[논문 리뷰] What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring
본 논문은 ML 칩에서 가중치 스냅샷 로깅, 트랜스크립트 계보 추적, 공급망 모니터링을 통해 대규모 ML 학습 규칙을 검증하는 하드웨어-소프트웨어 모니터링 프레임워크를 제안합니다. 이를 통해 독점 데이터를 노출하지 않고도 규칙 위반 학습 런을 높은 확률로 탐지할 수 있습니다.
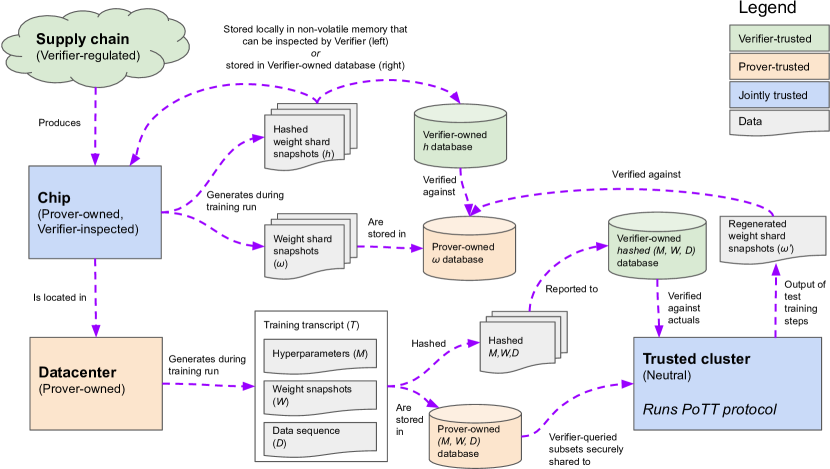
As advanced machine learning systems' capabilities begin to play a significant role in geopolitics and societal order, it may become imperative that (1) governments be able to enforce rules on the development of advanced ML systems within their borders, and (2) countries be able to verify each other's compliance with potential future international agreements on advanced ML development. This work analyzes one mechanism to achieve this, by monitoring the computing hardware used for large-scale NN training. The framework's primary goal is to provide governments high confidence that no actor uses large quantities of specialized ML chips to execute a training run in violation of agreed rules. At the same time, the system does not curtail the use of consumer computing devices, and maintains the privacy and confidentiality of ML practitioners' models, data, and hyperparameters. The system consists of interventions at three stages: (1) using on-chip firmware to occasionally save snapshots of the the neural network weights stored in device memory, in a form that an inspector could later retrieve; (2) saving sufficient information about each training run to prove to inspectors the details of the training run that had resulted in the snapshotted weights; and (3) monitoring the chip supply chain to ensure that no actor can avoid discovery by amassing a large quantity of un-tracked chips. The proposed design decomposes the ML training rule verification problem into a series of narrow technical challenges, including a new variant of the Proof-of-Learning problem [Jia et al. '21].
연구 동기 및 목표
- 고급 ML의 거버넌스를 촉진하기 위해 학습 규칙의 정부 검증을 가능하게 한다.
- 칩, 데이터 센터, 공급망에 걸친 3단 모니터링 프레임워크를 제안한다.
- 학습 데이터와 모델의 기밀성을 보장하면서도 고확률 규칙 탐지를 가능하게 한다.
- 이러한 검증 시스템의 실현 가능성, 한계 및 도전과제를 평가한다.
제안 방법
- 하드웨어가 보증하는 펌웨어 attestations로 고정된 스냅샷 로깅을 칩 내 가중치 샤드에 연결한다.
- 가중치 스냅샷 해시와 대응하는 학습 트랜스크립트를 전송하도록 요구하여 출처를 증명한다(Proof-of-Learning에 기반한 프로토콜).
- 추적되지 않는 칩 은폐를 방지하기 위한 공급망 소유권 검증을 구현한다.
- 표본 크기 및 계산 매개변수를 바탕으로 규칙 위반 학습 런을 잡아낼 확률적 guarantees를 유도한다.
- 다양한 규모 하에서 과거 및 미래 모델에 필요한 점검을 추정하는 정량적 표를 제공한다.
실험 결과
연구 질문
- RQ1확인자가 ML 학습 규칙 위반을 높은 확률로 탐지하기 위해 요구할 수 있는 최소한의 검증 가능 조작은 무엇인가?
- RQ2칩 수준 로깅, 학습 트랜스크립트, 공급망 모니터링을 어떻게 결합하여 robust한 컴플라이언스 증명을 제공할 수 있는가?
- RQ3대규모 규칙 위반 런을 잡아내는 데 필요한 실용적 샘플 크기와 점검 빈도는 무엇인가?
- RQ4이 모니터링 접근법으로 어떤 규칙(계산, 데이터 특성, 하이퍼파라미터, 성능 임계치)을 강제할 수 있는가?
- RQ5제안된 프레임워크의 확장성 및 보안 한계는 무엇인가?
주요 결과
- 샘플링 기반 프레임워크는 칩의 부분 샘플을 검사하고 가중치 샷 해시를 학습 트랜스크립트와 대조함으로써 규칙 위반 학습 런을 높은 확률로 탐지할 수 있다.
- 다양한 모델과 칩 수에 대해 연간 필요한 샘플 수를 정량적으로 추정한 결과를 제공하며, 모델 규모에 따른 확장성을 보여준다.
- 가중치 샤드 스냅샷과 해시된 출처 정보는 독점 데이터나 가중치를 노출하지 않고도 소급 검증을 가능하게 한다.
- 공급망 모니터링은 추적되지 않은 칩이 대형 학습 런을 숨기지 못하도록 하는 데 필수적이다.
- 이 접근법은 특수 가속기에서의 대규모 학습에 주로 실현 가능하며, 구형 칩 및 비중심 계산에는 한계가 있다.
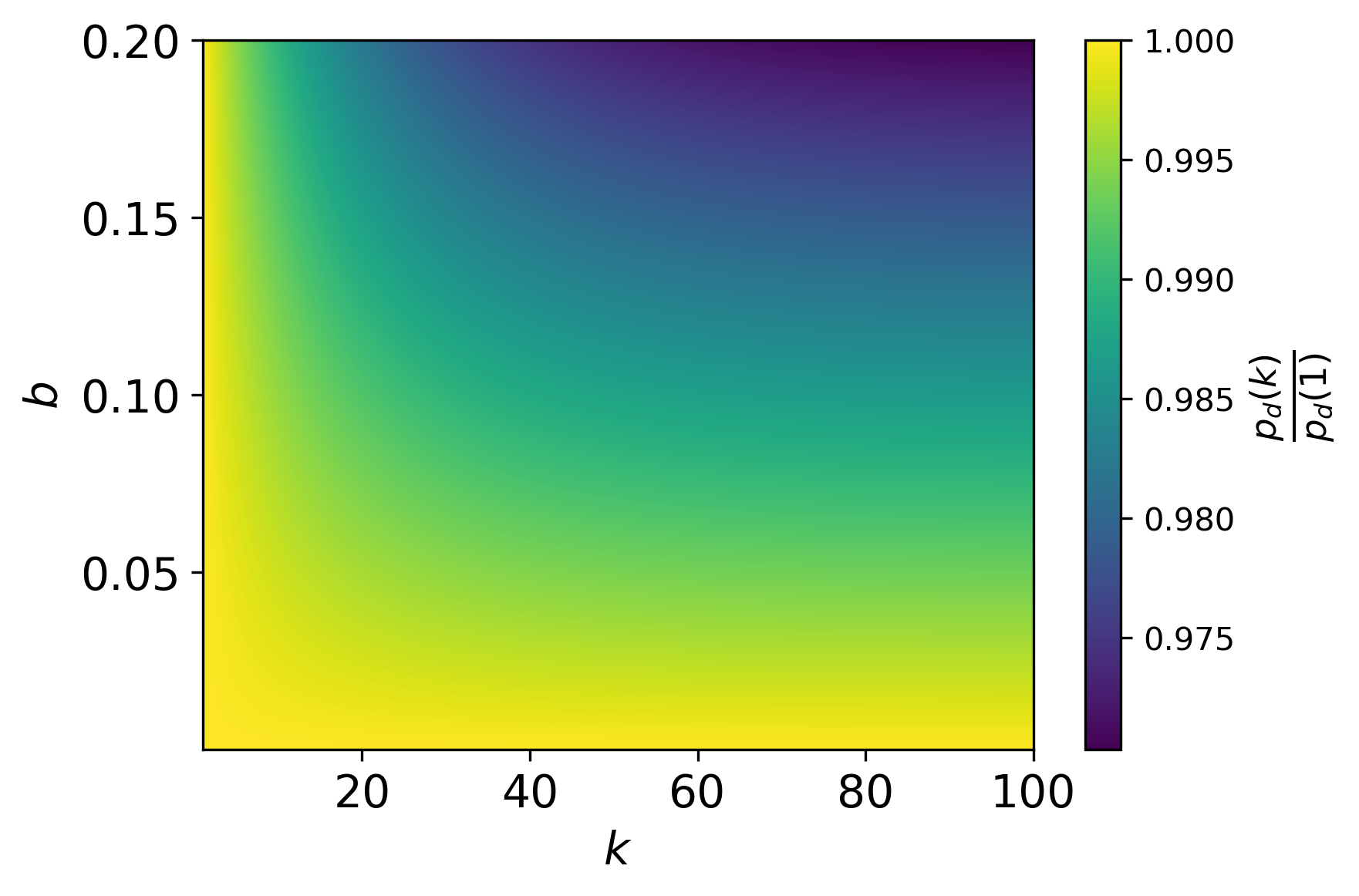
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.