[논문 리뷰] Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
이 연구는 CortexBench를 제시하며, Embodied AI를 위한 사전 학습 시각 표현의 가장 큰 평가로서 보편적인 승자가 없음을 보여준다; VC-1 (적응된 버전)가 평균적으로 가장 강하고, 작업에 맞춘 VC-1은 CortexBench 벤치마크에서 최첨단과 일치하거나 이를 능가한다.
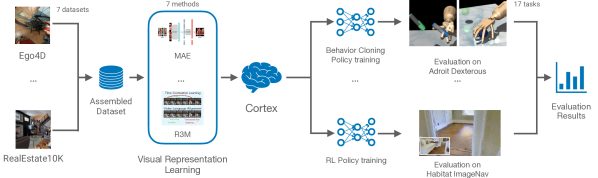
We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data size and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 4.3M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Next, we show that task- or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. Finally, we present real-world hardware experiments, in which VC-1 and VC-1 (adapted) outperform the strongest pre-existing PVR. Overall, this paper presents no new techniques but a rigorous systematic evaluation, a broad set of findings about PVRs (that in some cases, refute those made in narrow domains in prior work), and open-sourced code and models (that required over 10,000 GPU-hours to train) for the benefit of the research community.
연구 동기 및 목표
- 다양한 Embodied AI 과제에서 광범위한 사전 학습 시각 표현(PVR)을 평가하여 인공 시각 피질의 연구 필요성을 제시한다.
- 다양한 구현 형태를 가진 보행, 내비게이션, 조작 과제 전반에서 PVR을 벤치마킹하기 위해 CortexBench를 만든다.
- 데이터 규모/모델 규모의 확장이 과제 전반에 걸쳐 보편적인 이득을 가져오는지 평가한다.
- 사전 학습 데이터와 구현 태스크 간 도메인 격차를 해소하기 위한 적응 전략을 조사한다.
- 커뮤니티 벤치마킹 속도를 높이기 위해 데이터 세트, 모델, 코드를 오픈 소스로 제공한다.
제안 방법
- 항해/조작을 포괄하는 7개 Embodied AI 벤치마크에서 17개 태스크로 CortexBench를 큐레이션한다.
- 동결된 PVR 백본(CLIP, MVP, VIP, R3M)의 보편적 성능을 평가한다.
- MAE 프리트레이닝을 사용하여 네 가지 프리트레이닝 데이터셋(Ego4D 파생 및 ImageNet)에 대해 ViT-B/ViT-L 백본을 학습한다.
- 평균 성공률과 평균 순위를 평가 지표로 사용하여 CortexBench에서 성능을 측정한다.
- VC-1(모든 데이터로 학습된 가장 큰 모델)을 기존 PVR과 비교해 상대적 강점을 확립한다.
- 작업-특정 성능 향상을 위한 엔드투엔드 미세조정과 MAE 기반 적응을 통해 VC-1의 적응을 시연한다.
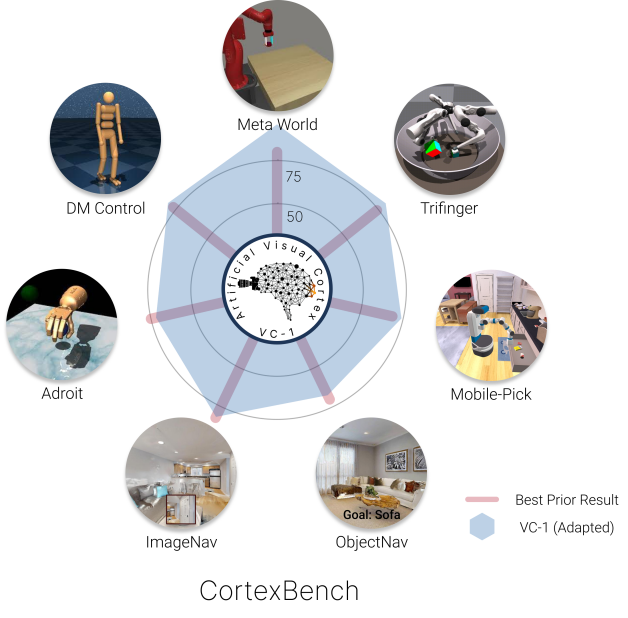
실험 결과
연구 질문
- RQ1기존의 사전 학습 시각 표현이 광범위한 Embodied AI 태스크에서 지배적인가?
- RQ2모델 크기 및 데이터세트 크기/다양성의 확장이 CortexBench 태스크의 성능에 어떤 영향을 미치는가?
- RQ3강력한 PVR의 태스크 특화 적응이 태스크-특화 최첨단 결과와의 격차를 줄이거나 능가할 수 있는가?
- RQ4엔드투엔드 미세조정 versus MAE 적응을 통한 PVR 적응이 이후 태스크에 미치는 영향은 무엇인가?
주요 결과
- 어떤 단일 사전 학습 시각 표현도 모든 CortexBench 태스크를 지배하지 못한다.
- 가장 큰 모델 VC-1(ViT-L, Ego4D+MNI에서 학습)은 평균 순위가 가장 좋고 평균 성공도도 많은 베이스라인보다 높지만 모든 태스크에서 최종 최적은 아니다.
- 데이터 세트 규모와 다양성의 확장은 평균적으로 성능을 향상시키지만 모든 태스크에서 보편적으로 향상되지는 않는다.
- VC-1의 태스크-특화 적응(VC-1 adapted)은 CortexBench 벤치마크 전반에서 경쟁력 있게 혹은 우수한 결과를 보여주며 종종 기존 최첨단을 능가한다.
- VC-1 및 VC-1 adapted가 여러 태스크의 실제 하드웨어 실험에서 선도하는 기존 PVR을 능가한다.
- 대규모 IL/RL 태스크에서 VC-1의 엔드투엔드 미세조정은 성능을 향상시키지만, few-shot imitation 도메인에서는 과적합으로 성능이 저하될 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.