[논문 리뷰] WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
이 논문은 WebFace260M(4M 정체성, 260M 얼굴)과 CAST 정리를 통해 정리된 대응물 WebFace42M(2M 정체성, 42M 얼굴), 그리고 FRUITS 시간 제약 평가를 도입하여 백만 규모의 얼굴 인식과 분산 학습을 연구한다.
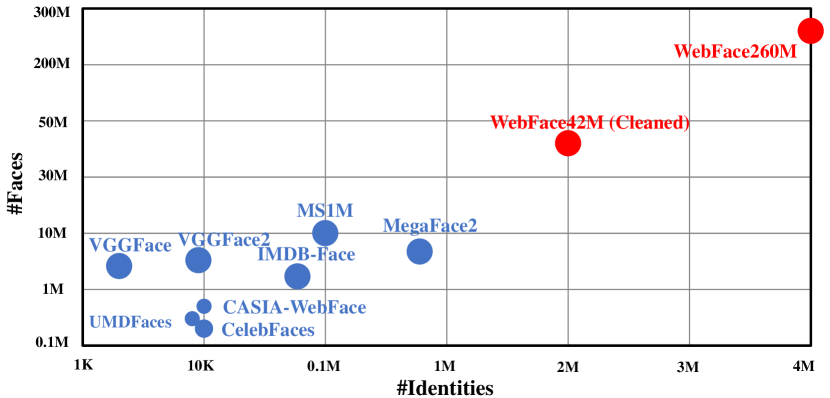
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.
연구 동기 및 목표
- 얼굴 인식에서 학계와 산업계 간의 데이터 격차를 백만 규모의 학습 데이터로 해소하기 위해
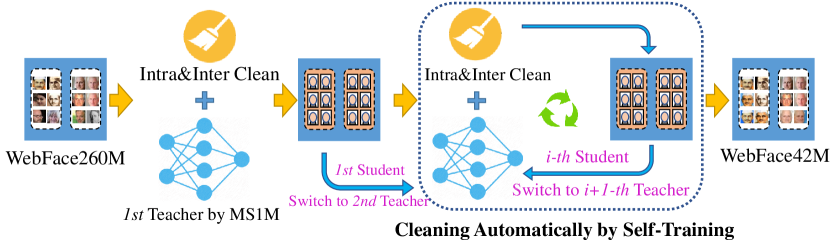
- 노이즈가 많은 웹 데이터로부터 고품질 학습 세트를 생성하기 위한 확장 가능한 자동 정리 파이프라인(CAST)을 개발한다.
- 실제 배포 시나리오를 반영하기 위한 FRUITS(시간 제약 평가 프로토콜)와 풍부한 속성 테스트 세트를 제안한다.
- 대형 및 경량 백본 모두에 대해 백만 규모의 학습과 분산 학습의 이점을 입증한다.
- FRUITS 프로토콜 하에서 다양한 아키텍처에 대한 포괄적 벤치마크를 제공하여 향후 연구를 이끈다.
제안 방법
- 4M 명의 유명인 이름 목록을 수집하고 웹에서 260M장의 이미지를 다운로드한다.
- CAST(Cleaning Automatically via Self-Training) 파이프라인을 사용하여 WebFace260M을 정리해 WebFace42M을 얻는다.
- 대용량 데이터에서 거의 선형 가속을 달성하기 위해 분산 프레임워크로 모델을 학습한다.
- 100/500/1000 ms 트랙과 풍부한 속성 테스트 세트를 갖춘 FRUITS(Face Recognition Under Inference Time conStraint)를 설계한다.
- FRUITS와 표준 벤치마크에서 ResNet-100, ResNet-14와 같은 다양한 백본 및 CosFace, ArcFace, CurricularFace와 같은 손실 함수를 평가한다.
실험 결과
연구 질문
- RQ1시간 제약 평가에서 학습 데이터의 규모(WebFace260M 대 WebFace42M 및 하위 집합)가 인식 성능에 어떤 영향을 미치는가?
- RQ2CAST가 대규모 노이즈웹 데이터 정리에 의해 고품질 얼굴 인식 학습에 얼마나 효과적인가?
- RQ3FRUITS하에서 대형 및 경량 네트워크 모두에서 백만 규모 학습으로 달성 가능한 성능 향상은 무엇인가?
- RQ4분산 학습이 백만 규모 얼굴 인식을 위한 data 및 compute 격차를 학계와 산업계 간에 얼마나 좁힐 수 있는가?
- RQ5공공 데이터세트와 비교했을 때 WebFace42M은 IJB-C, NIST-FRVT와 같은 도전적 벤치마크에서 어떻게 성능을 보이는가?
주요 결과
- WebFace42M은 표준 ResNet-100 구성에서 IJB-C에서 TAR@FAR=1e-4가 97.70%에 달하며, 공공 SOTA에 비해 오차율을 약 40% 감소시킨다.
- WebFace4M(WebFace42M의 10%)를 사용하면 MS1M 계열이나 MegaFace2와 같은 공개 학습 세트에 비해 이미 우수한 성능을 얻는다.
- WebFace42M은 NIST-FRVT에서 430개 항목 중 3위를 차지하며, 시간 제약 벤치마크에 대한 백만 규모 데이터의 경쟁력을 입증한다.
- WebFace42M은 현재까지 공개된 정리된 학습 세트 중 가장 큰 규모를 제공하여 대형 및 경량 모델 모두에서 상당한 개선을 가능하게 한다.
- 혼합 정밀도 및 특징/센터 병렬화를 활용한 분산 학습은 최소한의 성능 손실로 거의 선형 가속(예: 최대 32 노드)을 달성한다.
- FRUITS 하에서 경량에서 중량급까지 다양한 베이스라인이 의미 있는 격차와 개선 여지를 보이며, 특히 FRUITS-100(경량)과 FRUITS-1000(중량급) 트랙에서 그렇다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.