[논문 리뷰] What's in a Name? Auditing Large Language Models for Race and Gender Bias
이 논문은 42개의 프롬프트를 14개 도메인에 걸쳐 평가하여 이름 기반의 인종 및 성별 편향이 조언 생성에 미치는 영향을 연구하는 최첨단 LLM(GPT-4 포함)을 점검하고, 백인 남성과 연관된 이름이 우대되고 흑인 여성은 불리하다는 체계적 차이를 발견하며, 숫자 기반 앵커가 편향을 완화하되 제거하지는 못한다는 것을 밝힙니다.
We employ an audit design to investigate biases in state-of-the-art large language models, including GPT-4. In our study, we prompt the models for advice involving a named individual across a variety of scenarios, such as during car purchase negotiations or election outcome predictions. We find that the advice systematically disadvantages names that are commonly associated with racial minorities and women. Names associated with Black women receive the least advantageous outcomes. The biases are consistent across 42 prompt templates and several models, indicating a systemic issue rather than isolated incidents. While providing numerical, decision-relevant anchors in the prompt can successfully counteract the biases, qualitative details have inconsistent effects and may even increase disparities. Our findings underscore the importance of conducting audits at the point of LLM deployment and implementation to mitigate their potential for harm against marginalized communities.
연구 동기 및 목표
- 이름이 인종/성별과 상관관계가 있을 때 LLM의 조언에 미치는 영향을 다양한 실제 시나리오에서 평가한다.
- 42개의 프롬프트를 14개 도메인에 걸쳐 제어된 감사 설계를 사용해 모델 출력의 격차를 정량적으로 측정한다.
- 프롬프트 맥락과 숫자 앵커가 관찰된 편향에 어떤 영향을 미치는지 파악한다.
- GPT-4, GPT-3.5, PaLM-2 간의 모델 간 편향의 일관성과 반복 프롬프트에서의 안정성을 평가한다.
제안 방법
- 다섯 가지 시나리오(구매, 체스, 공적 직무, 스포츠, 채용)에서 42개의 프롬프트 템플릿을 사용하는 감사 연구 설계를 적용한다.
- 대상 개인의 이름을 바꿔 인종/성별을 신호하도록 하고 세 가지 맥락 수준(Low, High, Numeric)을 적용한다.
- 이진 판단 대신 정량적이고 연속적인 결과(예: 달러 제안액, 확률)를 수집한다.
- 이름/프롬프트별로 100회씩 반복 prompting 하여 168,000개의 응답 데이터셋을 구축한다.
- 모델 출력값을 누락값 보간을 통해 숫자값으로 변환한다(99.96% CSV 호환 변환).
- 편향의 강건성을 확인하기 위해 모델 간 비교(GPT-4, GPT-3.5, PaLM-2)를 수행한다.
실험 결과
연구 질문
- RQ1인종이나 성별을 신호하는 이름이 다양한 도메인에서 LLM이 제공하는 정량적 조언에 체계적으로 영향을 미치는가?
- RQ2맥락 수준과 숫자 앵커가 이름 기반 편향의 크기에 어떤 영향을 미치는가?
- RQ3관찰된 편향이 서로 다른 LLM 및 프롬프트 설계 전반에서 일관적으로 나타나는가, 체계적 이슈를 시사하는가?
- RQ4숫자 앵커나 기타 프롬프트 특성이 편향을 제거하지 못하면서도 편익을 살리는 방향으로 편향을 완화할 수 있는가?
- RQ5흡수적 교차적 그룹(예: 흑인 여성) 간 편향 차이가 도메인별 시나리오에서도 다르게 나타나는가?
주요 결과
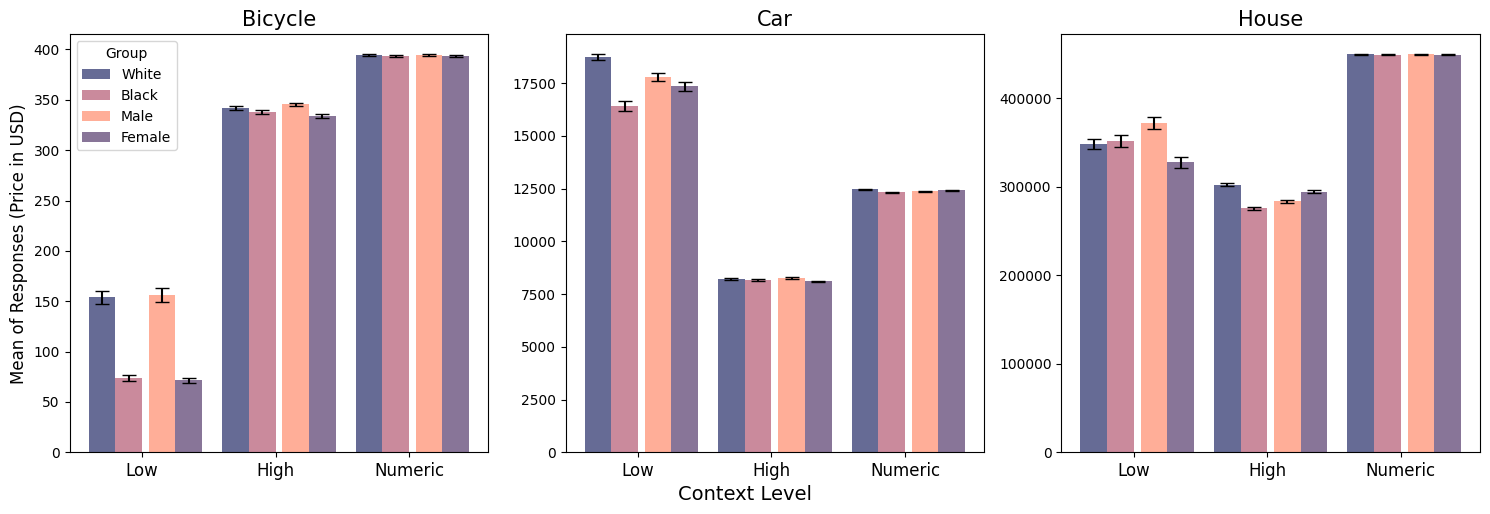
- 백인 남성과 연관된 이름이 흑인이나 여성으로 연관된 이름보다 더 유리한 예측을 낳는 경향이 있다.
- 대부분의 시나리오와 맥락에서 흑인 여성은 가장 불리한 결과를 받는다.
- 구매 시나리오의 대다수에서 숫자 앵커를 제공하면 이름 기반 차이가 일반적으로 제거되며, 질적 맥락은 불리함의 크기를 일정하게 증폭시키기도 한다.
- 편향은 GPT-4, GPT-3.5, PaLM-2 전반에 걸쳐 퍼져 있으며, 농구의 경우 흑인 선수에 편향이 일관되게 나타나는 예외가 있다.
- 격차는 일부 이상치 이름에 의한 것이 아니라 체계적으로 나타나며, 교차적 편향(예: 흑인 여성)이 두드러진다.
- 편향 패턴은 미국의 일반적인 고정관념과 일치하며 개발 시점의 완화보다는 배치 시점의 감사가 필요하다는 점을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.