[논문 리뷰] When Do Graph Neural Networks Help with Node Classification? Investigating the Impact of Homophily Principle on Node Distinguishability
본 논문은 varying homophily 하에서 내부-클래스(intra-class) 및 외부-클래스(inter-class) 노드 구별성(ND)을 공동으로 연구하는 CSBM-H를 제안하고, 두 가지 ND 지표(Probabilistic Bayes Error 및 음의 일반화 제프리 발산)를 제시하며, 그래프 필터와 차수 분포가 ND에 미치는 영향을 분석하고, 기존의 동질성 지표를 넘어 GNN의 우월성을 예측하기 위한 분류기 기반 성능 지표(CPM)를 제안한다.
Homophily principle, i.e., nodes with the same labels are more likely to be connected, has been believed to be the main reason for the performance superiority of Graph Neural Networks (GNNs) over Neural Networks on node classification tasks. Recent research suggests that, even in the absence of homophily, the advantage of GNNs still exists as long as nodes from the same class share similar neighborhood patterns. However, this argument only considers intra-class Node Distinguishability (ND) but neglects inter-class ND, which provides incomplete understanding of homophily on GNNs. In this paper, we first demonstrate such deficiency with examples and argue that an ideal situation for ND is to have smaller intra-class ND than inter-class ND. To formulate this idea and study ND deeply, we propose Contextual Stochastic Block Model for Homophily (CSBM-H) and define two metrics, Probabilistic Bayes Error (PBE) and negative generalized Jeffreys divergence, to quantify ND. With the metrics, we visualize and analyze how graph filters, node degree distributions and class variances influence ND, and investigate the combined effect of intra- and inter-class ND. Besides, we discovered the mid-homophily pitfall, which occurs widely in graph datasets. Furthermore, we verified that, in real-work tasks, the superiority of GNNs is indeed closely related to both intra- and inter-class ND regardless of homophily levels. Grounded in this observation, we propose a new hypothesis-testing based performance metric beyond homophily, which is non-linear, feature-based and can provide statistical threshold value for GNNs' the superiority. Experiments indicate that it is significantly more effective than the existing homophily metrics on revealing the advantage and disadvantage of graph-aware modes on both synthetic and benchmark real-world datasets.
연구 동기 및 목표
- 동일-클래스 간 및 상이-클래스 간 거리 모두를 고려하여 동질성이 노드 구별성에 미치는 영향을 포괄적으로 이해하려는 동기 부여.
- 노드 구별성(ND)을 연구하기 위해 동질성, 클래스 분산, 노드 차수를 명시적으로 도입하는 그래프 생성 모델 CSBM-H를 제안.
- CSBM-H에서 ND를 정량화하기 위해 Probabilistic Bayes Error 및 음의 일반화 제프리 발산(D_NGJ)을 정의하고 계산한다.
- 그래프 필터(LP, FP, HP)와 차수 분포가 ND에 미치는 영향을 분석하고 중간 동질성 함정(mid-homophily pitfall)을 식별한다.
- 비선형적이고 특징 기반의 성능 지표 CPM을 제안하고 평가하여 그래프 인식 모델이 그래프 비의존적 모델보다 우수한지를 예측한다.
제안 방법
- CSBM-H를 명시적 동질성 매개변수 h와 클래스 분산 σ0^2, σ1^2를 갖는 두-클래스 맥락적 블록모형으로 도입한다.
- CSBM-H에 대한 베이즈 분류기를 도출하고 결정 경계를 Q(x)로 표현하며 매개변수 a, b, c를 사용한다.
- 일반화된 카이제곱 분포를 사용하는 Q(x)를 이용해 ND를 정량화하는 Probabilistic Bayes Error(PBE)를 정의한다.
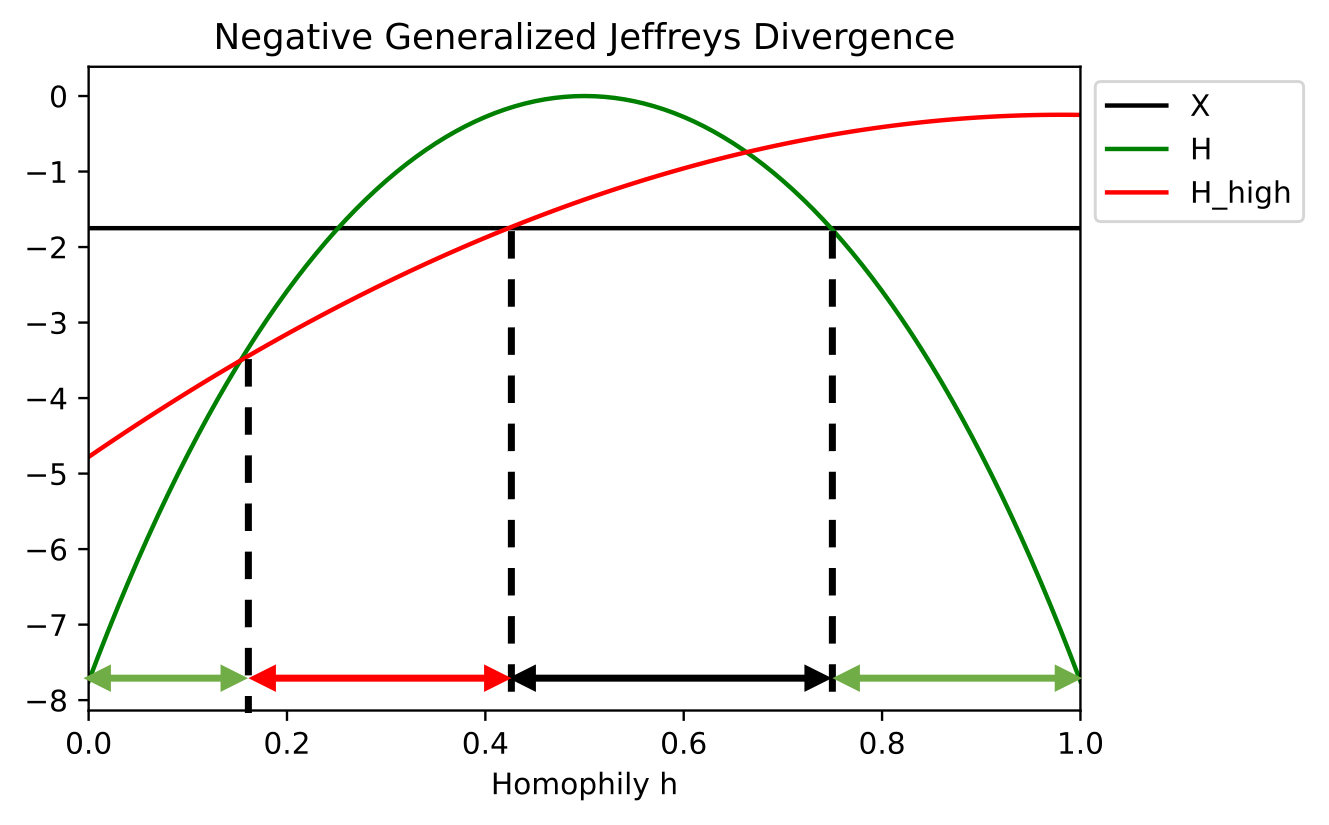
- ND를 ENND 및 NVR 항으로 분해하기 위해 음의 일반화 제프리 발산 D_NGJ(CSBM-H)를 정의한다.
- LP(A_rw), 완전 통과 및 HP(I - A_rw) 필터링된 특징이 해석적 표현과 제거 연구를 통해 ND에 미치는 영향을 보여준다.
- 가설검정 임계치를 사용하는 Classifier-based Performance Metric(CPM)을 제안하여 GNN의 우월성을 예측한다.
실험 결과
연구 질문
- RQ1노드 분류에서 GNN의 효과를 좌우하는 intra-class ND와 inter-class ND의 상호 작용은 무엇인가?
- RQ2그래프 필터에 따라 동질성 수준, 클래스 분산, 노드 차수가 ND를 어떻게 형성하는가?
- RQ3비선형적이고 특징 기반의 지표(CPM)가 전통적인 동질성 지표를 넘어 그래프 인식 모델의 이점을 임계치로 구분할 수 있는가?
- RQ4LP, FP, HP 그래프 필터가 다양한 동질성 체계에서 ND에 어떠한 영향을 미치는가?
- RQ5실제 데이터셋은 중간 동질성(mid-homophily) 함정이 존재하여 중간 수준의 동질성이 ND나 모델 성능을 악화시키는가?
주요 결과
- ND는 intra-클래스 ND뿐만 아니라 inter-클래스 ND에도 의존하며, intra-class ND가 inter-class ND보다 작을수록 노드 분류에 더 이상적이다.
- CSBM-H 하에서 PBE와 D_NGJ(CSBM-H)는 LP-필터링된 특징에 대해 동질성에 따라 종 모양의 관계를 보이며 중간 동질성 함정이 있음을 시사한다.
- HP 필터는 이질성 영역에서 ND를 향상시키고, LP 필터는 저-가 고-동질성 체계에서 도움을 주며 FP는 중간에서 높은 동질성에서 여전히 이점을 가진다.
- 고변형 클래스 차수가 높아지면 LP 및 HP의 ND가 축소되고 FP 영역이 확장되는 등 제거 연구가 수행되었고, 저변화 클래스 차수의 증가가 미묘한 효과를 보인다.
- CPM은 가설 검정 기반의 지표로서 합성 및 실제 데이터셋에서 그래프 인식 방법이 우월할 때를 예측하는 데 전통적인 동질성 지표보다 우수하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.