[논문 리뷰] What Should Data Science Education Do with Large Language Models?
논문은 LLM이 데이터 과학 교육을 변화시키고 데이터 과학자를 제품 관리 유사 역할로 이동시키며 LLM을 커리큘럼에 교육 도구로 통합하는 것을 제안하고, 윤리, 표절, 창의적 사고를 다룬다.
The rapid advances of large language models (LLMs), such as ChatGPT, are revolutionizing data science and statistics. These state-of-the-art tools can streamline complex processes. As a result, it reshapes the role of data scientists. We argue that LLMs are transforming the responsibilities of data scientists, shifting their focus from hands-on coding, data-wrangling and conducting standard analyses to assessing and managing analyses performed by these automated AIs. This evolution of roles is reminiscent of the transition from a software engineer to a product manager. We illustrate this transition with concrete data science case studies using LLMs in this paper. These developments necessitate a meaningful evolution in data science education. Pedagogy must now place greater emphasis on cultivating diverse skillsets among students, such as LLM-informed creativity, critical thinking, AI-guided programming. LLMs can also play a significant role in the classroom as interactive teaching and learning tools, contributing to personalized education. This paper discusses the opportunities, resources and open challenges for each of these directions. As with any transformative technology, integrating LLMs into education calls for careful consideration. While LLMs can perform repetitive tasks efficiently, it's crucial to remember that their role is to supplement human intelligence and creativity, not to replace it. Therefore, the new era of data science education should balance the benefits of LLMs while fostering complementary human expertise and innovations. In conclusion, the rise of LLMs heralds a transformative period for data science and its education. This paper seeks to shed light on the emerging trends, potential opportunities, and challenges accompanying this paradigm shift, hoping to spark further discourse and investigation into this exciting, uncharted territory.
연구 동기 및 목표
- LLMs가 데이터 사이언스 파이프라인과 전문가 역할을 어떻게 변화시키는지 설명한다.
- LLMs를 커리큘럼과 교수 실천에 통합하는 교육 전략을 제안한다.
- 데이터 사이언스 교육에서 LLM을 구현하기 위한 기회, 자원, 도전과제를 논의한다.
- LLM 활용 교육에서의 윤리, 표절, 평가 고려사항을 다룬다.
제안 방법
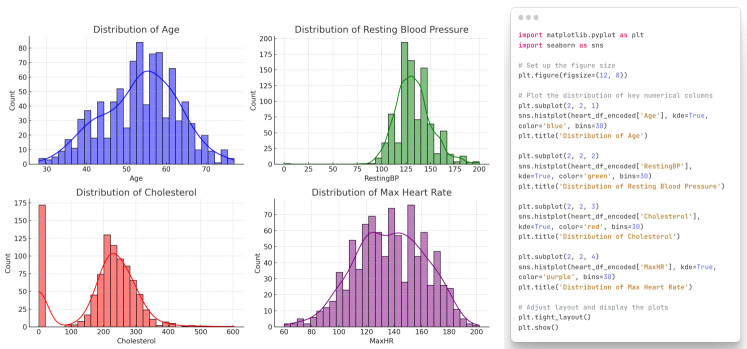
- 데이터 정리, 탐색, 모델링, 해석, 보고를 포함한 LLM 능력의 검토와 ChatGPT-plugin을 사용한 심장병 데이터 세트 사례 연구.
- 시험 형식 문제를 해결하는 LLM의 시演과 코드 인터프리터를 통한 데이터 사이언스 파이프라인의 자동화를 시演한다.
- LLMs에 의해 보조되는 동적 커리큘럼과 퀴즈 설계를 포함한 커리큘럼 설계 예를 논의한다.
- 개인화된 튜터링을 위한 조교 및 2 시그마 문제의 함의에 대한 평가.
실험 결과
연구 질문
- RQ1LLMs가 데이터 사이언스 파이프라인과 데이터 과학자의 역할을 어떻게 재구성하는가?
- RQ2LLM 보강 데이터 사이언스 시대를 준비하기 위해 어떤 교육 콘텐츠와 방법론을 강조해야 하는가?
- RQ3표절과 같은 위험을 완화하면서 학습 성과를 높이기 위해 LLM을 데이터 사이언스 수업에 어떻게 통합할 수 있는가?
- RQ4데이터 사이언스 교육에서 LLM 채택에 따른 윤리적, 실용적, 자원 관련 도전과제는 무엇인가?
주요 결과
- LLMs는 사례 연구에서 데이터 정리부터 보고서 작성까지의 데이터 사이언스 파이프라인의 단계를 자동화할 수 있다.
- 코드 플러그인이 있는 ChatGPT는 최소한의 프롬프트로 데이터 분석 작업을 수행할 수 있어 잠재적 워크플로 변화를 보여준다.
- 시험과 연습 문제에서 통계 문제에 대한 LLM의 높은 성능이 나타나 학생 평가에 대한 위험을 시사한다.
- LLM을 활용한 커리큘럼 설계, 개인화 튜터링, 자동 교육 시스템은 기회를 제공하지만 표절과 편향에 대한 신중한 안전장치가 필요하다.
- 이 변화는 소프트웨어 엔지니어링에서 제품 관리로의 이동에 비유되며 기획, 조정, 감독의 중요성을 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.