[논문 리뷰] What matters when building vision-language models?
이 논문은 비전-언어 모델 설계 선택(아키텍처, 백본, 데이터, 학습)에 대한 제어된 제거실험을 수행하고, Idefics2를 도입하며, 8B 파라미터 VLM이 추론 효율성으로 강력한 성능을 달성함.
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
연구 동기 및 목표
- 제어된 조건에서 백본의 품질(비전 및 언어)이 VLM 성능에 미치는 영향을 평가한다.
- 완전 자동회귀(fully autoregressive)와 교차 주의 융합 아키텍처를 비교하고, 파라미터 효율적 미세조정에서의 안정성을 평가한다.
제안 방법
- 제어된 설정에서 아키텍처, 백본 및 데이터의 체계적 제거실험.
- VQAv2, TextVQA, OKVQA, COCO에 걸친 6k 스텝 벤치마크를 사용하여 4샷 성능을 측정한다.
- OBELICS, 이미지-텍스트, PDF 데이터에 대한 다단계 사전 학습으로 Idefics2(8B 파라미터)를 개발/훈련한 뒤, 지시 튜닝과 채팅 스타일 얼라인먼트를 수행한다.
실험 결과
연구 질문
- RQ1고정된 파라미터 예산에서 어떤 사전 학습된 단일 모달 백본이 VLM을 가장 잘 지원하는가?
- RQ2백본을 학습/언프리징할 때, 완전 자동회귀 아키텍처와 교차 주의 융합 아키텍처는 어떻게 비교되는가?
- RQ3시각 토큰 수를 줄이고 종횡비를 유지하면서 성능을 해치지 않고 효율성을 높일 수 있는가?
- RQ4이미지 분할 및 서브 이미지 학습이 다운스트림 이득을 위해 계산량과 트레이드오프를 발생시키는가, 특히 OCR가 많은 과제에서?
주요 결과
| 모델 | 크기 | 아키 | 이미지당 토큰 수 | VQAv2 | TextVQA | OKVQA | COCO |
|---|---|---|---|---|---|---|---|
| OpenFlamingo | 9B | CA | - | 54.8 | 29.1 | 41.1 | 96.3 |
| Idefics1 | 9B | CA | - | 56.4 | 27.5 | 47.7 | 97.0 |
| Flamingo | 9B | CA | - | 58.0 | 33.6 | 50.0 | 99.0 |
| MM1 | 7B | FA | 144 | 63.6 | 46.3 | 51.4 | 116.3 |
| Idefics2-base | 8B | FA | 64 | 70.3 | 57.9 | 54.6 | 116.0 |
- 언어-model 백본의 품질이 고정된 파라미터 수에서 시각 백본의 품질보다 VLM 성능에 더 큰 영향을 미친다.
- 백본이 학습 가능한 경우 학습된 파라미터 효율적 미세조정이 있는 완전 자동회귀 아키텍처가 교차 주의력보다 우수할 수 있으며, 백본이 고정되면 교차 주의력이 승리할 수 있다.
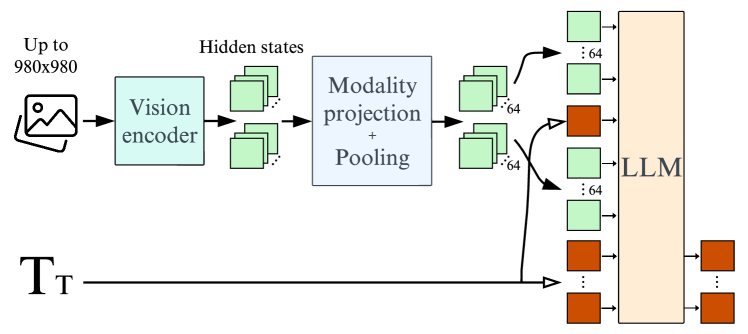
- 퍼시øver(style) 풀링을 사용해 시각 토큰을 수백 개에서 64개로 줄이면 학습과 추론 효율이 모두 개선되고 다운스트림 성능도 향상된다.
- 적응 가능한 비전 인코더로 이미지 종횡비와 해상도를 보존하면 성능을 유지하면서 학습 및 추론 속도를 높일 수 있다.
- 학습 중 이미지를 서브 이미지로 분할하는 것이 다운스트림 성능을 향상시키며, 특히 텍스트 읽기가 필요한 작업(OCR)에서 두드러진다.
- Idefics2는 크기에 비해 최첨단 또는 경쟁력 있는 결과를 달성하며, 종종 더 큰 모델에 버금가고 OCR/텍스트 읽기 능력을 향상시키며, base, instructed, chat 변형의 오픈 릴리스를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.