Originality를 계산하여 참신함을 정량화한다.
- 모든 쌍 코사인 거리 기반의 임베딩 응답의 의미론적 유사성을 통해 인구 규모의 변동성을 측정한다.
- Originality 및 변이 차이에 대해 Welch의 t-검정을 사용하여 p < 0.01로 LLM과 인간을 비교한다.
- AUT 프롬프트의 여러 버전을 테스트하고, 단어 길이/배포를 필터링하여 응답 구조를 제어한다.
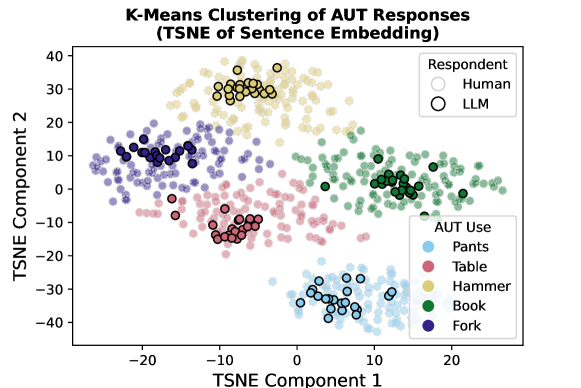
- TSNE 시각화 및 군집화를 통해 변동성 발견을 뒷받침한다.
실험 결과
연구 질문
- RQ1LLMs와 인간은 AUT, Forward Flow, 및 DAT에서 창의적 산출물의 평균 Originality에서 차이가 있는가?
- RQ2동일한 프롬프트에 응답할 때 LLM의 응답이 인간의 응답보다 모델 간에 더 균질한가?
- RQ3다른 모델 계열로 제한하거나 프롬프트 구조를 조정할 때 교차-LLM 동질성은 지속되는가?
- RQ4프롬프트 엔지니어링이 LLM의 창의성과 변동성을 완화하거나 반대로 바꿀 수 있는가?
주요 결과
- LLMs는 AUT 및 DAT Originality에서 인간보다 약간 우수한 경향을 보이며, 반면 Forward Flow에서는 인간이 LLM보다 약간 우수하게 나타난다.
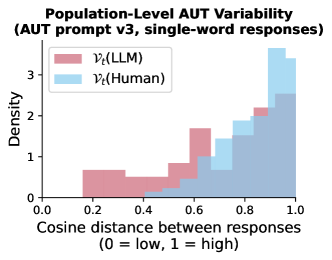
- 여러 테스트에 걸쳐 LLM은 인간에 비해 응답의 인구 수준 변동성이 유의하게 더 낮아, 보다 동질적인 산출물을 보인다.
- 프롬프트 엔지니어링은 LLM의 창의성과 변동성에 영향을 줄 수 있지만, 인간은 전반적으로 더 변동성이 큰 편이며, 한 단어로 된 AUT 응답에서도 LLM의 변동성이 감소한다.
- 단어 중복 분석은 LLM이 응답 간에 더 많은 어휘적 내용을 공유한다는 것을 보여주어 의미적 유사성 증가에 기여한다.
- 대조 분석은 AUT 응답 구조를 고려하고 모델 계열 간 비교를 수행해도 동질성이 유지됨을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.